모두를 위한 딥러닝 (sung kim) lec4 - Multivariable Linear Regression (다변수 선형 회귀)

이번 포스팅에서는, Multivariable Linear Regression, 즉 다변수 선형 회귀에 대해서 알아보겠습니다.

일단 저번 시간까지 했던 내용들을 복습해 보겠습니다.
일반적인 Linear Regression의 Hypothesis는 H(x) = Wx + b였죠?
Cost function은 H(x) - y를 제곱해서 모두 더한 뒤 평균값을 내주는 것이었고...
Gradient Descent는 가장 적절한 (cost(W) 값이 가장 작은) W값을 찾아내는 알고리즘이었습니다.
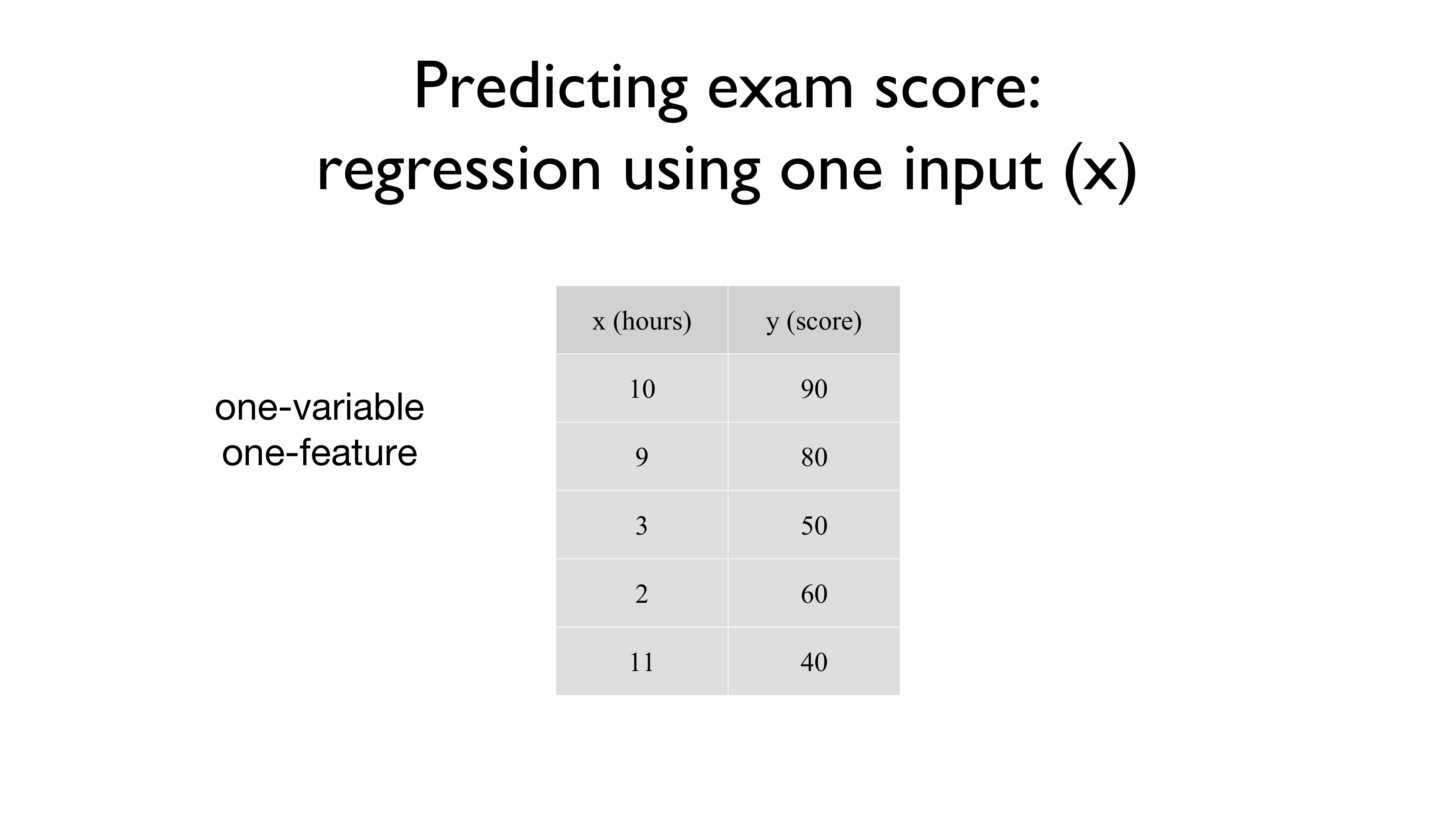
그리고 우리가 마주했던 데이터들은 다들 이런 형식으로 생겼습니다.
x값 하나당 y값 하나가 주어지는 형식이었죠.
이때, x는 하나의 feature을 의미합니다.
가령, 위의 경우엔 특정 점수 y를 그 점수를 갖게 되었던 특징인 feature x를 통해 알아봤던 것이죠.
그래서 위의 사진에서 one-variable one-feature라고 적혀있는 것입니다.
변수 하나에 특징도 하나밖에 (공부한 시간) 없으니까요.

그런데, 오늘 배울 Multi-variable Linear Regression은 데이터가 조금 다르게 들어옵니다.
x값이 하나가 아니라, 두 개, 세 개, 혹은 10000개도 들어오는데요,
각각의 x값 (x1, x2, x3)들은 각자의 특성을 띄고 있습니다.
위의 예시의 경우 x1 은 quiz1의 점수,
x2는 quiz2의 점수,
x3는 중간고사 1의 점수이고
이 점수들을 모두 어떠한 방식으로 계산했을 때 최종 점수인 Y가 나오게 되는 것입니다.

그런데, 그렇게까지 어려워지진 않았습니다!
Linear Regression의 기본형인 H(x) = Wx + b 를 그대로 따라서,
H(x1, x2, x3) = w1x1 + w2x2 + w3x3 + b
로 약간만 변형되었을 뿐입니다.
잠깐만 살펴보면, x의 종류 (feature의 개수)가 늘어나면, 그에 따라 w의 개수도 늘어나게 됩니다!
x1에는 w1, x2에는 w2, x3에는 w3를 곱해주는 식으로 말이죠.
그리고, b의 값은 여전히 그대로 남아있습니다.
feature가 많아졌다고 해서 b의 개수도 많아지진 않은 것이죠.
(그도 당연한 것이, 각자의 x값에 b를 더하더라도 어차피 상수 하나 더한 거랑 같으니까요.)

그럼, Cost function은 어떻게 바뀌었을까요?
H(x1, x2, x3) = w1x1 + w2x2 + w3x3 + b
를 그대로 우리가 사용하던 Cost function 안에 집어넣으면 됩니다.
즉, H(x1, x2, x3) - y 를 제곱한 것을 모두 더해서 평균을 내는 것이죠.
조금만 더 풀자면, H(x1, x2, x3) = w1x1 + w2x2 + w3x3 + b 이므로,
w1x1 + w2x2 + w3x3 + b - y 를 제곱해서 모두 더해주는 것이죠.

그리고 x1, x2, x3와 같이 feature의 개수가 세 개가 아니고 무수히 많더라도, 위의 식처럼
H(x1, x2, x3,... , xn) = w1x1 + w2x2 + w3x3 +... + wnxn + b
로 표현이 가능합니다.
즉, 우리가 원래 알고 있던 Linear Regression의 식을 아주 쬐끔만 변형시켜 주면,
Multi-variable Linear Regression도 뚝딱 해낼 수 있습니다.
그런데, 중요한 것은 그게 아니고,
"그래서 이거 계산 어떻게 할건데?"입니다.
그러니깐, 기본적인 Linear Regression에서는 x값이 10개 정도 주어지고, w값이 하나니깐
x1 * w + x2 * w + x3 * w +... + x10 * w + b
정도로 계산이 가능했고, 그냥 {x1, x2, x3,... , x10} * w + b만 해도 되었습니다.
하지만, feature이 많아져서, 상황이 조금 달라졌습니다.
x1의 첫 번째 데이터를 x11, x3의 네 번째 데이터를 x34... 이런 식으로 쓰고, feature가 n개이고 데이터의 개수가 m 개라면 우리가 계산해야 할 식은
x11 * w1 + x21 * w2 +... + xn1 * wn + b
+ x12 * w1 + x22 * w2 +... + xn2 * wn + b
...
+ x1m * w1 + x2m * w2 +... + xnm * wn + b
처럼... 딱 봐도 복잡한 이차원 배열 * 일차원 배열을 계산해야 합니다.
하지만, 이것을 반복문으로 그냥 쭉 돌려버릴 수도 없는 것이...
가령 n과 m이 각각 10 만씩이라고만 해도,
반복문으로 돌리면 100억 번의 연산을 해야 한다는 말도 안 되는 결과가 나오기 때문입니다.
그러면 이것을 어떻게 간단하게 연산할 수 있을까요?
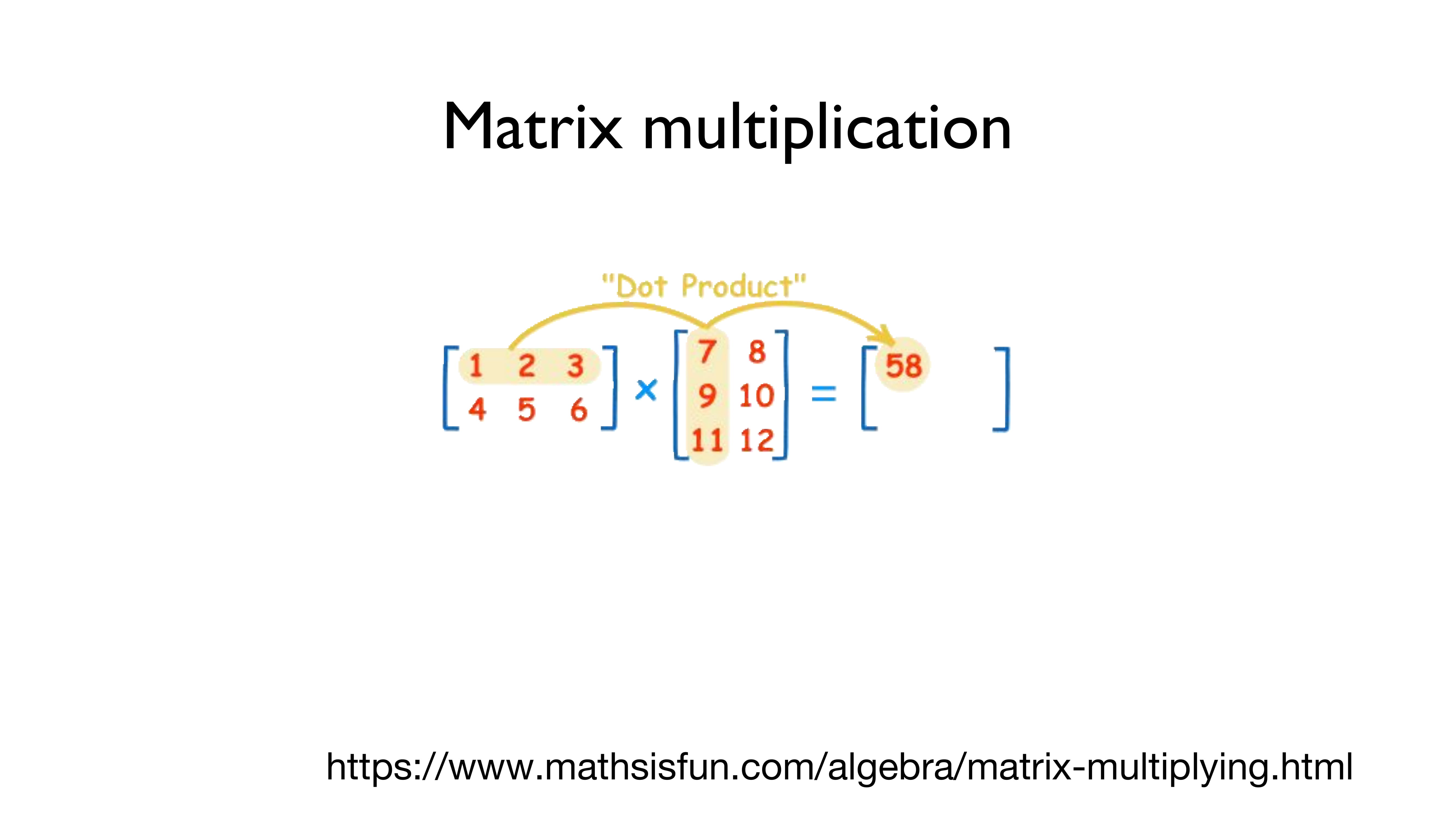
바로, "Matrix multiplication", 즉 "행렬곱"으로 이 문제를 해결합니다.
행렬곱은 어떤 식으로 진행되는지 위의 그림을 통해 알아봅시다.
(헷갈릴까 봐 써놓는데 - 가로가 행이고 세로가 열입니다!!!)
왼쪽의 [[1,2,3], [4,5,6]]의 (2,3)의 행렬과 [[7,8], [9,10], [11,12]]의 (3,2) 행렬을 곱하는 것은 간단합니다.
왼쪽의 행렬의 첫 번째 행인 [1,2,3]의 각각의 요소들을 오른쪽의 행렬의 첫 번째 열인 [7,9,11]로 곱해서 더해줍니다.
즉, 1*7 + 2*9 + 3*11 = 7 + 18 + 33 = 58
이 되는 겁니다.
그리고, 이 값을 결괏값의 행렬의 첫 번째 행, 첫 번째 열에 놓습니다.
두 번째도 동일하게 진행하면 됩니다.
왼쪽의 행렬의 첫 번째 행인 [1,2,3]의 각각의 요소들을 오른쪽의 행렬의 두 번째 열인 [8,10,12]로 곱해서 더해줍니다.
그러면, 1*8 + 2*10 + 3*12 = 8 + 20 + 36 = 64가 됩니다.
그리고, 이 값을 결괏값의 행렬의 첫 번째 행, 두 번째 열에 놓습니다.
두 번째 열은 직접 한번 해보시기 바랍니다.

자, 대충 배웠으니 한번 대충 적용해 봅시다.
w1x1 + w2x2 + w3x3을 행렬로 계산하려면 어떻게 해야 할까요?
x1, x2, x3를 (1,3)의 크기의 행렬로 놓고,
w1, w2, w3을 (3,1)의 크기의 행렬로 놓는다면,
행렬곱을 통해 x1 w1 + x2w2 + x3w3를 구할 수 있게 됩니다.

그런데, 우리가 가지고 있는 데이터는 x1, x2, x3값이 각각 하나만 들어있는 데이터가 아니죠?
x1 여러 개, x2 여러 개, x3 여러 개로 이루어진 데이터를 갖고 있는데, 이것을 어떻게 계산할까요?

아까 저 위에서 했던 짓을 똑같이 반복하면 됩니다.
우선, x값들의 행렬 중 첫 번째 행인 x11, x12, x13과 w1, w2, w3를 곱하여,
x11w1 + x12w2 + x13w3을 결괏값 행렬의 첫 번째 요소로 넣어줍니다.
그다음엔 x21w1 + w22w2 + w23w3 을 넣게 될 것이고,
그것을 마지막 데이터인 x51, x52, x53까지 반복하면 되는 것입니다.
그러면, 왼쪽의 x값의 데이터와 오른쪽의 w값의 데이터를 통해 결괏값을 행렬로 도출해 낼 수 있는 것이죠.

그런데 행렬곱에는 특징이 하나 있습니다.
입력되는 데이터의 형태에 따라 결괏값의 형태가 달라진다는 것이죠.
가령 바로 위의 예시를 보면, (5,3) 크기의 데이터와 (3,1) 크기의 데이터를 행렬곱하면, (5,1) 크기의 결괏값이 나오게 됩니다.
어떻게 보면 당연한 것이긴 합니다.
왼쪽의 (5,3) 행렬의 각각의 행을 오른쪽 (3,1)의 행렬에 곱해서 모두 더한 값은, 결괏값인 (5,1)의 행들에 집어넣고 있으니까요.
그런데, 여기서 중요한 점 하나가 더 있습니다!!
만약, (5,3) 크기의 행렬에 (2,1) 크기의 행렬을 행렬곱시키면 어떻게 될까요?
... 행렬곱 시킬 수 없습니다.. ㅎㅎ
이것도 어떻게 보면 당연한 것이겠지만,
x1, x2, x3를 w1, w2에만 곱할 수는 없는 노릇 아니겠습니까 ㅎㅎ
즉, 행렬곱을 계산해 줄 때에는 데이터의 크기를 잘 생각해야 합니다!
(n, m) 크기의 행렬을 x값으로 사용할 것이라면,
(m, 1) 크기의 행렬을 w값으로 사용해 주어야 한다는 것입니다.
그러면 결괏값은 (n, 1) 크기의 행렬로 나오게 되겠지요.

그런데, 중요한 게 또 또 있습니다!
행렬곱은 일반적인 곱셈과는 다르게 곱셈의 순서가 중요하다는 것입니다!
위의 식처럼, (5, 3) 크기의 행렬과 (3, 1)를 곱하면 (5, 1)이라는 행렬이 나오지만,
반대로 (3, 1) 크기의 행렬과 (5, 3) 크기의 행렬은 곱할 수 없다는 것입니다.
즉, 순서가 매우 매우 매우 중요합니다!!
앞 행렬의 행 크기와, 뒷 행렬의 열 크기가 동일해야 한다는 것입니다!
아까 전과 마찬가지로, (m, n)의 행렬에 곱할 수 있는 행렬은 (n , k) 꼴의 행렬뿐입니다.
(결괏값은 (m, k) 크기의 행렬로 나오겠죠.)



즉, 지금까지 하고 싶은 말이 무엇인고 하니...
우리가 Python이나 Tensorflow로 위의 Linear Regression을 구현하려면
지금까지 배웠던 H(x) = Wx + b 로 계산하는 것이 아니고,
H(X) = XW로 구현해야 한다는 것입니다!
이것을 특별히 더 강조한 이유는 간단합니다.
이거 처음 배울 때 저는 이 행렬 순서를 맞춰야 된다는 사실을 모른 채라 삽질을 오지게 했기 때문이죠 ㅎ
여러분들은 행렬의 크기를 맞추지 않아서 삽질하는 일은 없도록 합시다!

다음 포스팅에서는 Logistic Regression에 대해서 알아보겠습니다.
그럼 안녕!!
'인공지능 > 모두를 위한 딥러닝 (sung kim) lec' 카테고리의 다른 글
| 모두를 위한 딥러닝 부록편 - 미분의 개념과 Gradient Descent (1) | 2019.05.10 |
|---|---|
| 모두를 위한 딥러닝 (sung kim) lec5 - Logistic Classification (로지스틱 회귀분석) (0) | 2019.05.09 |
| 모두를 위한 딥러닝 (sung kim) lec3 - Gradient Descent (경사하강법) (0) | 2019.04.08 |
| 모두를 위한 딥러닝 (sung kim) lec2 - Linear regression & cost function (0) | 2019.03.30 |
| 모두를 위한 딥러닝 (sung kim) lec1 - 머신 러닝 기초 (0) | 2019.03.28 |