강화학습 강의 (CS234) 6강 - CNN + DQN (Deep Q Network)

- 본 포스팅은 CS234 6강의 내용을 정리합니다....만 CNN 부분은 따로 설명하지 않겠습니다.
그 대신, 제 블로그의 CS231n 강의 (https://cding.tistory.com/5) 를 보시거나 간단한 CNN 오버뷰 정도는 보고 오시면 좋겠습니다.

오늘 배울 것들로는 원래는 CNN과 Deep Q Learning이겠지만, 위에서 언급했듯 DNN 및 CNN은 설명하지 않고 바로 DQN으로 뛰어넘도록 하겠다.

그래서, DQN이 뭔지, 어떻게 이루어지는지 알아보자.

저번에 짤막하게 설명했듯이, function approximation, off policy control, boostrapping 셋을 모두 사용하는 것은 굉장히 unstable하다. Converge하지 않을 가능성이 농후하기 때문이다.
짤막하게 DQN의 역사에 대해 설명하자면,
1994년즘에 backgammon을 DQN으로 구현해낸 이후로 1995년 ~ 1998즘엔 위에서 말한 unstability를 개선하기 위한 연구를 진행하다가 DNN 자체가 망하는 바람에 연구가 더 진행되지 못했다.
그러다 2000년대 중반즈음부터 computational power의 증가 및 data의 증가 등의 이유로 DNN이 각광받기 시작하며,
DQN 또한 같이 주목받게 되었다.
그리고 2014년 (정말 얼마 안되었다) 경 Deepmind에서 위처럼 breakout (벽돌깨기) AI를 DQN을 사용해서 만들기에 이른다.
최근에는 도타 2 AI인 Openai five가 5대5로 프로게이머를 이기고, 전세계 사람들과 대전했을 때 99.5%의 승률을 자랑하기까지 하는 등 Deep Reinforcement Learning이 각광받고 있다.

아무튼, 우리는 DNN을 사용해서 Reinforcement Learning을 시킬 것이다.
(당연히 VFA를 사용한다.)
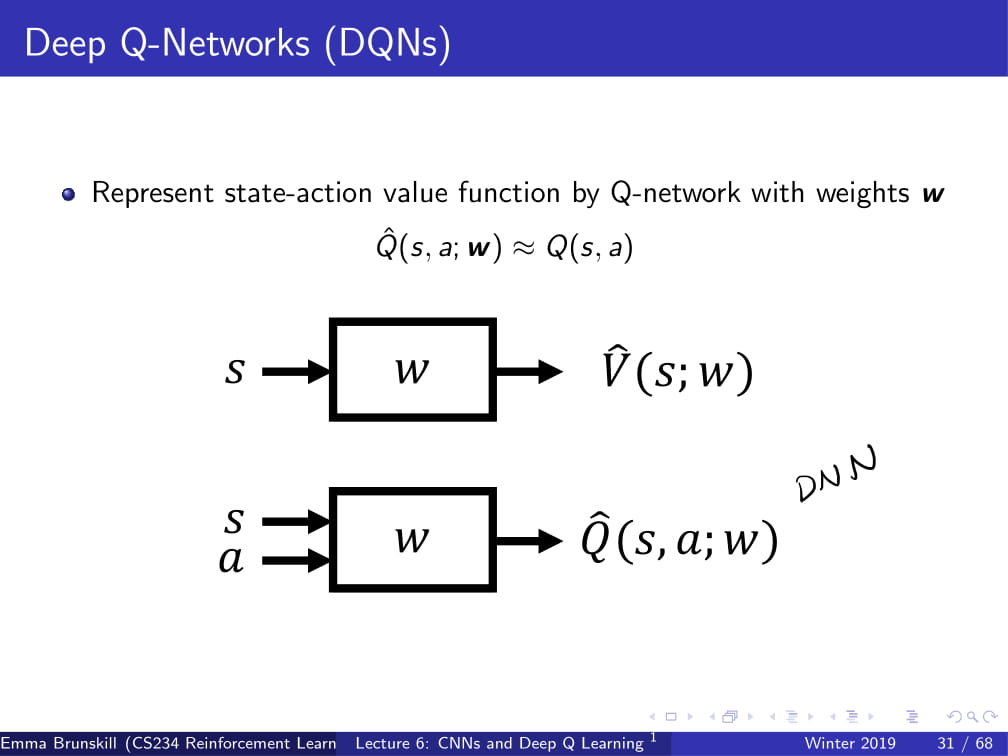
DQN은 그냥 Q (state action)을 DNN에 적용시킨 것 뿐이다. 그렇게 Value와 Q function을 구하는 것이 목적이다.


(대충 저번 시간에 했던 내용이므로 대충 생략하겠다는 말)
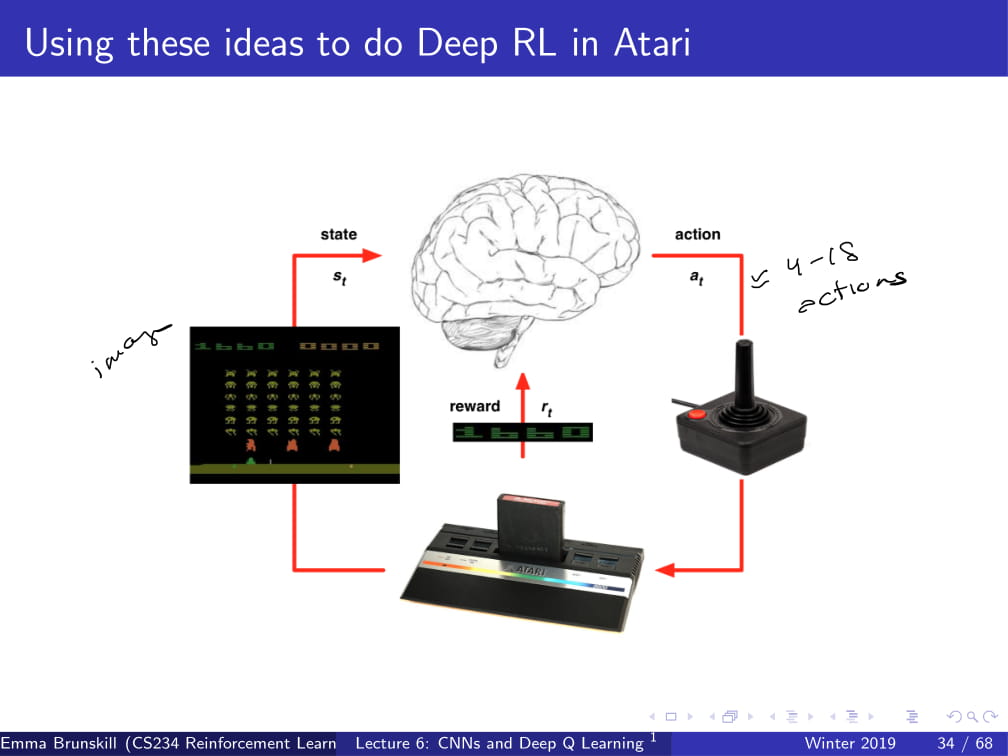
그래서 이러한 Q-Learning 방식을 Atari 게임에 적용시키면 된다.
게임 화면의 이미지를 state로, agent가 취하는 컨트롤을 action으로, 그리고 게임에서 주는 점수를 reward로 한다.
그렇게 해서 agent를 학습시켜 보자는 것이 기초적인 아이디어이다.
Atari Breakout (벽돌깨기) 을 예시로 들 것인데, Atari breakout같은 경우 action의 종류가 약 4개에서 18개정도밖에 되지 않는다.
하지만, state같은 경우 이미지의 픽셀값들을 받아오므로 굉장히 큰 data가 된다. 이것들을 어떻게 다뤄야 하는지 알아보자.

참고로 말해두자면, 지금부터 배울 대부분의 내용들은 2015년도 Deepmind의 Atari DQN 논문에 있는 내용들이다.
우선, input으로는 이전 4프레임의 이미지를 받는다.
1프레임의 이미지만을 input으로 두지 않고 이렇게 4프레임의 이미지를 받는 이유는 공의 방향이나 속도들을 알기 위해서이다.
CNN과 relu, fully-connected layer 등을 걸쳐 나오는 output은 Q(s,a)로, 18개의 조이스틱 및 버튼의 움직임을 표현한다.
그리고 Deepmind의 논문에서는, 이 아키텍쳐와 hyperparameter 들을 모든 게임에 동일하게 적용하였다.
그것만으로도 충분히 학습된다는 것을 보이기 위해서였고, 실제로 많은 게임들에 잘 적용되는 것을 볼 수 있다.
물론, 몇 개의 게임들은 확실히 tuning해야 할 것이다.
가령 delayed reward가 매우 중요한 게임들은 (감마) 값을 높게 두어야 할 것이다.

이제 진짜 본론으로 들어가보자.
Q-learning을 VFA를 사용해서, SGD를 사용해 MSE loss를 최소화시키고, 최적의 Q*(s, a)를 찾아가는 과정이다.
그러나, 저번에도 말했듯이 Q-learning을 VFA와 함께 사용하면 diverge할 수 있다. (수렴하지 않고 막 나간다)
그 이유는 첫번째로는, sample간의 연관성이 너무 크기 때문이다.
아까 전, 분명 DQN은 게임의 화면을 5프레임 간격으로 받는다고 했었는데, 분명히 게임의 연속된 다섯 프레임은 굉장히 연관되어 있을것이다.
그런데 이렇게 sample 간의 연관성이 너무 커져 버리면, SGD 방식으로 수렴하기 위해 필요한 IID 상태가 아니게 된다.
(IID란 간단히 말해서 모든 데이터들이 다 독립적이어야 한다는 뜻이다.)
또한, target이 non-stationary하다. 즉, target이 계속 변화한다.
VFA를 적용시키려면, 최소한 어디에 Converge시켜야 하는지는 알아야 한다.
그런데 Q-learning의 경우 이 optimal policy가 계속 바뀌므로, 어디다 Converge하기가 쉽지 않다.
이 두 가지 문제점을 해결하기 위해서, deepmind에서는 Experience Replay와 Fixed Q-target이라는 방법을 사용한다.

Experience Replay는, 말 그대로 지금까지의 경험을 축적해서 다시 사용하는 것이다.
원래였다면 그냥 한번 w와 policy를 update하고 말 경험들 (지나친 step들)을 저장하고 있다가, 나중에 다시 이 값들을 사용해서 w값을 update해 주는 것이다.
이렇게 하면 원래 굉장히 높은 연관성을 띄던 데이터들로부터 벗어나서, 조금 더 독립적인 (연관성이 적은) 데이터들로 다시 w를 update해줄 수 있는 것이다.
또, 원래 update하던 도중에도 Q-learning방식을 사용했기에 target value가 이미 바뀌어 있을 것이고, 그러면 그 바뀐 값에 대해 다시 독립적인 데이터를 사용해 w를 update해줄 수 있는 것이다.

Fixed Q-Targets는 말 그대로, target weight를 고정시켜주는 것이다.
Q-learning 방식에서는 계속 target이 바뀌어서 문제였지만, 이것을 그냥 고정시켜줌으로써 대처하는 것이다.
target update를 할 때 사용할 weight w⁻와 실제 update를 해 줄 weight w를 나누어서 사용하는 것이다.
아래쪽의 식을 보면 이해가 빠를 것 같다.
원래 max를 시켜주는 저 target에는 w⁻를 집어넣고, 그 외 나머지 부분에는 원래 weight w를 집어넣어 준다.
그리고, n번째 마다 (hyper parameter이다.) w⁻값을 다시 원래 w값으로 맞춰 준다.
이렇게 해 주면, 원래 Q-learning에서 계속 w가 바뀌다가 결국 w가 막 infinity로 터지는, 그런 상황을 방지할 수 있다.
즉, stability가 꽤 많이 향상된다는 것이다.

-정리-
DQN은 experience replay와 fixed Q-target를 사용한다.
replay memory D에 experience (s, a, r, s')을 채워주고, 거기서 mini-batch를 sampling해서 update한다.
또 fixed parameter w⁻를 사용하여 Q-learning target을 연산하고, MSE loss를 최소화 시켜준다.
SGD를 사용하고, (위에서 나오진 않았지만) ε-greedy exploration도 사용한다.
그러면, 이렇게 학습하면 잘 될까?
https://www.youtube.com/watch?v=V1eYniJ0Rnk
ㅇㅇ.. 잘 된다!

그럼 DQN에선 어떤 부분이 가장 중요할까?
위 표를 보면 알겠지만, experience replay를 적용시키는 경우 효율이 가장 좋은 것을 알 수 있다.

이제부턴, Deepmind의 논문 이후에 발표된, Deep RL의 주요 improvemets들을 설명하겠다.

그 중 첫번째는, 바로 Double DQN이다.
저번에 설명했던, maximization bias 문제를 해결하기 위해 나온 Double Q-learning의 Deep RL 적용판이다.

Double Q-learning이 뭐였는가?
Q를 하나만 쓰는 대신, 두 개를 사용하여 50% 확률로 Q1, 나머지 50% 확률로 Q2를 사용하여 Q-learning을 하는 방식이었다.

이 아이디어를 DQN에도 적용시킨 것이 바로 Double DQN이다.
현재 사용하는 Q-network w를 action을 고르는 데 사용하고,
w⁻는 action을 evaluate 하는 데 사용하는 것이다. (위 식 참고)
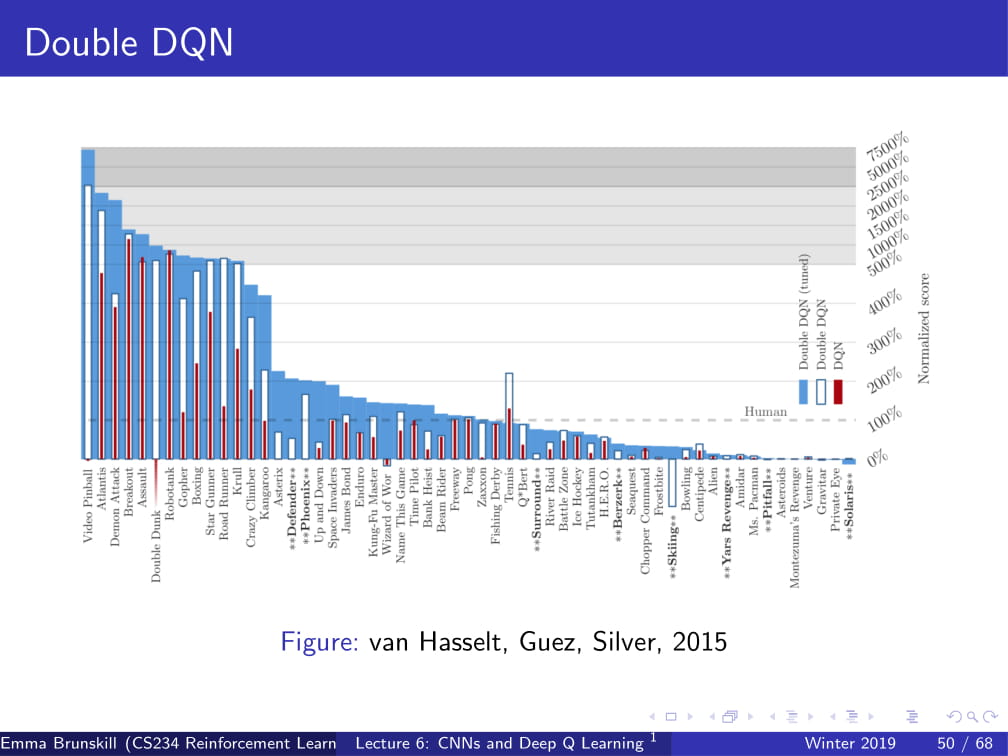
그래서, Double DQN을 사용하면, 위와 같이 좋은 결과를 낼 수 있다.

두 번째 방식은, 바로 Prioritized Replay이다.
말 그대로, Experience Replay를 그냥 막 골라서 하지 말고, 우선순위를 정해서 하자는 것이다.

이쯤, Mars Rover 예시를 다시 들어보자.
(지금까지 엄청 자주 설명했고, 위에도 잘 나오니 자세한 설명은 생락하겠다.)
그래서 위 예제에서 (s3, a1, 0, s2, a1, , s2, a1, 0, s1, a1, 1, terminal) 에피소드를 지난 뒤에, TD estimate는 어떻게 되는가?
한 번 update를 해 주면, 결국 reward가 s1, a1, 1, terminal 에서 나왔으므로 결국 [1 0 0 0 0 0 0]이 된다. (bootstrapping)
이제 여기서 replay를 두 번 진행할 수 있다고 할 때, 어떤 step을 replay하는 것이 가장 좋을까?
(오른쪽 위가 replay buffer가 저장되어 있는 모습이다.)
만약 (s3, a1, 0, s2) 버퍼를 사용해서 replay 한다면, 아무런 의미도 없을 것이다.
결국 지금 상태는 [1 0 0 0 0 0 0]이고, s3, s2는 reward가 0이므로, 아무런 영향도 미치지 않는다.
(s2, a1, 0, s2)를 선택하는 경우에도 마찬가지로, s2는 reward가 0이므로 아무런 영향도 미치지 않는다.
(s2, a1, 0, s1)을 선택하는 경우만 다르게 적용된다. 현재 s1이 1이므로, 이 reward 1은 그대로 s2에 전달되게 된다. (α=1)
그러면, 결국 TD estimate는 [1 1 0 0 0 0 0]이 된다.
그 다음엔?
만약 (s3, a1, 0, s2) 버퍼를 사용하면, s2의 reward가 1이므로, s3에도 그 reward가 그대로 전달되므로,
TD estimate는 [1 1 1 0 0 0 0]이 된다.
이렇게, 한 episode에서 최소의 replay buffer만을 사용하여 최적의 TD estimate를 얻어냈다.
만약 위처럼 우리가 replay buffer를 선택하지 않고 그냥 아무런 replay buffer나 사용하였다면, 이렇게 결과가 잘 나오진 못했 을 것이다.
위에서 아무런 영향을 주지 못한 replay는 결국 연산 횟수만 증가시키는 꼴이 되기 때문이다.
즉, 이렇게 replay buffer를 선택하는 과정은 update 효율을 굉장히 증가시켜 준다는 사실을 알 수 있다.

위에서 봤듯이, TD-learning에서는 replay의 순서가 학습의 속도를 늘리는 데 도움을 줄 수 있다.
아무런 쓸데 없는 정보가 담긴 버퍼를 사용하는 것 보다, 쓸데 있는 버퍼를 사용하는 것이 더 좋다는 것인데...
그런데, 어떻게 replay buffer의 우선순위를 정해야 할까?
위처럼 하나하나 넣어봐서 가장 좋은 버퍼를 고르는 것은 매우 비효율적일 것이니 말이다.

(대충 Episodic Replay Update의 순서를 정하는 것이 convergence를 빠르게 한다는 내용)

그래서 우리가 사용할 방법은 DQN error을 사용하는 방법이다.
어떤 tuple (replay buffer)를 골랐을 경우의 TD error와 현재 error의 차이가 가장 큰 것의 우선순위를 크게 잡아두는 것이다.
왜 이렇게 하냐고? 직관적으로 바라보자면...
만약 TD error가 현재의 error와 같다면 어떨까?
지금 선택한 replay buffer가 error에 아무런 영향을 끼치지 않는다는 이야기가 되므로, 정말 아무런 쓸데 없는 연산이 된다고 할 수 있다.
아까 위에 예시에서 아무런 영향을 끼치지 못하는 버퍼가 바로 이런 것들이다.
반면, TD error가 현재의 error와 크게 차이가 난다면?
그 버퍼가 바로 우리가 미처 제대로 습득하지 못한 데이터일 가능성이 커지게 되는 것이다.
그래서 이런 방식으로 replay buffer의 우선순위를 결정할 수 있다.
그럼 한 가지 질문만 던져보자. 만약 α=0이라면 어떻게 replay buffer가 선택이 될까?
α=0이라면, 저번 step에서 일어난 일이 현재 step까지 어떤 영향을 끼치지 못하게 되는 꼴이므로,
모든 TD-error과 현재 error의 차이가 동일하게 정해지게 된다.
그렇기에, replay buffer는 그냥 랜덤하게 결정되게 된다.

위는 Prioritized replay 방식과 double dqn 방식을 사용했을 때의 효과를 나타낸 그래프이다.
그냥.. 그렇다구...

다음으로, Dueling DQN이라는 방식이 있다.

이 방식의 요점은, optimal Q를 선택할 때 현재 state의 value와 action을 따로따로 생각한다는 점이다.
여기서 Advantage Function이 나오는데, 이는 Q(s, a)에서 V(s)를 뺀 값으로, 현재 action을 선택했을 경우 다른 action을 선택했을 때 보다 얼마나 더 좋은 결과를 내보내는지를 의미한다.
즉, 현재 Vπ(s)값에 비례한, action에 따른 상대적인 Value값을 의미한다.
개인적으로 이 부분 이해가 힘들었으므로 더 적어두자면, (사실 나중에 까먹었을때 볼라구 ㅎㅎ)
Vπ(s)는 policy를 따를 때, 그 state에서의 Value의 평균이다.
그리고 Qπ(s, a)는 각각의 action a를 따를 때 나오는 Value이므로,
결국 모든 action에 대한 Qπ(s, a) - Vπ(s) = 0이다.
여기서, 만약 Qπ(s, a)의 값이 Vπ(s)보다 크다면, 현재의 state에서 일반적으로 나올 수 있는 Value보다 더 좋은 Value를 얻은 action을 선택했다는 의미가 된다.
게임을 예시로 들어보자면,
현재 점수가 Vπ(s)인 것이고, Qπ(s, a)는 다음 action a를 취했을 때의 점수인 것이다.
만약 Advantage Function을 사용하지 않고 그냥 Qπ(s, a)만 본다면,
게임 후반의 점수가 게임 초반의 점수보다 당연히 더 높을 것이므로 게임 후반의 Q(s, a)값만 바라보고, 그 action을 취하는 데에 치중하게 될 것이다.
하지만 만약 Advantage Function을 사용하면, 게임 초반이나 후반이나 상관없이 내가 이 action을 취했을 때 얼마나 잘 플레이 한 것인지 알 수 있게 된다.

다음은 Dueling DQN의 아키텍쳐이다.
원래 DQN에서 마지막에 Q(s, a1), Q(s, a2) ...의 값이 나왔다면,
Dueling DQN에서는 마지막에 V(s), A(s,a1), A(s,a2)의 값들이 따로 나오고,
이 값들을 합쳐서 Q(s, a1), Q(s, a2)의 값을 얻어내는 것이다.


위 두 슬라이드는 영상에서 교수님이 설명을 안하셨다.
그러니 이해하고 싶으면 ppt를 보고 이해해야 된다.
난 못했으니 그냥 넘어간다.

Dueling DQN은 굉장히 효율이 좋은 학습 방식이고, 이는 위 그래프로 설명이 가능하다.

지금부터는 이 DQN을 실제 적용할 때의 팁들이다.
- DQN은 다른 방식들보다는 더 믿을만한 방법이다. Pong은 그중에서도 좀 믿음직 스러운 게임인데, 만약 DQN을 Pong에 적용시켰는데 뭔가 잘 안된다면, 너가 뭔가 잘못 한 것이다.
- DQN에서 replay buffer는 크면 좋으므로, 메모리 효율이 매우 중요하다. 데이터를 막 중복해서 쌓지 말고, uint8 이미지를 사용하라.
- DQN은 굉장히 천천히 Converge 하므로, 참을성 있게 기다려라.
아타리의 경우 천만~4천만 프레임 동안 기다려야지 random policy보다 훨씬 더 좋은 결과를 얻을 수 있는데,이는 GPU에서 훈련시킬 때 두시간 정도에서 하루 종일이 걸릴 정도의 양이다.
- 그리고 나중에 Atari를 실제로 학습시키려고 할 때, 작은 test environment에서 디버깅 꼭 해봐라.
이거 안하고 그냥 Atari에 때려 박았다가 잘 안되면 시간 날려먹는거니깐.

(이 ppt는 그냥 영상에서도 거의 거르다시피 함 - 알고 있거나 이해한 부분만 써놓음)
- Bellman error에서 Huber loss를 시도해 보아라. (위 식 참고)
- Double DQN을 써 보자 - 코드는 별로 안 바꿔도 되는데 성능 차이는 크게 난다.
- Learning rate scheduling은 꽤 좋다. 처음 exploration period에는 learning rate를 크게 잡아 놓아라.
이렇게 DQN에 대한 설명은 끝!
다른 강의들과는 조금 다르게 수학적으로 파고드는 것 보다 아이디어를 설명하는 강의였던 것 같다.
'인공지능 > 강화 학습 정리 (CS234)' 카테고리의 다른 글
| 강화학습 강의 (CS234) 8강 - Policy Gradient (1) | 2019.10.22 |
|---|---|
| 강화학습 강의 (CS234) 7강 - Imitation Learning / Inverse RL (1) | 2019.08.26 |
| 강화학습 강의 (CS234) 5강 - Value Function Approximation (4) | 2019.05.27 |
| 강화학습 강의 (CS234) 4강 - MC / SARSA / Q-learning (1) | 2019.05.08 |
| 강화 학습 강의 (CS234) 3강 - Model-Free Policy Evaluation (Monte Carlo / Temporal Difference) (3) | 2019.04.21 |