Convolutional Neural Network
딥러닝 직접 구현하기 프로젝트 3-2차시: Im2col과 효율적인 Convolution 연산
* 모든 코드는 제 깃허브 (cdjs1432/DeepLearningBasic: Deep Learning from scratch)에서 확인할 수 있습니다.
이번 시간에는 Convolution 연산 (Forward, Backward)에 대해 다뤄보겠습니다.
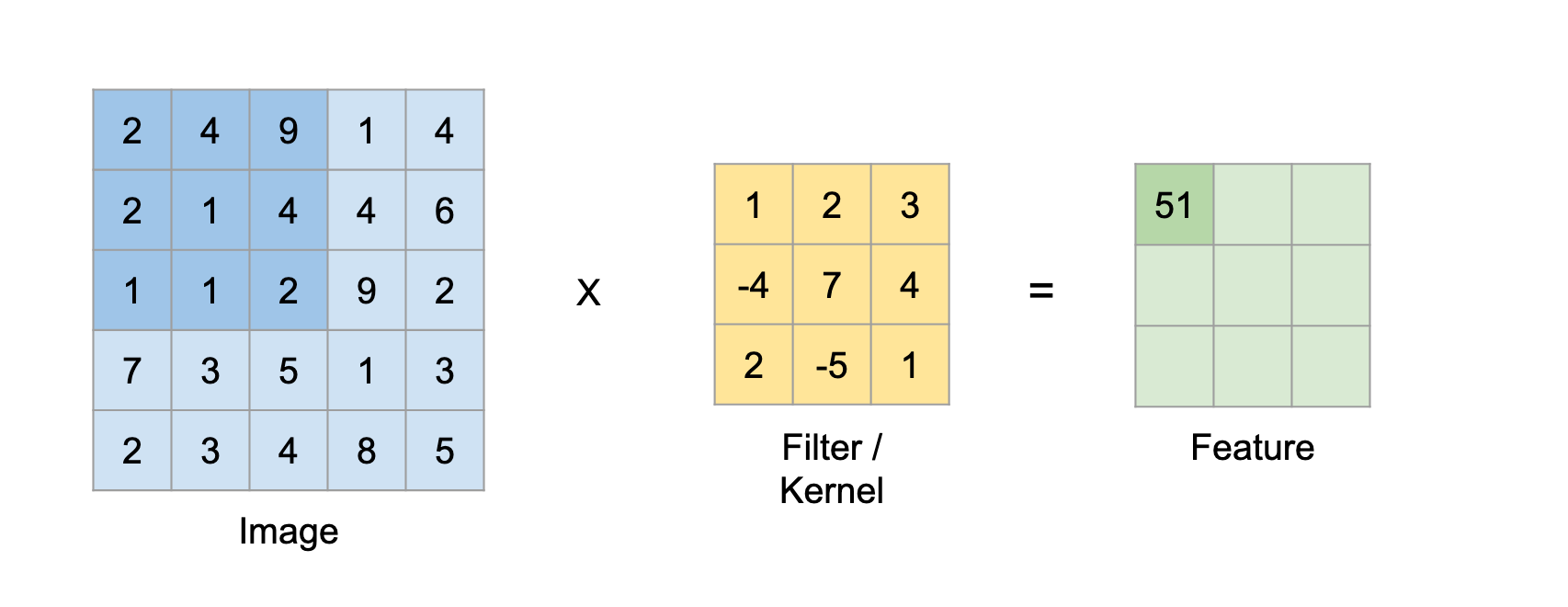
Convolution 연산은 본질은 굉장히 단순합니다. filter를 왼쪽에서 오른쪽으로, 위에서 아래로 이미지에 대고 점곱을 하면 되기 때문입니다.
하지만, 이는 생각보다 그리 단순하지 않습니다.
우선, 위의 이미지의 경우는 단순히 1장의 1-Channel 이미지의 예시이기 때문에 간단하게 대략 이미지의 크기만큼만 연산을 해 주면 됩니다.
하지만, 우리가 train할 때 사용하는 이미지는 4차원 (batch_size, channel, h, w)이므로 연산이 매우 복잡해 집니다.
예를 들어, 위의 2차원 이미지는 단순히 2중 for문으로 구현이 가능하지만, 4차원의 경우에는 4중 for문이 필요하게 됩니다.
또, 시간 복잡도도 너무 커집니다.
저번 차시에 썼던 out_h, out_w를 가져와서 설명해 보겠습니다.
간단하게 생각해서, pad=0, stride=1인 경우, out_w는 1 + w - fw가 되고, out_h는 1 + h - fh가 됩니다.
이 때, 이미지 크기 h, w에 대하여, 단 한 장의 2차원 이미지의 연산을 위해서 out_w * out_h만큼의 점곱 연산이 필요합니다.
MNIST dataset의 이미지 크기가 28*28인 것을 생각해 보면, (3, 3) 필터를 사용하였을 경우 단 한장의 이미지의 convolution을 위해서는 무려 26*26, 즉 676회의 점곱 연산이 필요합니다.
만약 50000개의 이미지 전체를 모두 Convolution 연산을 한다면, 676*50000, 즉 33,800,000회라는 무시무시한 양의 연산이 필요하게 됩니다.
만약 Convolution Layer가 두개가 겹쳐져서 Channel이 32개가 되었다면? 저 횟수의 32배를 연산해야 하는 것이죠.
게다가 컴퓨터 (또는 numpy libarary)는 점곱 연산은 아주 빠르게 수행하지만, 해당 점곱을 각각의 배열에 집어넣고 더하고... 하는 과정은 상대적으로 느리게 수행됩니다.
따라서, 점곱 연산의 횟수를 줄이는 것이 시간 복잡도와, 우리 코드의 복잡도 모두를 해결할 수 있습니다.
그렇다면 어떻게 시간 복잡도를 최적화 할 수 있을까요? 잠시 생각해 봅시다.
우선, 위 연산의 본질을 생각해 봅시다.
필터의 각각의 부분 (위 이미지에선 1, 2, 3, -4, 7, 4, 2, -5, 1)은 사실, 이미지의 특정 픽셀들과만 연산을 하게 됩니다.
가령, 필터 왼쪽 위 1은 이미지의 우측 하단 부분을 아예 연산하지 않습니다.
즉, filter의 각 부분은 애초에 이미지의 어떤 부분과 곱셈을 수행하는지 정해져 있다는 것입니다.
그렇다면, filter의 각 부분에 연산해야 할 부분만을 빼서, 각 필터와의 단 한번의 곱셈으로 바꾸면 어떨까요?
filter의 각 부분에 해당하는 부분들을 각각 배서, filter와의 점곱으로 연산을 하면 단 한번의 점곱으로 마무리 지을 수 있지 않을까요?

해당 방식을 구체화 한 것이 바로 Im2col 알고리즘입니다.
Im2col 방식은, 말 그대로 Image를 Column으로 바꾸는 알고리즘입니다.
4차원 이미지인 input image와 filter를 둘 다 2차원 행렬로 만들어서, 점곱으로 연산이 가능하게 하는 것입니다.
위 이미지를 예시로 설명하겠습니다.
위 이미지에서는 빨간색, 초록색, 파란색으로 channel을 구분하고 있습니다.
첫 번째 channel의 filter인 F0은 D0, D1, D3, D4와만 연산이 되니, 해당 이미지 값들을 빼서 하나의 Column으로 만들어 줍니다.
이 행동을 모든 filter F0, F1, F2, F3에 반복해 줍니다.
그렇게 하면 오른쪽처럼 이미지의 Column이 생성됩니다.
또, 이를 각각의 filter마다, 각각의 channel마다 반복해 주면, 행렬 두개가 만들어지게 됩니다.
(참고로, 모든 필터의 각각의 부분은 모두 동일한 부분과만 연산하므로, filter의 행렬은 filter를 reshape한 것과 동일한 결과가 나오게 됩니다.)
이 방법은 사실, 원래 단 한번씩만 등장하던 이미지의 픽셀값이 여러 번 중복되어 여러번 나타나기 때문에 공간 복잡도가 커지게 된다는 단점이 있습니다.
하지만, 그렇게 해서 낭비되는 공간보다 아낄 수 있는 시간 복잡도가 훨씬 높기에(원본 conv의 약 200배 속도), 이 방식은 자주 사용됩니다.
이제, 이 Im2col 함수를 코드로 구현해 볼까요?
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
N, C, H, W = input_data.shape
out_h = (H + 2 * pad - filter_h) // stride + 1
out_w = (W + 2 * pad - filter_w) // stride + 1
img = np.pad(input_data, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
for y in range(filter_h):
y_max = y + stride * out_h
for x in range(filter_w):
x_max = x + stride * out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N * out_h * out_w, -1)
return col코드를 살펴봅시다.
우선, input data에서 이미지의 개수, channel, 그리고 가로세로 길이를 구한 뒤 out_h, out_w를 지정해 줍니다.
그 뒤, input_data에 padding을 해 줍니다. (np.pad...)
다음으로, 이미지의 행렬을 담을 col을 ((이미지 크기, channel, filter 세로, filter 가로, out 세로, out 가로))의 크기로 만들어 줍니다.
이 크기로 만들어 주는 이유는, 어차피 모든 이미지 개수(N)와 channel(C)마다 동일한 연산을 해 줄 것이고, filter 하나의 행렬의 크기가 바로 (filter_h, filter_w)이기 때문입니다.
그리고, filter_h와 filter_w의 크기에 대하여, for loop를 돌아줍니다.
각 filter의 원소마다 연산해 줄 이미지를 추출하기 위함입니다.
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]가 바로 이미지를 추출하는 부분입니다.
y:y_max:stride는, y에서부터 y_max까지, stride식 건너뛰면서 index를 추출하라는 의미입니다.
(참고로, col의 순서를 위처럼 한 것도 이런 대입 연산이 필요하기 때문입니다.)
마지막으로, 이 column을 reshape해주기 위해 transpose해 줍니다.
이렇게 transpose하지 않으면 reshape 시에 원래 우리가 의도했던 행렬이 아니라, 어딘가 뒤틀린 행렬이 됩니다.
이렇게 만들어진 col을 return하면, 이 함수의 일이 끝나게 됩니다.
def col2im(col, input_shape, filter_h, filter_w, stride=1, pad=0):
N, C, H, W = input_shape
out_h = (H + 2 * pad - filter_h) // stride + 1
out_w = (W + 2 * pad - filter_w) // stride + 1
col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)
img = np.zeros((N, C, H + 2 * pad + stride - 1, W + 2 * pad + stride - 1))
for y in range(filter_h):
y_max = y + stride * out_h
for x in range(filter_w):
x_max = x + stride * out_w
img[:, :, y:y_max:stride, x:x_max:stride] += col[:, :, y, x, :, :]
return img[:, :, pad:H + pad, pad:W + pad]
이 im2col의 자매품? 으로, col2im이라는 함수도 있습니다.
Convolution의 backward 연산에 활용되는 함수로, im2col로 만들어진 column에서 원본 이미지로 바꿔주는 함수입니다.
위의 im2col을 거의 그대로 반대로 했을 뿐이므로, 설명은 생략하겠습니다.
이렇게, Convolution 연산의 준비가 모두 끝났습니다! 이제 직접 Convolution 연산을 구현해 봅시다.
def forward(self, x):
# Convolution Calculation
self.x = x
fn, fc, fh, fw = self.param.shape
n, c, h, w = x.shape
out_h = int(1 + (h + 2 * self.pad - fh) / self.stride)
out_w = int(1 + (w + 2 * self.pad - fw) / self.stride)
# Conv Input Size: (Channel, Filter_num, kernel_h, kernel_w)
# Change this using im2col
col = im2col(x, self.kernel_size[0], self.kernel_size[1], self.stride, self.pad)
col_param = self.param.reshape((fn, -1)).T
self.col = col
self.col_param = col_param
out = np.dot(col, col_param)
out = out.reshape(n, out_h, out_w, -1).transpose(0, 3, 1, 2)
return out윗부분 (~out_w... 부분까지)는 지금까지 계속 설명해 왔던 것이므로 설명을 생략하고, 연산 부분만 간단히 보겠습니다.
우선, im2col 함수를 활용하여 input_data인 x를 column으로 바꿔 줍니다.
그리고, Convolution parameter, 즉 filter 또한 행렬로 바꿔주어야 합니다.
그런데 이 연산은 매우 간단하게 수행이 가능한데, 위에서 봤듯이 filter의 경우는 그냥 filter의 개수만큼 쭉 펴주기만 하면 됩니다.
그리고 그냥 점곱을 한번 해 주면, 간단하게 output 값이 나오게 됩니다.
이제, 이 output 값을 원래 크기대로 reshape 및 transpose해주기만 하면, forward 연산은 종료됩니다.
def backward(self, dout):
fn, c, fh, fw = self.param.shape
dout = dout.transpose(0, 2, 3, 1).reshape(-1, fn)
self.grad = np.dot(self.col.T, dout)
self.grad = self.grad.transpose(1, 0).reshape(fn, c, fh, fw)
dcol = np.dot(dout, self.col_param.T)
dx = col2im(dcol, self.x.shape, fh, fw, self.stride, self.pad)
return dx
backward 연산도 비교적 간단합니다.
forward와 반대로, 들어온 dout 값을 transpose한 뒤 reshape해 줍니다.
그리고, MulLayer의 backward함수와 동일하게 (어차피 곱하기만 하므로...) grad를 구해주면 됩니다.
사실 연산 자체는 점곱을 하는 MulLayer와 동일하지만, 단지 transpose와 reshape, col2im만 더해졌다고 보면 됩니다.
이렇게, Convolution Layer의 forward와 backward 연산을 마칩니다.
다음 시간에는 Pooling Layer (Maxpooling, Average Pooling...)을 구현해 보겠습니다.
'인공지능 > 딥러닝 직접 구현하기 프로젝트' 카테고리의 다른 글
| 딥러닝 직접 구현하기 프로젝트 3-1차시: Convolution Layer 틀 잡기 (0) | 2020.08.11 |
|---|---|
| 딥러닝 직접 구현하기 프로젝트 2-7차시 - 코드 정리 + Model Save / Load (0) | 2020.08.01 |
| 딥러닝 직접 구현하기 프로젝트 2-6차시 - 가중치 초기화, 정규화, 드롭아웃 (0) | 2020.07.29 |
| 딥러닝 직접 구현하기 프로젝트 2-5차시 - Gradient Descent Optimizer 구현하기 (2) (2) | 2020.07.07 |
| 딥러닝 직접 구현하기 프로젝트 2-5차시 - Optimizer (Momentum, NAG) 구현하기 (1) (4) | 2020.06.30 |
딥러닝 직접 구현하기 프로젝트 3-1차시: Convolution Layer 틀 잡기
* 모든 코드는 제 깃허브 (cdjs1432/DeepLearningBasic: Deep Learning from scratch)에서 확인할 수 있습니다.
이번 시간부터는, Convolutional Neural Network를 구현해 보겠습니다.
그리고 이번 차시에서는 우선 간단하게 Convoluton Layer을 구현해 보도록 합시다.

Convolution Layer는 일반적으로는 5*5, 3*3, ... 정도의 크기를 가진 filter를, 대략 32개, 64개, ... 만큼 가지게 됩니다.
원래의 Mul Layer이나 Add Layer들이 1차원 크기의 parameter를 가진 것과 다르게, 이 친구는 무려 3차원 크기 (channel도 고려하면 4차원 크기)의 parameter를 가지게 됩니다.
그 점을 반영해서, 일단 ConvLayer의 Init부분부터 짜봅시다.
class ConvLayer:
def __init__(self, filters, kernel_size, stride=1, pad=0, initializer='he', reg=0):
self.activation = False
self.reg = reg
self.x = None
self.param = None
self.grad = None
self.stride = stride
self.pad = pad
self.init = initializer
self.kernel_size = kernel_size
self.filters = filters
self.col = None
self.col_param = None
if type(kernel_size) == int:
kernel_size = (kernel_size, kernel_size)
self.out = (filters, *kernel_size)원래 다른 Layer이 공통적으로 가지는 reg, x, ... 등을 제외하고, 지금 단계에서 봐야 할 변수들은 (일단은) kernel_size, filters, self.out이 되겠습니다.
kernel_size는 Convolution Layer의 크기를 의미하고, filters는 filter의 개수를 의미합니다.
저 아래 if type... 부분은, kernel_size를 int형으로 입력했을 경우 out을 제대로 넣기 위한 부분입니다.
보통 conv layer는 3*3, 4*4... 와 같이 정사각형 모양이기에, 저렇게 input을 받아도 되도록 만들어 두었습니다.
self.out은 parameter가 가지는 shape를 의미합니다.
다음은, train 함수에서 이 Layer가 연산되기 위해 parameter size를 변환하는 코드를 보겠습니다.
def train(self, x_train, y_train, optimizer, epoch, learning_rate, skip_init=False):
if not skip_init:
in_size = x_train.shape[1:]
for name in self.layers:
if not self.layers[name].activation:
out_size = (self.layers[name].out,)
if isinstance(self.layers[name], ConvLayer):
out_size = out_size[0]
fn, fh, fw = out_size
c, h, w = in_size
size = (fn, c, fh, fw)
out_h = int(1 + (h + 2 * self.layers[name].pad - fh) / self.layers[name].stride)
out_w = int(1 + (w + 2 * self.layers[name].pad - fw) / self.layers[name].stride)
in_size = (fn, out_h, out_w)코드를 잠깐 설명해 보겠습니다.
우선, out_size[0]은 아까 받았던 self.out을 꺼내줍니다.
그러면, filter의 개수, filter의 높이, filter의 너비를 알 수 있습니다.
또한, in_size 안에는 input image의 channel, 높이, 너비를 알 수 있습니다.
그리고, 우리는 필터의 크기를 (filter 개수, channel, 높이, 너비)로 만들 것입니다.
(참고: channel을 위처럼 앞에 놓는 것을 channel_first라 하고, (fn, fh, fw, c) 처럼 뒤에 놓는 것을 channel_last라고 합니다. 이번 구현에선 channel_first로 구현합니다.)
다음은 out_h, out_w입니다.
위 out_h, out_w는 Convolution 연산 이후에 나오는 output의 크기입니다.
아직 우리는 padding layer와 stride를 구현하진 않았으나, 그냥 있는 셈 치고 out_h와 out_w를 계산해 봅시다.
이미지의 가로 크기를 w, filter의 가로 크기를 fw라 해 봅시다.
만약 이미지를 padding한다면 가로 크기는 w + 2*pad가 될 것이고, stride=1인 상태라면 연산 횟수는 1 + w + 2*pad - fw가 될 것입니다.
하지만 여기서 stride까지 생각해 준다면, 연산 횟수는 stride의 크기만큼 나눠준 값으로 바뀔 것이므로,
stride를 포함한 연산 횟수는 1 + (w + 2 * pad - fw) / stride가 됩니다.
그리고, output의 크기는 연산 횟수와 동일하므로, out_w는 위의 식으로 정리가 됩니다.
마찬가지의 방식으로, out_h도 동일하게 계산이 가능합니다.
그 뒤, 다음 layer가 받을 in_size의 크기를 (fn, out_h, out_w)로 두면서 size 연산을 끝내 줍니다.
그런데, 이렇게 연산을 하기 위해서는, Flatten Layer도 필요합니다.
사실 지금까지는 우리가 이미 Flatten된 MNIST dataset을 사용하고 있었기 때문에 Flatten Layer가 필요하지 않았지만, Convolution Layer를 구현하기 위해선 Flatten Layer가 필요합니다.
4차원의 이미지를, Fully-connected Layer 및 Softmax 함수가 받을 수 있게 1차원 벡터화 시키는 것입니다.
Flatten 구현은 간단하니 지금 바로 해봅시다.
class Flatten:
def __init__(self):
self.shape = None
self.activation = True
def forward(self, x):
return x.reshape(x.shape[0], -1)
def backward(self, dout):
return dout.reshape(-1, *self.shape)
예, 그렇습니다. forward와 backward는 그저 받았던 input을 1차원으로 바꿔주고, 돌아오는 dout을 원래 형태로 펴주기만 하면 됩니다.
그러기 위해서, self.shape를 만들어서 train 전처리 과정에서 shape를 지정해 주도록 합시다.
elif isinstance(self.layers[name], Flatten):
self.layers[name].shape = in_size
tmp_size = 1
for items in in_size:
tmp_size *= items
in_size = (tmp_size,)(Model.py - train함수 - if not activation 뒷부분)
Flatten 함수는 이전 Layer의 input size - in_size를 shape로 가지게 됩니다.
그리고, 해당 shape를 가졌을 때의 1차원 벡터의 크기는 shape에 있는 모든 원소의 곱이므로, shape의 원소를 죄다 곱해 줍니다.
그리고 해당 값을 다음 layer의 in_size로 바꿔주면 끝입니다.
이제 Convolution Layer의 연산을 다룰 차례입니다만, 이 부분은 다음 포스트에서 더 자세히 다루도록 하겠습니다.
Convolution Layer의 연산이 그렇게까지 단순하게 이뤄지진 않기 때문입니다. (물론, 그냥 곱셈이긴 하지만 말이죠...)
'인공지능 > 딥러닝 직접 구현하기 프로젝트' 카테고리의 다른 글
| 딥러닝 직접 구현하기 프로젝트 3-2차시: Im2col과 효율적인 Convolution 연산 (5) | 2020.08.11 |
|---|---|
| 딥러닝 직접 구현하기 프로젝트 2-7차시 - 코드 정리 + Model Save / Load (0) | 2020.08.01 |
| 딥러닝 직접 구현하기 프로젝트 2-6차시 - 가중치 초기화, 정규화, 드롭아웃 (0) | 2020.07.29 |
| 딥러닝 직접 구현하기 프로젝트 2-5차시 - Gradient Descent Optimizer 구현하기 (2) (2) | 2020.07.07 |
| 딥러닝 직접 구현하기 프로젝트 2-5차시 - Optimizer (Momentum, NAG) 구현하기 (1) (4) | 2020.06.30 |