강화 학습 개념 정리노트 - CS234 1강 (강화 학습의 개념, MDP)

CS234의 강의를 바탕으로, 강화 학습의 개념을 정리합니다.
간단히 내용을 훑고싶은 분들에게 추천드립니다.
Reinforcement Learning (RL) - Learn to make good sequences of decisions
= 순차적 결정을 잘하도록 학습하는 것.
강화 학습이 다루는 측면 4가지
Optimization : 최적의 결정을 하도록 훈련하는 것.
Delayed Sequence : 지금 한 일이 나중에 영향을 미치는 것. ex) 미리 먹어둔 게임 아이템이 후반에나 쓰임.
Exploration : 새로운 일을 하도록 탐험하는 것. 이미 하지 않았던 것을 시도하며 관찰하는 것. ex) 한 번도 가지 않았던 길로 가봄.
Generalization : 훈련한 것을 일반화시키는 것. 픽셀값들로 훈련한 모델이라 하더라도, 조금 더 고수준으로 이해 가능하게 하는 것.
ex) 픽셀값으로만 훈련한 퐁 AI가 게임의 룰을 일반화해서 학습함.

Agent : 우리가 학습시키고자 하는 AI.
Action : 행동.
Observation : 관찰. Agent가 보고 듣는 것.
Reward : 보상. 어떤 Action을 취했을 때 얻는 점수의 개념임.
World : 세상. 일반적으로 학습시키고자 하는 환경을 의미함. (게임의 경우 게임 세상)
(저번 포스팅 복붙ㅎ)
강화 학습의 목표 - Agent가 최선의 Action을 취하도록 함.
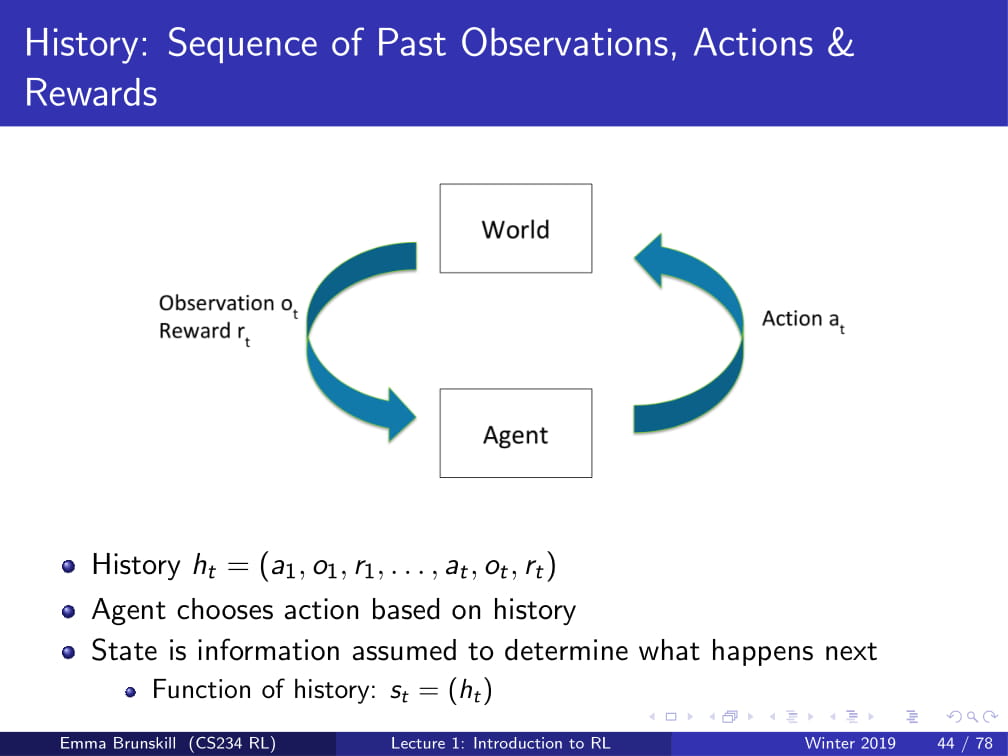
History : 지금까지의 Observation의 기록
State : History를 활용하여 결정을 내릴 때 사용하는 정보
(State는 일종의 History를 이용한 함수임.)
World State : World를 구성하는 모든 것에 대한 State.
ex) 게임 규칙, 게임 진행 순서, 스테이지 개수 등등
Agent State : Agent가 볼 수 있는 World에 대한 State
ex) 게임 픽셀이 움직이는 방식
Markov Assumption : 충분한 정보의 State가 주어진다면, History 전체를 사용하여 예측한 결과와 그 State를 사용하여 예측한 결과가 같음.
즉, Markov Assumption이 참일때, 미래는 과거에 독립적임.
Markov Assumption의 사용 이유 : 일반적으로 어떤 경우에서라도 Markov Assumption을 참으로 만들 수 있음.
(State = History인 경우 언제나 만족함.)
Fully Observability : 완전 관찰가능함. World State를 모두 볼 수 있음. 이 경우, State = World라고도 함.
Partially Observability : 부분적으로만 관찰가능함. 위의 Fully Observability보다 일반적임.
이 경우, 관찰 가능한 부분에 대한 정보만을 갖고 결정을 내림.
ex) 포커 게임에서 상대방의 패를 보지 않고서도 게임을 진행함.
Bandits : 지금 취한 Action이 나중의 Observation에 영향을 끼치지 않는 문제류.
ex) 개별적인 고객에게 광고를 추천하는 것. (지금 무슨 광고를 제안해줘도 다음 고객이 왔을 때와는 별개임.)
MDP와 POMDP : 지금 취한 Action이 나중의 Observation에 영향을 미침.
전략적인 선택이 필요할 수 있음.
MDP의 종류
Deterministic(결정론적) - 특정한 상황에서 무조건적인 답이 존재함. (물리 문제와 같은 것.)
Stochastic(랜덤?) - 특정한 상황에서 무조건적인 답이 존재하지 않음. (광고를 추천해 줬을 때, 그 대상이 볼지 안 볼지는 모름.)
RL이 갖는 요소들 (안가질 수도 있지만, 최소한 하나씩은 가짐)
Model : Agent의 Action에 따라 어떻게 World가 변화하는지를 표현하는 것.
Policy : Agent가 어떤 상황에서 어떻게 Action 할지에 대한 정책.
Value function : Agent가 특정 Policy에 대해 얼마나 효과적인지 확인하는 함수.
Exploration : 탐험. 한번도 해보지 않은 짓을 하는 것. ex) 식당에서 먹어보지 않은 음식을 시킴.
Exploitation : 정답. 원래 제일 좋은 성과를 내던 짓을 하는 것. ex) 식당에서 맨날 먹던 것을 시키는 것.
Evaluation : Policy가 주어졌을때, 어떤 reward가 주어질지 예측하는 것.
Control - Optimization : 최선의 Policy를 찾는 것.
'인공지능 > 강화 학습 개념 정리노트 (CS234)' 카테고리의 다른 글
| 강화 학습 개념 정리노트 - CS234 2강 (MDP / MRP / Policy Iteration / Value Iteration) (0) | 2019.04.28 |
|---|