누구나 이해할 수 있는 딥러닝 - cs231n 3강(Loss Functions and Optimization)
- cs231n 3강의 내용을 정리한 글입니다.
- 최대한 쉽게, cs231n 강의를 스스로 다시 이해하며, 처음 딥러닝을 공부하는 사람들도 쉽게 이해할 수 있게 정리해보았습니다.
- 저도 초보인지라 틀리는 부분이 있을 수 있고, 이해가 안 되는 부분이 있을 수 있습니다. 만약 틀린 부분이 있거나 잘 이해가 되지 않는 부분이 있다면, 바로 댓글로 질문해 주세요! 내용과 관련된 질문은 최대한 아는 선에서 대답해 드리겠습니다!
- 보는 중에 사진들에 나오는 수식같은 경우는, 따로 설명하지 않았다면 건너뛰어도 됩니다.
- 이해가 잘 되지 않은 설명이거나, 설명이 명확하지 않은 것 같으면, 댓글로 피드백 부탁드립니다.

이번 강좌에서는, Loss Function과 Optimization이라는 것들에 대해 배우겠습니다.

그전에, 일단 저번 강좌 복습부터 해보도록 하겠습니다.
우선, 이미지를 인식하는 것이 어째서 어려운 일인가? 에 대해서 이야기하였습니다.

데이터에 기반한 접근법과, K-Nearest Neighbor에 대해서도 배웠습니다.
왼쪽 위에 있는 것은 CIFAR-10데이터셋이고, 그 오른쪽은 K=1일 때와 K=5일 때의 차이를 그림으로 표현한 것입니다.
그 아래 train|test, train|validation|test는, 우리가 hyperparameter를 설정할 때 사용해야 하는 방식이라고 배웠던 것입니다.
둘 중에 어떤 것을 사용해야 했는지 기억이 안나신다면, 2강으로 다시 돌아가서 강좌를 봐주시기 바랍니다.
그리고, 그 오른쪽은 hyperparameter를 하나하나 설정해보며 어떤 값이 가장 최적의 값인지 알아내는 과정을 표로 나타낸 것입니다.

이제부터는 Linear Classifier에 대한 이야기입니다.
위의 K-Nearest Neighbor과는 다르게, W값만으로 predict가 가능하다는 장점과, 더 정확한 정보를 얻을 수 있다는 것이 장점이었습니다.
f(x, W)=W*x+b라는 식으로, (CIFAR-10 기준으로) 10가지의 카테고리당 점수를 알 수 있었습니다.
그 아래는, 이 Weight값들을 사진으로 나타내어, Linear Classifier가 알아낸 카테고리의 특징을 알아볼 수 있습니다.

이 사진은, W값이 랜덤이기에 일어나는 상황이라고 하였죠. 자동차를 제외한 두 가지 카테고리의 점수는 정답을 거의 맞히지 못하는 상황입니다.
그리고, W값이 랜덤이라는 점에서부터, 도대체 W값을 어떻게 바꾸어 나가야 제대로 된 점수를 얻을 수 있을까?라는 질문을 던졌었죠?
바로 그 질문에 대해서 오늘 알아볼 시간입니다.
아! 들어가기 전에, 이 위의 내용 중 잘 모르는 내용이 있다면, 다시 전 강좌로 돌아가서 다시 한번 강좌를 봐 주시기 바랍니다.
최소한 Linear Classifier부분은 완벽하게 이해가 되어 있어야 해요!

우선, 저번의 예제를 단순화시킨 곳으로 가봅시다.
고양이, 자동차, 개구리 세 가지의 카테고리밖에 없다고 가정하고, 그 각각의 점수만 나오는 것이죠.
예제를 보면, '고양이' 이미지는 자동차가 1등, 고양이가 2등, 개구리가 3등으로 나오고,
'자동차' 이미지는 자동차가 1등, 개구리가 2등, 고양이가 3등으로 나오고,
'개구리' 이미지는 자동타가 1등, 고양이가 2등, 개구리가 3등으로 나옵니다.
이렇게 된다면, '자동차' 이미지만이 정답을 맞혔고, 나머지 두 '고양이'와 '개구리'이미지는 정답을 맞히지 못한 것을 알 수 있습니다.
즉, 우리의 Linear Classifier가 썩 잘 작동하는 것은 아니라는 것이고, 우리는 이것을 고치고 싶습니다.
그래서 우리는 이러한 일에 대해 점수를 메기기로 했습니다. 과연 우리의 Linear Classifier가 얼마나 못하고 있는 걸까? 하는 것에 대한 점수죠.
이 점수를 우리는 Loss(오차)라고 합니다. 얼마나 정답에 오차가 있는가.. 하는 느낌이죠
그리고, 그 Loss를 도출하는 함수가 바로 Loss function(오차함수)입니다.
오른쪽의 식을 한번 볼까요? xi값은 이미지, yi값은 그 이미지의 카테고리의 정답인, N개의 데이터셋을 가지고 있다고 해봅시다.
그렇다면, 전체 오차값인 L은 어떠한 오차 함수 Li에 우리의 Linear Classifier인 f(xi, W)와 yi값을 집어넣은 값의 평균이라고 할 수 있습니다.
이러한 방식은, 다른 다양한 딥러닝 작업에 사용되는 오차값을 구하는 공식입니다. 그리고 이 안의 오차 함수가 무엇이 들어가느냐에 따라, 여러 가지 다른 오차값을 구할 수 있죠.

그러면, 여러가지 오차 함수중 하나인 SVM Loss를 알아볼까요?
SVM loss는 작동하는 방식이 굉장히 간단한 오차함수 중 하나입니다. svm loss가 작동하는 방식은 다음과 같습니다.
1) 카테고리를 본다. 만약 그 카테고리가 정답 카테고리라면, 씹고 넘어간다.
2) 정답 카테고리가 아닐 때, (현재 카테고리의 점수 + 1)이 (정답의 점수) 보다 작다면, 씹고 넘어간다.
3) 그렇지 않다면, (현재 카테고리의 점수 + 1) - (정답의 점수)를 오차값에 더해준다.
4) 이렇게 모든 카테고리를 돌았을 때, 나온 최종 오차값을 구한다.
참고로, 2)와 3)은
2)+3) 0과 현재 카테고리 점수 + 1 - 정답 점수 중 최대 점수를 구해서 더한다.
로 줄일 수도 있습니다.
어느 정도로 직관적인 식이라고, 개인적으로 생각합니다만.. 두 가지 정도의 의문이 들 수 있을 것 같습니다.
Q1. 음.. 잠시만요? 이러면 점수가 낮으면 좋은 건가요?
A1. 네, 그렇습니다. 아까 말했다시피, 우리가 구하는 것은 오차값입니다. 얼마나 '틀려있나'의 정도를 나타내는 값이 오차값이라고 하였으므로, 이 점수가 낮다는 것은, 틀려있는 정도가 낮은 것이므로, 점수가 낮으면 낮을수록 더욱 정확하다고 할 수 있겠죠.
Q2. 아니, 그런데 왜 그냥 현재 카테고리의 점수가 아니고, 현재 카테고리의 점수 + 1 값을 비교하고, 더해주는 거죠??
A2. 만약 현재 카테고리의 점수 그 자체를 비교한다면, 2등의 점수와 1등의 점수가 굉장히 근사하다 하더라도, 오차값은 무조건 0, 즉 최고로 좋은 상태가 되어 있을 것입니다. 이런 상황은 우리가 그다지 반기는 상황이 아닙니다. 비록 정답은 맞혔다 하더라도, 굉장히 간당간당하게, 다르게 말하면 운 좋게 맞춘 꼴이 된 것이니깐요.. 그렇기 때문에, 더욱 확실히 정답을 맞히는 것을 목표로, +1을 더해주는 것입니다.
이거 말고 다른 질문이 있으시다면, 댓글로 남겨주시면 감사하겠습니다..

그래서 이 SVM loss를 구한 것을 그래프로 그려본다면, 오른쪽의 그래프와 같은 꼴이 되는 것 까지는 그릴 수 있겠죠?
x좌표가 이미지의 정답의 점수이고, y축이 오차값이 된 그래프입니다. Sj, 즉 어떤 카테고리에 대하여, Sy값이 Sj+1보다 크거나 같다면 오차는 0이고, 그것이 아니라면 Syi가 작으면 작을수록 오차값이 커지는 것을 알 수 있습니다.
이를 hinge loss 라 하는데, hinge(경첩)처럼 그래프가 생겨서 그런 것이라던데.. 전 잘 모르겠네요 ^ㅡㅡ^... 그냥 그렇다고요!

아직도 이해가 잘 안 되실 수도 있습니다. 아직 구체적으로 계산을 안 해봐서 그런 건데요, 한번 구체적으로 계산을 해보도록 합시다.
개구리를 예로 들어볼까요?
1) 고양이 점수 : 2.2, 정답(개구리) 점수 : -3.1이므로, max(0 , 2.2+1-(-3.1)) = max(0 , 6.3) = 6.3
2) 자동차 점수 : 2.5, 정답(개구리) 점수 : -3.1이므로, max(0 , 2.5+1-(-3.1)) = max(0 , 6.6) = 6.6
그리고, 이 둘을 더한 값은 6.3+6.6=12.9이므로,
이 개구리 이미지에 대한 오차값은 12.9라는 것을 알 수 있습니다.
이와 같은 방식으로 고양이 및 자동차의 오차값도 구할 수 있겠죠?

그리고, 최종 오차값은 전체 이미지의 오차값의 평균이라고 하였으므로, (2.9+0+12.9)/3 = 5.27이라는, 최종적인 오차값이 나옵니다.

그래서, 이를 파이썬 코드로 짠 것을 봅시다.
** 텐서 플로우, 케라스, 파이 토치 등의 라이브러리를 사용할 때는 이런 코드를 사용할 필요는 없지만, 위 코드를 정확히 이해한다면 SVM이 무엇인지를 더 잘 이해할 수 있습니다. 만약 파이썬 및 numpy에 대해 잘 모른다면, 그냥 넘어가도 좋습니다.**
def L_i_vectorized(x, y, W) #x는 이미지 픽셀 값, y는 정답 카테고리, W는 가중치입니다.
scores = W.dot(x) #점수를 계산해 줍니다.. dot은 저번에 말한 점수를 계산할 때 쓰이는, dot product, 즉 점곱을 의미합니다.
margins = np.maximum(0, scores - scores [y] + 1) #0과 (현재 카테고리의 점수 + 1) - (정답의 점수)의 최대를 margins에 넣습니다.
margins [y]=0 #하지만, 정답 카테고리의 점수는 무조건 0이므로 정답 카테고리를 의미하는 y값에는 0을 넣어줍니다.
loss_i = np.sum(margins) #그리고, 이 점수들의 합을 구해주고..
return loss_i # 이 값을 리턴합니다.

다시 이론으로 돌아와 봅시다. 그래서 우리가 이 W값을 잘 조정해서, loss값을 0을 만들었다면, 우리는 완벽한 classifier를 만들어 냈다고 볼 수 있겠죠? 그렇죠??... 네 아닙니다 ㅎㅎ
눈치가 빠르신 분들이라면 위 이미지만 보고도 알아차렸을 수도 있겠습니다. 우리가 loss값이라고 만들어 놓은 것은 어떤 값인가요?
바로, training set에 대한 오차값입니다. training set에 대한 오차값이 굉장히 줄어든다고 하여도, 우리가 실제로 넣어보고 싶은 test set에 대한 오차값은 결코 장담할 수 없습니다.
위의 그래프를 보시면 이해가 빠를 것 같습니다. 파란 점은 training data, 초록 점은 test data입니다. 우리가 이 training set의 오차값을 0으로 만들었다면, 아마 우리의 분류기는 저 파란 선처럼 생긴 분류기처럼 작동할 것입니다.
하지만, 저 파란 선은 초록색 점인 test data가 들어왔을 때에는 영 엉망인 결과를 도출할 것입니다. 그리고, 초록 선은, 바로 우리가 지향하고자 하는 선이 되겠습니다. 초록색도 어느 정도 잘 맞으면서, 파란 점들도 대부분을 비슷하게 만족하는 선이니깐요.
참고로, 파란 선처럼 선이 그어지는 것을 바로 overfitting(과적합)이라고 합니다. training set에 너무 근접해 버려서, test set에서의 정답을 맞히지 못하게 되는 문제를 말하는 것이죠.
이렇듯, 우리는 classifier가 최대한 복잡하지 않고, 최대한 간결하고 심플하게 되는 것을 선호합니다. 그래야지, 직접 test set에 부딪혔을 때에도 좋은 결과를 도출할 수 있기 때문이죠.

그렇다면, 이런 문제는 어떻게 해결해야 할까요? 우리는 여기서 regularization(한글로 어떻게 번역하지..? 에잉 몰라 ㅎㅎ)라는 것을 사용할 것입니다. 복잡해진 classifier에 페널티를 가해서, 최대한 간결하고 심플하게 만들어 주기 위한 방법입니다.
위에서는 R(W)라는 놈이 바로 그 Regularization의 식입니다.
저 위의 식에서 보이는 ㅅ자 비슷한 놈은 '람다'라는 변수인데, 저것을 우리는 hyperparameter로 사용하여, R(W)의 값을 적당히 맞춰주는 역할로 설정해 줄 것입니다. 저게 너무 강해져 버리면, 너무 간결함만을 유지하고자 하게 되어서 loss값을 맞춰주는 큰 의미가 없어지고, 너무 작으면 regularization 하는 의미조차도 없어지게 돼버리기 때문이죠.
자주 사용되는 것은 L2 Regularization, L1 Regularization, Elastic Net 등등이 있다고 하는데, 일단 지금은 L2 Regularization이 뭔지만 먼저 보러 가봅시다.

자, 우선 예시를 들어봅시다. R(W)가 L2 Regularization이고, x값(이미지 픽셀 값들)은 [1,1,1,1]이라고 해봅시다.
그리고, w1 [1,0,0,0]과 w2 [0.25,0.25,0.25,0.25]가 각각 가중치라고 했을 때, 우리가 dot product(점곱)을 해서 답을 구했을 때는 모두 1이라는 똑같은 값이 나오겠죠?
그런데, L2 Regularization은 w1과 w2중 어떤 w값을 보았을 때 더 간결하다고, 또는 더 좋다고 생각할까요?
R(W)는 값들의 제곱을 더한 놈이므로, 당연히 w2가 더 좋다고 생각할 것입니다. w1의 모든 원소의 제곱보다는 w1의 모든 원소의 제곱이 더 작으니까요.
즉, L2는 w값이 최대한 평평하게, 너무 큰 값 없이 최대한 비슷한 값으로만 이루어지게 하고 싶은 것이죠. 이러면, 이미지에 가는 가중치들이 다들 비슷비슷해 지므로, 조금 더 전체적인 그림을 볼 수 있지 않을까? 하는 느낌인 것이죠.

자, 이제 다음 스테이지로 넘어가서, 지금까지 하던 SVM이 아닌 Softmax라고 불리는 다른 친구에 대해서 배워봅시다.
아까 전의 SVM에 대해서, 어떻게 SVM이 이루어지는지를 다시 복붙 해 오면..
1) 카테고리를 본다. 만약 그 카테고리가 정답 카테고리라면, 씹고 넘어간다.
2) 정답 카테고리가 아닐 때, (현재 카테고리의 점수 + 1)이 (정답의 점수) 보다 작다면, 씹고 넘어간다.
3) 그렇지 않다면, (현재 카테고리의 점수 + 1) - (정답의 점수)를 오차값에 더해준다.
4) 이렇게 모든 카테고리를 돌았을 때, 나온 최종 오차값을 구한다.
그리고 이것이 바로 SVM Loss가 구해지는 방식입니다.
그렇다면, 이제부터 말할 Softmax는 어떤 방식으로 loss를 구해낼까요?

이 슬라이드를 보면 대충 이해가 빨라질 겁니다.
우선, SVM때와 같이 각 클래스마다 점수를 구해줍니다.
그리고, 각 점수로 e를 제곱해 줍니다.
가령, cat 같은 경우엔 e^3.2가 되어서 대략 24.5가 나오고,
frog 같은 경우는 e^-1.7이 되어서 대략 0.18이 나옵니다.
그리고, 이 수들을 죄다 normalization(정규화) 해 주어서, 확률로 만들어 버립시다. 죄다 더하면 1이 되게 만들자는 것이죠!
그러면, cat의 확률은 0.13, car의 확률은 0.87, frog의 확률은 0.00... 이 됩니다.
이야 끝났다!.. 하고 있으면 안 되겠죠? 우리가 구하고 싶은 건 오차값인데, 0.13이 오차값이 되어버리면, 이건 굉장히 좋은 오차값이 되어버리니깐 말이죠.
그러니까, 우리 이 값에 -log 한번 씌워 봅시다!
그러면, 작은 값은 도리어 큰 값으로 나오고, 큰 값은 작은 값으로 나오니깐, 실제 오차값을 구할 수 있겠죠?
이렇게, 각 점수마다의 확률을 구하여 오차값을 구하는 방식을 Softmax라고 부릅니다.

위 그림은 우리가 했던 SVM과 Softmax의 과정을 나타내는 그림입니다!
이해가 안 되는 부분이 있다면, 위부터 다시 한번 찬찬히 읽어 보시기를 권장합니다.
그런데, SVM과 Softmax의 차이점은 무엇일까요?
일단, SVM은 Loss가 0이 되는 순간, 자기 할 일 다 한 겁니다. max값만을 구하기 때문에, 정답 카테고리가 y [0]이고, 점수가 [10,9,9,9]같이 나오더라도 Loss값은 0이죠? 이걸 완벽한 Loss로 보는 것이죠.
하지만, Softmax는 위 같은 상황을 봐도, 최대한 정답 카테고리의 확률을 높이기를 원하기 때문에, 계속해서 확률을 높이려고 애쓰겠죠? 쭉쭉 올라가서 점수가 [1000,5,3,1] 같아져도 계속해서 확률을 높이기 위한 방향으로 나아갈 겁니다. 웬만해선 loss가 0이 나오지 않는다는 거죠.(0에 굉장히 근접한 값은 나오겠지만 말이죠.)

자, 오늘 한 내용 정리 한번 해봅시다!
(x, y)의 데이터셋을 가지고 있을 때, 점수를 dot product를 통해서 구한 후, SVM 또는 Softmax와 같은 loss function으로 얼마나 오차가 있는지를 알아낼 것입니다.
또한, Regularization , 즉 R(W)를 함께 더해서 최종 loss값을 구할 수 있습니다.
여기까지 잘 따라오셨다면, 이런 의문이 들 차례입니다!
'아니 그래서, 분류기를 어떻게 훈련시키는데?? 이것만 가지고서는, 어떻게 W값을 찾는지는 모르잖아!'
그래서 그건 다음 시간이...

에 하고 싶은데, 이것도 3강에 있네요??
한번, 달려볼까요?!
좋은 W값을 찾아내는 과정인, Optimization(최적화) 시간입니다!!

이 optimization을 나타낼 때에 가장 자주 쓰이는 비유를 들어 설명해 보겠습니다.
제가 여러분들의 눈을 가려버리고, 험한 산골짜기 어딘가에 여러분을 던져놓고 왔다고 생각해봅시다.
그리고, 여러분들은 이 산을 내려오고 싶어 하고요.
자, 이때, 눈을 가린 상태로 산을 내려오려면 어떻게 해야 할까요?
아 물론, 여러분들이 진짜 엄청난 감각의 신이라서, 막 바람을 느끼고 산 향기가 제일 적은 곳으로 텔레포트를 뙇! 하면 딱 내려가질 수도 있겠지만, 사실상 말이 안 되죠..? 산이 험하면 험할수록, 이것도 굉장히 어려워지니깐요.
결국, 여러분들은 어떤 반복적인 행동을 통하여 산을 내려가야 할 겁니다.
이 과정을 두고 optimization이라고 합니다.
산의 높이가 loss이고 여러분의 위치를 W라고 한다면, loss가 적은 곳으로, W를 변화시키며 내려가는 것이니깐요.
자, 그럼 한번 생각해봅시다! 여러분들이라면, 눈을 가린 상태로 어떻게 산을 내려가실 건가요?

자, 우선 가장 멍청한 방법부터 생각해 봅시다.
'야, 그냥 아무렇게나 가면 되겠지 뭐! 어떻게든 되지 않을까?'라는 생각이죠.
W값을 막 바꿔가면서, 최적의 loss값을 찾는 것이죠.

한번 test set에 적용시켜 보면, 15.5% 정도의 정확도가 나온다고 합니다!
띠용~? 생각보다 좋잖아!라고 생각하시진 않겠죠?
State Of The Art(현대 최신 기술)로는 95% 정도가 나오는 건데.. 15.5%면.. 처참합니다 ㅎㅎ..

그러면, 다른 방법을 생각해 봅시다.
땅 주변에 발을 가져다 대 보면서, 좀 낮은 곳으로 조금 움직인 다음, 다시 한번 발을 갖다 대 보며 더욱더욱 낮은 곳으로 내려가 보는 것이죠.

자, 드디어 등장! 우리의 멋진 미분이라는 친구예요!!
근데, 이게 뭔지 설명해버리면, 강의 제목인 '누구나 이해할 수 있는'이 애초에 성립이 안되잖아요..?
간단하게, 미분은 어떤 함수의 기울기를 구한다!라고 생각합시다.
우리의 산이 지금 얼마나 기울어져 있는가? 를 알고 싶다면, 미분이라는 것을 하면 된다!라고 해 둡시다.
물론 미분이 뭔지 안다면 그냥 지나치면 되겠지만 말이죠 ㅎㅎ
대충 미분을 쓸 거고, 위의 식 f(x+h)-f(x) / h라는 공식을 써볼 거다!라는 것만 알아둡시다~!

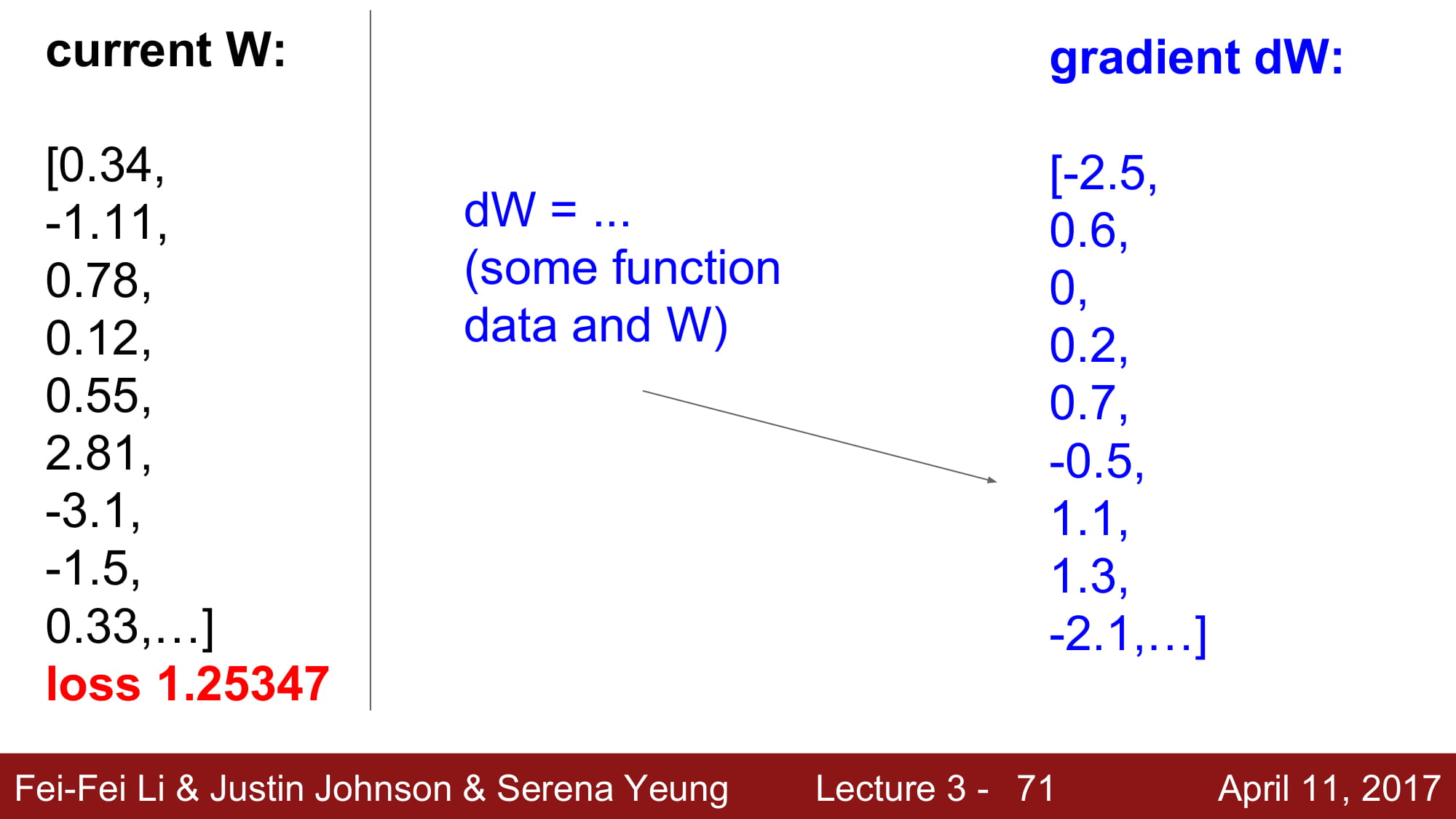
자! 현재 W값으로는 loss가 1.25347이 나온다고 해 봅시다.
그러면 우리는 조금, 조금씩 발을 아래쪽으로 내리면서 갈 거죠?

0.0001이라는, 아주 적은 수를 W의 첫 번째 원소에 더해보니, Loss가 줄어들었습니다!

그리고 한번 '미분'이라는 것을 해보니, 기울기가 -2.5가 나온다네요?

또 더하니깐, 이제는 loss가 커져버렸습니다!

그러면, 또 미분을 해서 보았을 때, 기울기 값이 뙇! 하고 나오고, 이번에는 그 기울기 값이 양수라는 것을 알 수 있네요.

아 잠깐만요!! 이거 계속해서 뭐 어쩌자는 거임!
W값은 더럽게 크고, 이거 0.0001씩 조금조금씩 더해서 이거 언제 다함;;
안 그럼?? 안 그러냐고!!
네, 그렇습니다!
이걸 일일이 다 하고 있기에는 너무 오래 걸리겠죠?

그래서, 뉴턴 형아랑 라이프니치 형아가 와서 도움을 조금 주고 간다네요?
얍!! 하면, 수학적으로 저 위의 미분을 간단하게 할 수 있고,
쨔잔!! 미분 값이 구해졌네요? 이야 신난다! 끝!!
.. 갑자기 왜 이리 대충 하냐고요?
어차피 이거 보시는 분들은 인공지능을 처음 배우시거나, 초보분이실 텐데, 이거 자세히 알 필요가 없어요!
일단 다음 슬라이드로 넘어가 봅시다!

아까 식으로 f(x+h)-f(x) / h를 한 것을 numerical, 그냥 미분 공식으로 나온 것이 analytic입니다.
numerical로 하면, 느리고, 정확하진 않지만(컴퓨터가 소수점을 약간은 빼버리니깐..) 코드 작성은 쉽고,
analytic으로 하면 빠르고, 정확하지만 코드 작성이 어렵답니다.
아 근데요, 어차피 이거 미분식 코드로 짤 거 아니잖아요?? 텐서 플로우나 케라스나 파이 토치나.. 저거 미분식 하나하나 다 쓰고 있을 필요가 없어요!
그러니깐, 그냥 이것만 알아두고 갑시다.
'미분'을 통해서 조금조금씩 loss가 적은 방향으로 내려갈 것이다!

그리고, Gradient Descent, 즉 기울기 하강을 통하여 가장 적절한 W값을 찾아낼 것입니다.
코드가 되게 간단하죠? evaluate_gradient에서 미분 값을 계산하고, weights를 step_size * 기울기만큼 빼준다네요?
엥? step_size가 뭔데요??
뭐, 엄밀한 정답은 아니지만, 아까의 비유를 가져와서 다시 설명하겠습니다.
아까 산을 내려간다고 했죠? 근데 만약에, 여러분 다리가 미친 듯이 길어서, 가야 할 방향으로 조금만 가야 하는데 막 100km를 가버렸다고 해봅시다. 그럼 과연 그게 제대로 내려간 걸까요?
아니겠죠?? 그냥 날아간 수준으로 간 거죠? 그러니깐, 별로 좋지 못하다는 겁니다. 그래서, step_size를 0.001, 0.0001 같은 수로 정해줘서, 다리를 조금 줄여주는 거죠. 최대한 적당한 만큼 가게 말이죠. step_size가 너무 작아서 다리가 너무 작아지는 것도 문제겠지만 말이죠..
즉, step_size란 친구는 우리가 잘 정해줘야 하는 hyperparameter라는 겁니다.

자, 보라-파랑-하늘-.. -빨강 순으로 낮은 곳이라고 생각해봅시다. 그러니깐, 중앙이 가장 낮은 부분이라고 생각해 봅시다. 3차원 그릇 같은 모양인 거죠.
그러면, 대충 우리가 가야 하는 방향 (미분해서 나온 기울기의 방향)은 위의 하얀 화살표 방향 비슷하게 나올 겁니다.
그리고, 우리는 중앙으로 가고 싶어 하는 것이죠.
여기서 step_size의 조금 더 엄밀한 내용이 나옵니다.
만약 우리가 저 방향으로 너무 멀리 가게 돼버린다면, 우리가 지향하는 빨간색이 아닌, 저ㅓㅓㅓㅓ 끝의 보라색으로 가버리겠죠?
즉, 현재 지점보다 높은 곳으로 갈 수 있다는 건데, 현 지점보다 높은 곳으로 가버리면, 기울기가 더욱 커지게 됩니다.
그러면 또다시 더ㅓㅓㅓㅓ욱 더ㅓ====욱 먼 곳으로 날아가고, 이런 악순환이 반복되게 됩니다.
그렇기 때문에, step_size를 잘 설정해줘서 최대한 제대로 가게 만들어야죠.
하지만, step_size가 너무 작으면, 가자는 방향으로 아주 쬐ㅣㅣ끔만 가는 꼴이 되는데, 그러면 진짜 엄청나게 오래 이 짓을 해야 할 겁니다.
마치, 아래 방향으로 산을 손톱 크기만큼 내려가고, 또 그렇게 내려가고.. 하면 되게 오래 걸리겠죠?
그러니깐, step_size를 최대한 적절하게 조정해 주어서 빨간 방향으로 잘 가게 만들어줍시다.

여기서 잠깐!
근데, 모든 사진들을 이런 식으로 계산하기에는 너무 오래 걸립니다.
가령, Imagenet Challenge에서는, 대략 1.3 Million, 즉 130만 개의 training set이 있는데, 이 사진 하나하나를 죄다 미분하고 계산하고 하기엔 너무 느리고, 오래 걸립니다.
그래서 생각해낸 방법이 바로 Stochastic Gradient Descent, 줄여서 SGD입니다.
아이디어는 간단합니다. 매번 loss를 계산할 때, 우리 training set에서 랜덤으로 조금만 가져와서, 그 사진들에 대한 loss를 계산하고, weight를 계산하는 겁니다.
이러면 당연히 더 빨리 계산이 가능해지겠죠?
대부분의 경우에는 이런 SGD기법을 사용하여 계산을 더욱 빠르고 효율적으로 진행한다고 하네요 ㅎㅎ

이야! 쉬는 시간이다!!
http://vision.stanford.edu/teaching/cs231n-demos/linear-classify/
직접 들어가서, x, y, Softmax/SVM, Regularization 등을 손대 보면서 최적의 값을 찾아보세요!
step_size잘못 건드리면 황천길 가고,
Regularization 잘못 건드리면 무지개다리 건넌다는 것만 확실하게 느끼면 좋겠네요 ㅎㅎ
*뒤에 슬라이드들 여러 개 있는데, 별로 안 중요해 보여서 그냥 거르겠습니다^^
저거 해봤자 나도 힘들고, 보는 사람도 힘들고 해서 ㅎㅎ
아무튼! 최종 정리 한번 해봅시다.
1.SVM/Softmax loss에 대해서 배웠다.
2. Regularization에 대해서 배웠다.
3. optimization에 대해서 배웠다.
3-1. step_size가 뭔지 배웠다.
4. SGD가 뭔지 배웠다.
아니.. 뭔가 되게 많이 한 것 같은데 별거 없잖아?? 내가 뭐 빼먹었나?
아몰랑 ㅎㅎ 아무튼 저 위에 4개 중에 기억이 잘 나지 않는 부분이 있다면, 다시 한번 읽어 보고, 위 내용만큼은 확실히 흡수할 수 있도록 합시다.
근데 위에 4개 말고 했는데 빼먹고 안 적은 거 있을 수도 있는데.. 아무튼 저것만큼은 기억합시다!

다음 시간에는, neural network(인공신경망)에 대해서 배울 것이고,
Backpropagation(역전파법)에 대해 배울... 건... 데...
다음 강좌는 굉장히 *수학 수학* 해질 것 같네요..
아무튼, 다음에 봐요! 안녕!@@
'인공지능 > 누구나 이해할 수 있는 딥러닝(cs231n)' 카테고리의 다른 글
| 누구나 이해할 수 있는 딥러닝 - cs231n 5강 (Convolutional Neural Networks, CNN) (2) | 2018.08.01 |
|---|---|
| 누구나 이해할 수 있는 딥러닝 - cs231n 4강(Backpropagation and Neural Networks) (0) | 2018.07.25 |
| 누구나 이해할 수 있는 딥러닝 - cs231n 2강 (2) | 2018.07.15 |