딥러닝
-
텐서플로우 - Linear regression 코드 정리2019.04.03
모두를 위한 딥러닝 (sung kim) lec5 - Logistic Classification (로지스틱 회귀분석)

이번 포스팅에서는, Logistic (regression) classification에 대해 알아볼 것입니다.
(왜 중간에 (regression)이 있는지는 나중에 다룰게요!)

우선 Logistic (regression) classification이 정확히 뭔지 알아보기 전에, 일단 Binary Classification이 뭐였는지 먼저 알아봅시다.
Binary Classification은 두개로 이루어진 값들을 분류하는 작업입니다.
가령 스팸메일 필터링을 한다고 했을 때는, 이 메일이 스팸인지 그냥 메일인지 확인해야 하겠죠?
이 때 이 메일을 스팸인지/그냥 메일인지 두 가지중 하나로 분류하는 작업을 바로 Binary Classification이라고 합니다.

그런데 이런 작업을 할 때, 어떤 메일이 스팸인지 / 그냥 메일인지 구분할 때 0과 1로 인코딩 작업을 거칩니다.
가령 스팸이면 1, 그냥 메일이면 0으로 두는 것이죠.
그런데 왜 이렇게 인코딩을 할까요?
왜 이러는지는 regression의 성질을 생각하면 조금 이해가 될 듯 합니다.
(우리가 배우는 모델은 classification 작업에 사용될 뿐이지, 엄연히 regression모델입니다!!!)
저번 시간까지 배웠던 linear regression의 결과값은 어떻게 나왔나요?
가령 성적을 예측하는 regression모델이라고 한다면, 예측한 점수를 결과값으로 내게 될 것입니다.
이렇듯, regression모델은 특정한 '값'을 '예측'하는데 사용됩니다.
그렇기 때문에 이런 regression 모델로 분류를 진행하려면, 이런 class들을 (스팸인지 아닌지) '값'으로 설정해야 합니다.
스팸 메일은 1, 그냥 메일은 0.. 이렇게 말이죠.
그리고 그렇게 예측한 값이 1에 가깝다면 스팸메일이다! 라고 예측을 하고,
예측한 값이 0에 가깝다면 진짜 메일이다! 라고 예측을 하는 겁니다.

그런데, 그럼 그냥 Linear regression 모델을 그냥 사용하면 안되는 걸까요? 안되니깐 다른 모델을 배우는거겠죠?
자, 위의 예시를 봅시다.
위의 그래프는 x축에 공부한 시간, y축에 pass / fail (1 / 0)이 그려진 그래프로,
공부한 시간 비례 시험에서 통과할지 실패할지 예측하는 모델을 그린 것입니다.
그럼 이것을 Linear regression모델로 짤 수도 있지 않을까요?
fail 과 pass를 나누는 직선 하나를 그린 뒤에,
그 직선의 y값이 0.5 이하이면 fail, 아니면 pass라고 하면 잘 작동할것 처럼 보이기도 합니다.
그런데, 저 오른쪽 끝부분 (아래에 50적혀있는) 의 동그라미를 봅시다.
만약 어떤 학생이 정말 시험에서 너무 pass하고 싶어서 50시간이나 공부를 해서 pass를 받았다고 가정해 봅시다.
그러면 어떤 문제점이 발생하느냐 하면,
linear regression의 Hypothesis H(x) = WX + B 함수가 저 오른쪽의 동그라미도 감안하고 측정이 되므로,
저 동그라미가 없을때보다 직선이 조금 더 오른쪽 아래로 기울어지는 현상이 발생합니다.
그런데 이렇게 되면 원래는 pass였던 것들의 y값이 0.5 아래로 내려가버리면서 fail로 처리되는 문제가 발생하게 됩니다.
(위의 그래프에 그려진 파란 직선 두개 참고)
이렇듯, Binary classification (사실 classification 전체 다)를 수행하는 데 Linear Regression 모델은 적합하지 못합니다.

Linear regression을 사용하기 애매한 이유가 또 있습니다.
Linear regression의 경우 Hypothesis 함수를 H(x) = Wx + b 로 정의합니다. 그쵸?
그런데 어차피 y값들 (class, 스팸인지 아닌지)는 0이거나 1이 된다는 것을 우리는 이미 알고 있습니다.
(0, 1 인코딩을 이미 했고, 그렇게 분류하는것이 binary classification의 목적이니까요.)
그런데 Linear regression의 H(x)는 1보다 엄청 큰 수를 결과값으로 뱉을 수도 있고, 0보다 엄청 작은 수를 결과값으로 뱉을 수 있습니다.
가령 H(x) = 100x 라는 hypothesis가 있다고 해봅시다.
우리의 목적은 데이터들을 0과 1 둘중 하나의 값으로 분류하는 것이 목적이므로,
1에 가까운 값은 1로 분류하고, 0에 가까운 값은 0으로 분류하게 될 것입니다.
그런데 H(x) = 100x가 되버리면 (대략적으로) x가 0.01 이상일때는 모두 1로, x가 0 이하일때는 모두 0으로 분류되게 됩니다.
이러면 어떤 문제점이 발생해 버리냐하면, x값에 너무 민감하게 반응하는 모델이 만들어지게 됩니다.
즉, 연산상으로는 매우 작은 값(0.01)만 바뀌어도 아예 분류 자체가 바뀌어버리게 되는 것입니다.
이는 아까 위에서 설명했던 문제와 겹치며 linear regression 모델을 classification을 하는 용도로 사용하기 힘들게 만듭니다.

이를 해결하기 위하여 나온 것이 바로 logistic function (sigmoid function 이라고도 한다) 입니다.
원래 linear하던 H(x) = wx + b를 0과 1 사이의 함수로 바꿔주는 함수입니다.
수식으로 나타낸다면, g(z) = 1 / (1+ e^-z) 가 됩니다.
이렇게 hypothesis에 sigmoid 함수를 씌워주면, 무슨 함수였던지간에 결과값이 모두 0과 1 사이로 나오는 함수를 만들어 줄 수 있습니다.
(왜 이런 값이 나오는지 수학적으로 설명하는 것은 나중에 부록 편에서 다루겠습니다.)

그리고 이것을 Logistic regression의 Hypothesis로 나타낸다면 위와 같은 수식으로 나타내어 집니다.
(W T X 는 그냥 간단하게 W * X로 생각해 주시면 됩니다.
multi-variable의 경우에서도 사용할 수 있도록 만든 hypothesis인지라 저런 식이 들어갑니다.)
그리고 이렇게 H(x)의 값이 0과 1사이로 나오면, 사용하기에 매우 편리해 지게 됩니다.
위의 Hypothesis 함수로 regression을 한 결과값이 0.5이상인 경우엔 1로 분류하고, 0.5보다 작으면 0으로 분류하면 되는 것이죠.
(사실 아까 전에 0,1 encoding을 한 이유도 이것 때문입니다.)
*참고 : Logistic "Regression" 인 이유!
많은 분들이 왜 이 모델이 Regression 모델인지 헷갈려 하곤 합니다.
그러니까, Logistic regression은 사실 classification을 하는데 사용하는데, 왜 regression이라고 불리는가를 헷갈려 하는 것이죠.
하지만 Logistic regression모델은 결과값이 0과 1 사이로 한정되는 특성상 classification을 하는 데 사용되는 모델이긴 하지만, 결과값으로 특정한 "값"을 도출해내는 모델입니다.
가령, 성적을 예측하는 Linear regression은 점수 그 자체를 결과값으로 도출합니다. (10점, 30점, 60점 등등...)
그와 비슷하게 스팸 메일인지 아닌지를 분류하는 Logistic regression 모델은 0과 1 사이의 값 자체를 결과로 냅니다. (0, 0.2, 0.8 등등...)
그러니까, Logistic Regression은 입력값 x에 대해 0과 1로만 이루어진 y값에 최대한 가깝게 그려질 수 있는 함수를 만들어내는 모델인 것입니다.
그리고 결과값이 0.5보다 큰 (즉, 1에 가까운) 값들은 죄다 1로 분류해 버리는 것이고,
결과값이 0.5보다 작은 (즉, 0에 가까운) 값들은 죄다 0으로 분류해 버리는 것입니다.
그러니깐 그냥 이제부터 Logistic (regression) classification이 아니라
logistic regression모델이라고 부르겠습니다.

그런데, 이렇게 Hypothesis를 바꿔버리면 원래 쓰던 cost function은 사용하지 못합니다.
왜냐 하면, 원래 쓰던 Cost function을 여기다가도 적용해버리면 non-convex한 function이 나오게 되기 때문입니다.
(cost function이 convex function이어야 하는 이유는 2강 (https://cding.tistory.com/21) 에서 다뤘습니다!)
+ 왜 그렇게 되는지는 나중에 부록편에서 따로 더 설명하겠습니다.
그래서 logistic regression의 cost function은 따로 만들어 줘야 합니다.
logistic regression의 cost function은 다음과 같이 정의합니다 :
y=1일때 c(H(x), y) = -log(H(x))
y=0일때 c(H(x), y) = -log(1 - H(x))
(단, 여기서 log는 상용로그가 아니라 자연상수 e를 밑으로 갖는 자연로그입니다.)
그런데 왜 cost function을 이렇게 정의했느냐를 제대로 설명하려면 엄청난 수학의 압박이 느껴지게 됩니다...
그러니 일단 지금은 직관적으로 왜 cost function을 이렇게 정의하는지만 알아봅시다.

그냥 지금 간단하게 생각해 봅시다.
(위의 그래프들은 x축에 h(x)값, y축에 cost 값을 나타내는 그래프입니다!!)
일단 y=1인 경우, 즉 h(x) = 1인 경우엔 왜 cost function은 -log(H(x))가 될까요?
(왼쪽 그래프 참고)
h(x)값이 0에서 1으로 이동하면 cost 값은 ∞에서 0으로 점점 줄어들게 되는 것을 확인할 수 있습니다.
즉, h(x)가 정답인 1로 가면 갈수록 cost는 줄어들고, 오답인 0으로 가면 갈수록 cost가 늘어납니다.
이러면 우리가 원하는 합리적인 cost function이 완성된 것이겠죠?
반대로, y=0인 경우, 즉 h(x) = 0인 경우에 cost function이 -log(1-H(x)) 인 이유도 동일합니다.
h(x)값이 1에서 0으로 이동하면 cost 값은 ∞에서 0으로 점점 줄어들게 되는 것을 확인할 수 있습니다.
즉, 이번에는 h(x)가 정답인 0로 가면 갈수록 cost는 줄어들고, 오답인 1으로 가면 갈수록 cost가 늘어납니다.
그냥 이정도로만 이해해 주시고, 왜 cost function을 이렇게 설정했는지는 나중에 부록 편에서 다루겠습니다.

그리고 위처럼 y=1일때와 y=0일때로 나누어도 좋겠지만,
직접 컴퓨터로 연산을 할 때는 간단한 수식으로 나타내는 것이 훨씬 좋겠죠?
그래서 나온 공식의 위의 파란 박스가 쳐진 수식입니다.
어려울것 하나 없습니다!
y=0일 때는 -y * log(H(x)) 부분이 0이 되면서 자연스럽게 -log(1 - H(x)) 라는 cost function이 나오게 되고,
y=1일 때는 (1-y) * log(1 - H(x)) 부분이 0이 되면서 자연스럽게 -log(H(x)) 라는 cost function이 나오게 됩니다.
그리고 컴퓨터로 연산을 할 때는 if문을 사용해서 y==1인 경우와 y==0인 경우로 나누지 않고,
그냥 위의 수식을 사용하게 될 것입니다.

(위의 ppt의 Gradient decent는 오타입니다...ㅎㅎ;)
Gradient descent는 그냥 다른 모델과 동일하게 cost(W)를 W에 대해 미분하는 것으로 적용하면 됩니다.
그리고 이를 tensorflow를 사용해서 코드로 적용할 때는 그냥 GradientDescentOptimizer(a) 로 적용하면 됩니다.
(실제 cost값을 미분하면 어떤 값이 나오는지는 그냥 설명하지 않겠습니다. 매우 불필요합니다. 부록에서도 설명 안할듯)
이렇게 Logistic regression에 대해서 알아봤습니다.
사실 이렇게만 설명해도 Logistic regression이 어떤 개념인지는 모두 이해하셨으리라 믿지만,
나중에 부록편에서 조금 더 수학적으로 접근해서 왜 cost function이 저렇게 나오는지 설명하겠습니다.
그럼 다음엔 softmax regression (multinomial classification)으로 찾아뵙겠습니다!
'인공지능 > 모두를 위한 딥러닝 (sung kim) lec' 카테고리의 다른 글
| 모두를 위한 딥러닝 부록편 - 미분의 개념과 Gradient Descent (1) | 2019.05.10 |
|---|---|
| 모두를 위한 딥러닝 (sung kim) lec4 - Multivariable Linear Regression (다변수 선형 회귀) (1) | 2019.04.09 |
| 모두를 위한 딥러닝 (sung kim) lec3 - Gradient Descent (경사하강법) (0) | 2019.04.08 |
| 모두를 위한 딥러닝 (sung kim) lec2 - Linear regression & cost function (0) | 2019.03.30 |
| 모두를 위한 딥러닝 (sung kim) lec1 - 머신 러닝 기초 (0) | 2019.03.28 |
강화 학습 강의 (CS234) 3강 - Model-Free Policy Evaluation (Monte Carlo / Temporal Difference)

- 본 포스팅은 CS234 3강의 내용을 정리합니다.

CS234 3강에선, MDP 모델 없이 Policy Evaluation하는 법에 대해 다룬다.
주로 다루는 내용은,
- Dynamic Programming
- Monte Carlo policy evaluation
- Temporal Difference(TD)
등이 있다.

저번 시간에 Dynamic Programming으로 Policy π에 대한 Evaluation에 대해 배운 바 있다.
k번째의 horizon에서 정확한 value값을 뽑아낸다고 할 때,
이 k의 값을 Value 값이 ||Vₖπ - Vₖ₋₁π|| < ε 로 수렴할 때 까지 증가시켜
infinite horizon의 value값을 찾아내는 방법이다.
이것을 그림으로 조금 더 자세히 알아보도록 하자.

위 그림은 State s에서 특정한 action들을 취하는 것을 트리형 구조로 나타낸 것이다.
State s에서 특정 Action을 취했을 때, 어떠한 state로 가게 되고
그 후에 또 Action을 취한 후 특정한 State로 가게 되고 ... 을 반복하게 된다.
Policy Evaluation에서 원하는 것은, 저 Action을 취했을 때 받는 Reward의 총 합을 얻는 것이다.
(바로 앞의 Action에서뿐만 아니라, 그 뒤에 일어날 것들을 포함한, discounted value를 의미함.)

DP 방식은 이전에 계산해 뒀던 Vₖ₋₁π의 값을 통해 Vₖπ의 값을 구한다.
이 때, DP 방식은 World의 Model인 P(s' | s, a)를 알고 있기 때문에
정확한 Vₖπ의 값을 구할 수 있다. (어떤 Action을 했을 때 어떤 reward가 들어오는지 정확히 알고 있으므로.)

즉, 여기서 알 수 있는 점은 Dynamic Programming (DP) 방식은 MDP 의 모델인 M을 필요로 한다는 것이다.
이 모델 없이는, DP는 돌아갈 수 없다.
그런데, 만약 dynamics model P 나 reward model R을 모른다면 어떻게 해야 할까?
이제부터, model없이 Policy evaluation을 하는 방법을 알아보도록 하자.

Gt와 Vπ(s)는 위의 슬라이드를 참고해서 보도록 하자.
Monte Carlo 방식은 모든 Action에 대한 Value를 평균을 내면 그 state의 value를 알 수 있다는 아이디어로 시작되었다.

만약 한 State에서 도달할 수 있는 길이 유한하다면, 그 길들을 sample을 내서 그 return의 평균을 내는 방법이다.
MDP dynamics / model이 필요하지 않다. (그냥 가능한 경우의 수를 평균낸 것이므로)
또한, DP처럼 bootstrapping (한 구간에서 계속해서 반복하는 것?) 하지 않는다.
그리고 state가 Markov하다는 가정을 하지 않는다.
결국 Monte Carlo 방식은 경험에 의존한 방법이므로, 과거에 Agent가 받았던 reward와 action등에 의해 Value가 결정되기 때문이다.
하지만, episodic MDPs (반복 가능하고 언젠간 끝나는 MDP. 예시 : 게임 Pong)의 경우에만 사용 가능하다.
여기서 episode란, 한 번의 순환을 의미한다. 가령 게임 Pong의 경우, 한번의 게임이 끝나는 것이 하나의 episode이다.

First-Visit Monte Carlo란, 처음 방문한 state의 경우에만 V를 update하는 방식이다.
N(s) (state의 방문 횟수)와 G(s)를 모든 s에 대하여 0으로 초기화해 준 다음
episode i를 위처럼 정의하고, (state s1에서 action a1을 하고 reward r1을 받고 s2로 가서 a2를 하고 r2를 받고 ... 언젠가 Terminate되고 끝)
Gi,t를 각각의 reward의 total discounted value라고 할 때,
처음 state를 방문하는 t의 경우에만 Vπ(s)를 update해준다.
가령, 내가 방문한 state가 s1, s1, s2, s2, s2, s3, s3, Terminate 순서라면,
각각 첫번째 s1,s2,s3 (1, 3, 6번째)의 경우에만 작동을 하고, 그 외의 경우에는 그냥 값을 무시하고 지나가게 된다.
(아래 예시가 나온다. 곧...)

더 자세히 들어가기 전에, Bias, Variance, MSE가 무엇인지 빠르게 알아보도록 하자.
참고로 위 용어들은 통계학 용어들이므로, 이번 포스팅에서는 그 자세한 내용은 생략하겠다.
(참고자료 - 추정량 위키백과 https://ko.wikipedia.org/wiki/%EC%B6%94%EC%A0%95%EB%9F%89)
간단하게 이야기하자면,
Bias(편향)는 예측한 값이 얼마나 한쪽으로 치우쳐져 있는가를 의미하고,
Variance(분산)는 예측한 값이 실제 측정치와 얼마나 떨어져 있는가를 의미하고,
MSE(Mean Squared Error)는 그 둘을 조합해놓은 것이다.

위 내용들을 갖고 다시 Fist-Visit Monte Carlo로 돌아오자.
Vπ의 estimator θ^은, unbiased(bias가 없는) 실제 [Gt|st = s]의 기댓값이다.
그리고 큰 수의 법칙에 의해서, N(s)가 무한대로 발산하면, 그에 따라 Vπ(s)는 실제 값에 수렴하게 된다.
(참고 : 큰 수의 법칙 https://ko.wikipedia.org/wiki/%ED%81%B0_%EC%88%98%EC%9D%98_%EB%B2%95%EC%B9%99)
하지만, 데이터 대비 비효율적이라는 단점이 존재한다.
가령, time step이 10000이 지나가도 똑같은 state만 지났었다면 그 episode에서 얻을 수 있는 정보가 1개밖에 없고
그 값으로만 Vπ를 개선하는 방식인 것이므로,
각각의 time step에 대한 데이터가 10000개가 들어와도 거기서 쓸만한 정보를 하나밖에 구해오지 못하는 것이다.

Every-Visit Monte Carlo 는 First-Visit Monte Carlo에서 약간의 변화를 준 방식이다.
이름만 봐도 알겠지만...
First-Visit Monte Carlo 방식은 State를 처음 방문했을 때에만 Vπ를 update해주었지만,
Every-Visit Monte Carlo 방식은 State를 방문할 때 마다 Vπ를 update해준다.
이 방식은 biased한 방식인데...
직관적으로 보았을 때, 한 episode에서 state 하나를 딱 한번만 뽑는다면 (First-Visit Monte Carlo의 경우엔)
G(s) = 0 + Gi,t가 되므로, 어떤 경우에서든 G(s)는 독립적인 변수가 될 것이다.
하지만, 만약 한 episode에서 state가 여러번 나온다면, (Every-Visit Monte Carlo의 경우엔)
G(s)는 다른 time t에서의 G(s)와 상관관계가 생기게 된다.
결국, Every-Visit Monte Carlo의 방법은 그 상관관계가 어느 정도 존재하는 것들을 평균을 내게 되는 것이므로,
상관관계가 높은 쪽으로 어느정도 치우쳐지게 될 것이다. (그래서 biased 해진다.)
그러나 이 Every-Visit Monte Carlo로 얻는 추정량은 일치 추정량이어서, 데이터를 많이 얻으면 얻을수록
실제 추정치에 수렴하게 된다.
그래서, 이 방식은 First-Visit Monte Carlo에 비해 훨씬 더 낮은 Variance를 갖게 된다.
그리고 경험적으로, 이렇게 나온 값이 거의 확실히 First-Visit Monte Carlo보다 MSE가 낮다. (더 좋다는 뜻이다.)


또, Incremental Monte Carlo에 대해 생각해 볼수도 있다.
Vπ(s)는 위 ppt의 방식으로 계산하여, 그 다음 ppt의 방식으로 바꿔줄 수 있다.
이 때, α가 1/N(s)라면 every visit Monte Carlo와 아예 동일한 방식이 되고, (Vπ(s) = Gi,t와 같아지므로)
α가 1/N(s)보다 크다면 오래된 data를 잊게 되는, discount factor와 약간 비슷한 느낌이 된다.

First-Visit MC 방식과 Every-Visit MC방식을 사용했을 때 V의 예측치를 찾는 문제이다.
저번 시간부터 사용해왔던 Mars rover의 예제를 다시 들고 와서
𝛾=1, R=[1,0,0,0,0,0,10]이라고 하고,
(s3, a1, 0, s2, a1, 0, s2, a1, 0, s1, a1, 1, terminal)의 방식으로 움직인다고 가정할 때,
각각의 state에서 First Visit MC의 V의 예측값은 무엇인가?
또, state s2에서 Every-Visit MC의 V의 예측값은 무엇인가?
First-Visit의 경우 각각 첫 번째 s3, s2, s1에서만 Value를 예측하고,
𝛾=1이므로 V(s1) = 1, V(s2) = 1, V(s3) = 1, 그 외 나머지 state에서는 V(s)는 0이 될 것이다.
Every-Visit의 경우도 이와 마찬가지이다.
V(s1)=1이고, s2는 두번 나오지만 V(s) = G(s) / N(s) 이므로 2/2 = 1, 즉 V(s2) = 1이 된다.

이를 아까 DP처럼 트리형 구조로 나타낸다면,
DP는 맨 위에서만 Bootstrapping을 하던 반면,
MC는 가능한 경우의 수를 샘플을 내어 평균을 내서
그 값을 reward의 예측값으로 사용하게 된다.

Monte Carlo방식의 한계점들은 다음과 같다.
- 일반적으로 variance가 높은 편이다. 이를 줄이기 위해선 많은 데이터가 필요하다.
- episodic setting이 필요하다. episode가 끝나야지만 Vπ(s)가 update되기 때문이다.

다음은 MC의 요약본이다.
위의 내용을 잘 숙지하고 넘어갈 수 있도록 하자.

다음으로 배울 내용은 TD learning이다.
이 방식은 위의 Monte-Carlo 방식과 비슷하게 Model이 필요없다.
또, DP와 같이 Bootstrap 하면서도 MC와 같이 sample을 내기도 하며,
episodic하건 infinite-horizon / non-episodic 하건 사용가능하며,
각각의 (s, a, r, s') (state, action, reward, next_state) 튜플이 지나갈 때 마다 V의 예측값을 업데이트 해 준다.
(각각의 time step마다 update한다는 뜻)

저번 시간에 잠깐 했던 벨만 방정식 (Bellman operator)을 다시 가져오자면,
Vπ(s) 는 현재 immediate reward r(s, π(s)) 와 discounted sum의 합이었다.
그리고 every-visit MC에서, Vπ(s) = Vπ(s) + α(Gi,t - Vπ(s)) 라고 정의했었다.
이 때, Gi,t를 계산하기 위해선 episode 하나를 통째로 끝날 때 까지 기다려야 했다.
그런데, 그냥 이 Gi,t를 Bellman operator로 바꾸어서, rt + 𝛾Vπ(st+1)라고 두면 어떨까?
즉, DP와 같이 다음 reward를 계산할 때, 이미 갖고 있는 데이터를 바탕으로 계산하자는 것이다.
어렵게 생각할 것 없이, 그냥 저번에 했던 DP의 방식을 조금만 차용했을 뿐이라고 생각하면 된다.
실측값인 Gi,t는 state가 Markov 하다면 Bellman Operator와 동일하게 성립하지 않겠는가?

이것을 알고리즘으로 나타내면 다음과 같다.
α값을 input으로 준 뒤에, (내가 선택하면 된다.)
모든 state에 대해 Vπ(s) = 0으로 초기화 한 뒤,
(st, at, rt, st+1) 튜플을 샘플링 하여
이 튜플을 바탕으로, 아까 제안했던 TD 공식을 사용하여
Vπ(st) = Vπ(st) + α(rt + 𝛾Vπ(st+1) - Vπ(st)) 를 그대로 반복하는 것이다.

빠른 이해를 위해, 바로 예제로 들어가보자.
아까 전과 같이 Mars rover예제로, R = [1 0 0 0 0 0 10]이라고 가정하고
s1이나 s7에 도달하면 그 뒤에 무조건 episode가 terminate 된다고 하자.
이 때, (s3, a1, 0, s2, a1, -, s2, a1, 0, s1, a1, 1, terminal) 의 튜플이 주어질 때, (ppt 오른쪽 위에 쓰여진 대로 수행된다.)
α=1에서의 TD 예측치는 무엇인가?
이를 식으로 잠시 나타내어
Vπ(st) = Vπ(st) + α(rt + 𝛾Vπ(st+1) - Vπ(st))를 위 상황에 대입하면,
α, 𝛾 모두 1이므로
Vπ(st) = Vπ(st) + rt + Vπ(st+1) - Vπ(st)
= rt + Vπ(st+1)가 된다.
모든 state s에 대해 Vπ(st) = 0으로 초기화 했으므로,
Vπ(s3) = rt + Vπ(s2)
-> Vπ(s3) = 0 + 0 = 0
Vπ(s2) = rt + Vπ(s1)
-> Vπ(s2) = 0 + 0 = 0
Vπ(s1) = rt + Vπ(terminated)
-> Vπ(s1) = 1 + 0 = 1
즉, Vπ(s1)=1, 그 외 나머지 state 에서 Vπ(s) = 0이 된다.
이것이 TD Learning과 MC의 차이점인데,
MC의 경우 Vπ(s3)를 계산할 때 모든 경로를 끝까지 계산하여, s1에 도달했을 때의 그 값 또한 Vπ(s3)의 값에 넣어두지만,
TD Learning은 그냥 s3에서 s2로 한번 간 순간 이미 Agent가 s3에 있었다는 정보를 바로 버리게 된다.
그렇기 때문에 TD learning은 추후에 s1에 도달하더라도 s3의 값에는 변화를 주지 않는다.
그리고 그렇기 때문에 TD learning은 Monte Carlo와는 다르게 episodic 하지 않아도 되는 것이다.
어차피 끝까지 가지도 않고 바로 앞에서 무슨 일이 벌어지는지만 bootstrapping하여 알아내기 때문이다.
+ 위 경우엔, α=1이었기에 아무리 반복해도 딱히 변하지를 않았지만,
α=1이 아닌 경우엔, 지속적으로 반복하면 Vπ(s2), Vπ(s3)의 값들도 조금씩 변화하며
계속 반복하게 되면 일정 값에 수렴하게 될 것이다.
가령, α=2의 경우엔,
Vπ(st) = Vπ(st) + 2 * (rt + Vπ(st+1) - Vπ(st))
= 2 * (rt + Vπ(st+1)) - Vπ(st) 가 된다.
이 때는 Vπ(st)의 값들이 어떻게 바뀌는지는, 직접 해보며 익히길 바란다.
++ 참고로, α=1인 경우의 TD update Vπ(st) = rt + Vπ(st+1)는 TD(0)이라고도 한다!

이를 트리형 구조로 나타내면 다음과 나타낼 수 있다.
TD는 value를 예측하기 위해 st+1을 샘플링 하여 기댓값의 근사값을 찾아내고,
V(st+1)의 예측치를 활용하여 DP와 비슷하게 bootstrapping하여 value를 update한다.
일종의 MC와 DP의 짬뽕 느낌이 확 들지 않는가?

그럼, 이제부터 DP, MC, TD의 속성들을 비교해보자.
- model 없이 사용 가능한가?
우선, DP는 무조건 MDP가 필요한 방법이므로 X
MC, TD는 경우의 수를 샘플링 하는 방식으로 진행되므로, model-free하다. O
- non-episodic한 경우 사용 가능한가?
MC의 경우 episode 한번이 끝날때 마다 update하는 방식이므로, 무조건 episodic한 경우여야 한다. X
DP, TD의 경우 bootstrapping하여 Vπ(s)를 얻어내는 방식이므로, non-episodic / infinite episodic의 경우도 가능하다. O
- Non-Markovian할 때 사용 가능한가?
MC의 경우 그저 가능한 경우의 수를 나열하는 것이므로, Markovian하건 안하건 그냥 평균만 내면 되는 방식이다. O
DP, TD의 경우 state가 Markov하다는 전제 하에 bootstrapping을 하는 것이므로, state는 Markovian 해야 한다. X
- 극한값에서 실제 값에 수렴하는가?
DP, TD는 bootstrapping을 하면 할수록 수렴하고, MC의 경우도 episode를 무수히 반복하다 보면 큰 수의 법칙에 의해 수렴한다. O
- unbiased한가?
MC의 경우, First-Visit MC는 unbiased 하지만, Every-Visit MC는 biased하다. O
TD의 경우, bias가 있다고 할 수 있다.
가령 아까 위의 Check your understanding에서, α=2의 경우에 첫 번째 반복에선 Vπ(s1)만 reward가 1이라고 되는 편향이 생긴다.
(다르게 이야기하자면, s3, s2일 경우에 reward가 0이라는 편향값이 생긴다고 보면 될 것 같다. 즉, 정확하지 못하다는 것이다.)
DP의 경우가 제일 특이한데, Vπ(s+1)의 값은 Model을 통해 얻는 정확한 값이므로 Bias가 있다고 하기엔 애매한 감이 있다. NA

그리고, MC, TD 등의 알고리즘을 선택할 때 Bias/variance, Data efficiency, Computational efficiency와 같은 점들을 고려해야 한다.
(이 근방 부분은 나중에 더 자세히 다루겠다고 하신다.)

이번에 생각할 내용은 Batch (Offline이라고도 한다?) solution에 대한 내용이다.
K개의 finite한 episode가 있을 때, K에서 반복적으로 샘플링을 해서 MC 또는 TD(0)의 방식을 적용할 때,
MC와 TD(0)은 어떻게 수렴할까?
* TD(0)은 α=1일 때의 TD를 의미함.

다음 예시를 보도록 하자.
𝛾=1이라고 가정하자.
오른쪽 위의 노드 그림과 같은 State가 있다.
다음과 같은 8개의 에피소드가 존재한다;
- A, 0, B, 0
- B, 1 (6번 반복)
- B, 0
(이 때, A,B는 state, 0,1은 reward를 의미한다.)
이 때, MC와 TD(0)방식의 V(A), V(B)는 어떻게 수렴할까?
우선 V(B)부터 보도록 하자.
MC를 사용하면, 결국 B는 8번의 episode가 존재하고 그중 6개의 episode에서 1의 reward를 받았으므로,
V(B) = 6/8 = 3/4가 될 것이다. (무한히 많이 반복하면 이렇게 수렴하게 된다는 뜻이다!)
TD(0)를 사용하더라도 결국 sampling 후 무한정 bootstrapping하다 보면, 6/8 = 3/4로 수렴하게 될 것이다.
하지만, V(A)의 경우는 조금 다르다.
MC를 사용하게 되면, A는 언제나 A, 0, B, 0으로 갔으므로, V(A) = 0이라고 생각할 것이다.
(이 episode 들 중 A에서 출발하는 경로는 단 하나이고, 언제나 0의 reward를 뽑아냈기 때문이다.)
하지만 TD(0)를 사용하게 되면, 이야기가 조금 달라지게 된다.
TD(0)에서 사용했던 공식을 다시 한번 가져오자면,
Vπ(st) = rt + 𝛾Vπ(st+1) 였고,
𝛾=1이라고 했으므로 Vπ(st) = rt + Vπ(st+1)이 된다.
즉 Vπ(A) = rt + Vπ(st+1)
= 0 + Vπ(B)
= 0 + 3/4
= 3/4
그러므로 MC를 사용했을 때의 V(A) = 0, TD(0)을 사용했을 때의 V(A) = 3/4라는, 다른 값이 나오게 된다.

이것을 통해 MC와 TD가 Batch setting에서 수렴하는 방식의 차이를 알 수 있다.
MC의 경우는 MSE (Mean Squared Error)를 최소화하는 방식으로 수렴하게 되어,
이미 관찰된 return에 대한 오차를 최소화하는 방식이다.
TD(0)같은 경우, MDP에 최대한 가깝게 수렴하는데,
가령 P(B|A) = 1이고, r(B) = 3/4, r(A) = 0이므로 V(A) = 3/4라고 예측하는 것이다.
(이는 TD가 Markov structure을 사용하기 때문이다. MC는 Markov structure가 아니기에, MSE만을 최소화한다.)
여기까지 CS234 3강의 내용이었다.
쓰다보니 엄청나게 길게 쓴 것 같다.
여기까지 읽는 사람은 없을 것 같아서 쓰는 말이지만,
통계학 공부를 조금 더 하고 나서 인공지능을 다시 배워야될 것 같은 걱정이 들기 시작한다.
게다가 죄다 영어로 써져 있어서 직역해야 하는건지 수학 용어인지도 모르는 것들이 쑥쑥 나와서
다른 강의보다 더 쓰기 힘들었던 것 같다.
아무튼 다음 CS234 4강에서 보도록 하자.
수고링 ㅎ
'인공지능 > 강화 학습 정리 (CS234)' 카테고리의 다른 글
| 강화학습 강의 (CS234) 6강 - CNN + DQN (Deep Q Network) (0) | 2019.06.06 |
|---|---|
| 강화학습 강의 (CS234) 5강 - Value Function Approximation (4) | 2019.05.27 |
| 강화학습 강의 (CS234) 4강 - MC / SARSA / Q-learning (1) | 2019.05.08 |
| 강화학습 강의 (CS234) 2강 - Markov Process / MDP / MRP (2) | 2019.04.15 |
| 강화 학습 강의 (CS234) 1강 (1) - 강화 학습이 뭘까? / Markov란? (5) | 2019.04.06 |
모두를 위한 딥러닝 (sung kim) lec4 - Multivariable Linear Regression (다변수 선형 회귀)

이번 포스팅에서는, Multivariable Linear Regression, 즉 다변수 선형 회귀에 대해서 알아보겠습니다.

일단 저번 시간까지 했던 내용들을 복습해 보겠습니다.
일반적인 Linear Regression의 Hypothesis는 H(x) = Wx + b였죠?
Cost function은 H(x) - y를 제곱해서 모두 더한 뒤 평균값을 내주는 것이었고...
Gradient Descent는 가장 적절한 (cost(W) 값이 가장 작은) W값을 찾아내는 알고리즘이었습니다.
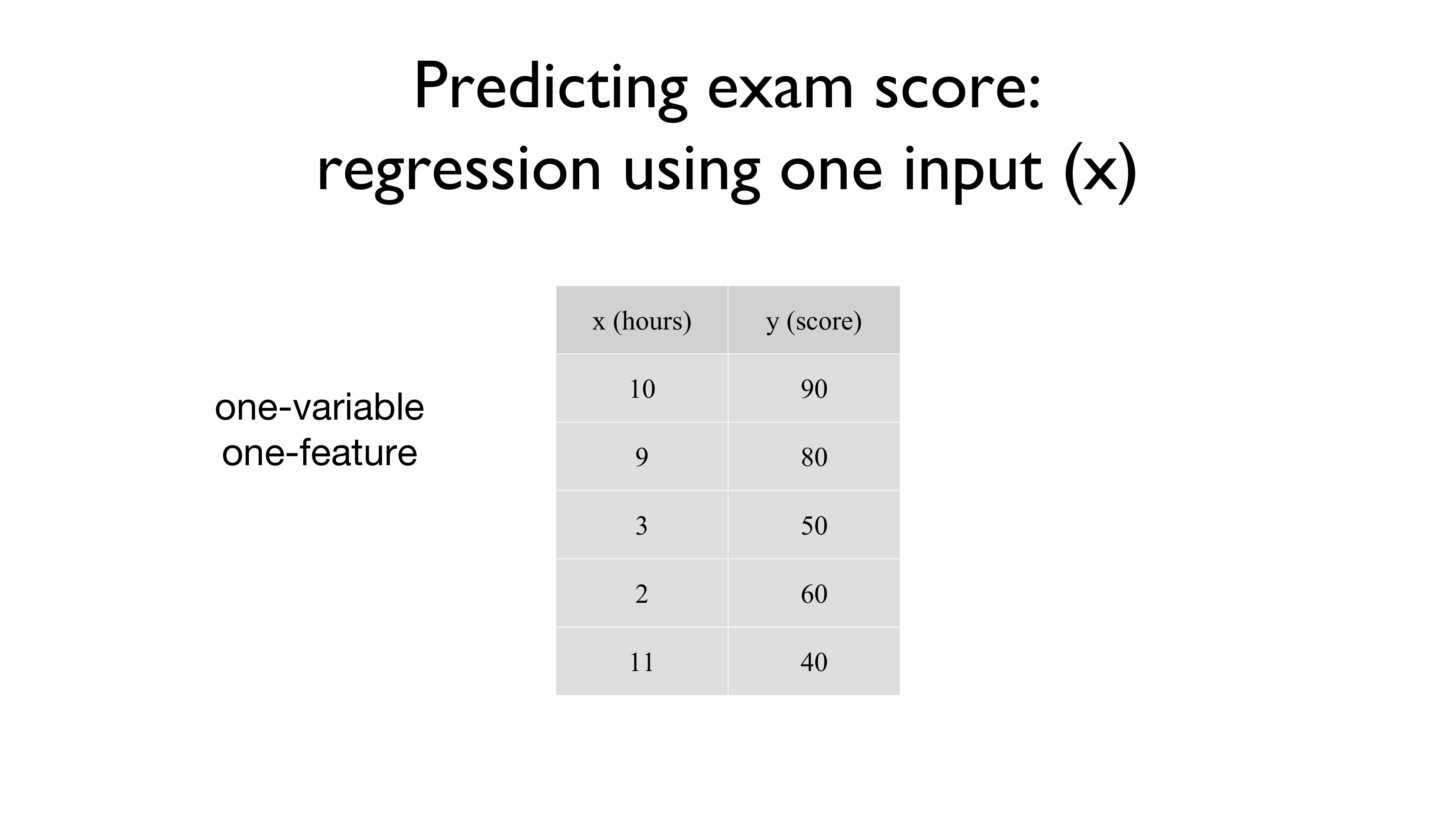
그리고 우리가 마주했던 데이터들은 다들 이런 형식으로 생겼습니다.
x값 하나당 y값 하나가 주어지는 형식이었죠.
이때, x는 하나의 feature을 의미합니다.
가령, 위의 경우엔 특정 점수 y를 그 점수를 갖게 되었던 특징인 feature x를 통해 알아봤던 것이죠.
그래서 위의 사진에서 one-variable one-feature라고 적혀있는 것입니다.
변수 하나에 특징도 하나밖에 (공부한 시간) 없으니까요.

그런데, 오늘 배울 Multi-variable Linear Regression은 데이터가 조금 다르게 들어옵니다.
x값이 하나가 아니라, 두 개, 세 개, 혹은 10000개도 들어오는데요,
각각의 x값 (x1, x2, x3)들은 각자의 특성을 띄고 있습니다.
위의 예시의 경우 x1 은 quiz1의 점수,
x2는 quiz2의 점수,
x3는 중간고사 1의 점수이고
이 점수들을 모두 어떠한 방식으로 계산했을 때 최종 점수인 Y가 나오게 되는 것입니다.

그런데, 그렇게까지 어려워지진 않았습니다!
Linear Regression의 기본형인 H(x) = Wx + b 를 그대로 따라서,
H(x1, x2, x3) = w1x1 + w2x2 + w3x3 + b
로 약간만 변형되었을 뿐입니다.
잠깐만 살펴보면, x의 종류 (feature의 개수)가 늘어나면, 그에 따라 w의 개수도 늘어나게 됩니다!
x1에는 w1, x2에는 w2, x3에는 w3를 곱해주는 식으로 말이죠.
그리고, b의 값은 여전히 그대로 남아있습니다.
feature가 많아졌다고 해서 b의 개수도 많아지진 않은 것이죠.
(그도 당연한 것이, 각자의 x값에 b를 더하더라도 어차피 상수 하나 더한 거랑 같으니까요.)

그럼, Cost function은 어떻게 바뀌었을까요?
H(x1, x2, x3) = w1x1 + w2x2 + w3x3 + b
를 그대로 우리가 사용하던 Cost function 안에 집어넣으면 됩니다.
즉, H(x1, x2, x3) - y 를 제곱한 것을 모두 더해서 평균을 내는 것이죠.
조금만 더 풀자면, H(x1, x2, x3) = w1x1 + w2x2 + w3x3 + b 이므로,
w1x1 + w2x2 + w3x3 + b - y 를 제곱해서 모두 더해주는 것이죠.

그리고 x1, x2, x3와 같이 feature의 개수가 세 개가 아니고 무수히 많더라도, 위의 식처럼
H(x1, x2, x3,... , xn) = w1x1 + w2x2 + w3x3 +... + wnxn + b
로 표현이 가능합니다.
즉, 우리가 원래 알고 있던 Linear Regression의 식을 아주 쬐끔만 변형시켜 주면,
Multi-variable Linear Regression도 뚝딱 해낼 수 있습니다.
그런데, 중요한 것은 그게 아니고,
"그래서 이거 계산 어떻게 할건데?"입니다.
그러니깐, 기본적인 Linear Regression에서는 x값이 10개 정도 주어지고, w값이 하나니깐
x1 * w + x2 * w + x3 * w +... + x10 * w + b
정도로 계산이 가능했고, 그냥 {x1, x2, x3,... , x10} * w + b만 해도 되었습니다.
하지만, feature이 많아져서, 상황이 조금 달라졌습니다.
x1의 첫 번째 데이터를 x11, x3의 네 번째 데이터를 x34... 이런 식으로 쓰고, feature가 n개이고 데이터의 개수가 m 개라면 우리가 계산해야 할 식은
x11 * w1 + x21 * w2 +... + xn1 * wn + b
+ x12 * w1 + x22 * w2 +... + xn2 * wn + b
...
+ x1m * w1 + x2m * w2 +... + xnm * wn + b
처럼... 딱 봐도 복잡한 이차원 배열 * 일차원 배열을 계산해야 합니다.
하지만, 이것을 반복문으로 그냥 쭉 돌려버릴 수도 없는 것이...
가령 n과 m이 각각 10 만씩이라고만 해도,
반복문으로 돌리면 100억 번의 연산을 해야 한다는 말도 안 되는 결과가 나오기 때문입니다.
그러면 이것을 어떻게 간단하게 연산할 수 있을까요?
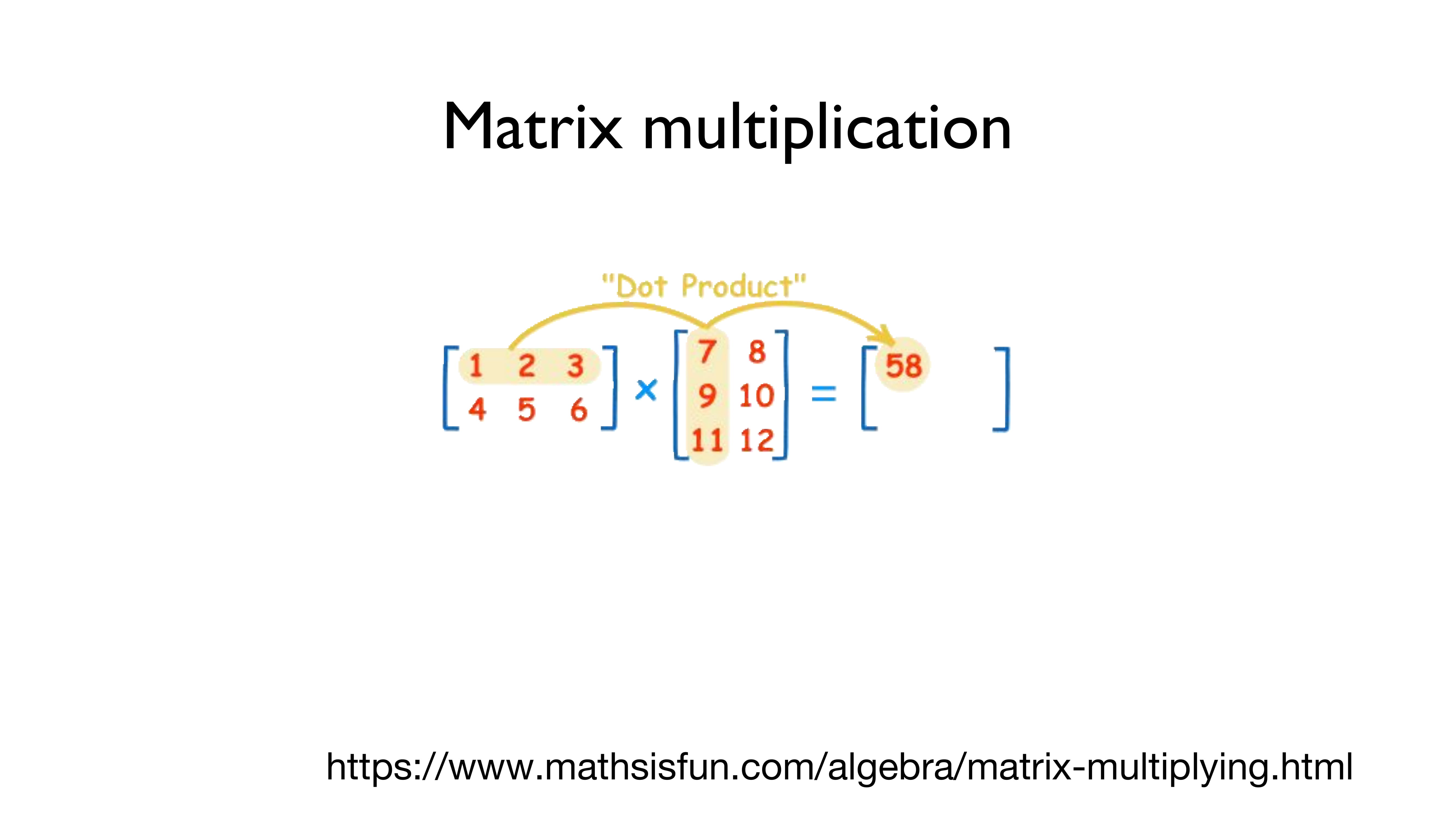
바로, "Matrix multiplication", 즉 "행렬곱"으로 이 문제를 해결합니다.
행렬곱은 어떤 식으로 진행되는지 위의 그림을 통해 알아봅시다.
(헷갈릴까 봐 써놓는데 - 가로가 행이고 세로가 열입니다!!!)
왼쪽의 [[1,2,3], [4,5,6]]의 (2,3)의 행렬과 [[7,8], [9,10], [11,12]]의 (3,2) 행렬을 곱하는 것은 간단합니다.
왼쪽의 행렬의 첫 번째 행인 [1,2,3]의 각각의 요소들을 오른쪽의 행렬의 첫 번째 열인 [7,9,11]로 곱해서 더해줍니다.
즉, 1*7 + 2*9 + 3*11 = 7 + 18 + 33 = 58
이 되는 겁니다.
그리고, 이 값을 결괏값의 행렬의 첫 번째 행, 첫 번째 열에 놓습니다.
두 번째도 동일하게 진행하면 됩니다.
왼쪽의 행렬의 첫 번째 행인 [1,2,3]의 각각의 요소들을 오른쪽의 행렬의 두 번째 열인 [8,10,12]로 곱해서 더해줍니다.
그러면, 1*8 + 2*10 + 3*12 = 8 + 20 + 36 = 64가 됩니다.
그리고, 이 값을 결괏값의 행렬의 첫 번째 행, 두 번째 열에 놓습니다.
두 번째 열은 직접 한번 해보시기 바랍니다.

자, 대충 배웠으니 한번 대충 적용해 봅시다.
w1x1 + w2x2 + w3x3을 행렬로 계산하려면 어떻게 해야 할까요?
x1, x2, x3를 (1,3)의 크기의 행렬로 놓고,
w1, w2, w3을 (3,1)의 크기의 행렬로 놓는다면,
행렬곱을 통해 x1 w1 + x2w2 + x3w3를 구할 수 있게 됩니다.

그런데, 우리가 가지고 있는 데이터는 x1, x2, x3값이 각각 하나만 들어있는 데이터가 아니죠?
x1 여러 개, x2 여러 개, x3 여러 개로 이루어진 데이터를 갖고 있는데, 이것을 어떻게 계산할까요?

아까 저 위에서 했던 짓을 똑같이 반복하면 됩니다.
우선, x값들의 행렬 중 첫 번째 행인 x11, x12, x13과 w1, w2, w3를 곱하여,
x11w1 + x12w2 + x13w3을 결괏값 행렬의 첫 번째 요소로 넣어줍니다.
그다음엔 x21w1 + w22w2 + w23w3 을 넣게 될 것이고,
그것을 마지막 데이터인 x51, x52, x53까지 반복하면 되는 것입니다.
그러면, 왼쪽의 x값의 데이터와 오른쪽의 w값의 데이터를 통해 결괏값을 행렬로 도출해 낼 수 있는 것이죠.

그런데 행렬곱에는 특징이 하나 있습니다.
입력되는 데이터의 형태에 따라 결괏값의 형태가 달라진다는 것이죠.
가령 바로 위의 예시를 보면, (5,3) 크기의 데이터와 (3,1) 크기의 데이터를 행렬곱하면, (5,1) 크기의 결괏값이 나오게 됩니다.
어떻게 보면 당연한 것이긴 합니다.
왼쪽의 (5,3) 행렬의 각각의 행을 오른쪽 (3,1)의 행렬에 곱해서 모두 더한 값은, 결괏값인 (5,1)의 행들에 집어넣고 있으니까요.
그런데, 여기서 중요한 점 하나가 더 있습니다!!
만약, (5,3) 크기의 행렬에 (2,1) 크기의 행렬을 행렬곱시키면 어떻게 될까요?
... 행렬곱 시킬 수 없습니다.. ㅎㅎ
이것도 어떻게 보면 당연한 것이겠지만,
x1, x2, x3를 w1, w2에만 곱할 수는 없는 노릇 아니겠습니까 ㅎㅎ
즉, 행렬곱을 계산해 줄 때에는 데이터의 크기를 잘 생각해야 합니다!
(n, m) 크기의 행렬을 x값으로 사용할 것이라면,
(m, 1) 크기의 행렬을 w값으로 사용해 주어야 한다는 것입니다.
그러면 결괏값은 (n, 1) 크기의 행렬로 나오게 되겠지요.

그런데, 중요한 게 또 또 있습니다!
행렬곱은 일반적인 곱셈과는 다르게 곱셈의 순서가 중요하다는 것입니다!
위의 식처럼, (5, 3) 크기의 행렬과 (3, 1)를 곱하면 (5, 1)이라는 행렬이 나오지만,
반대로 (3, 1) 크기의 행렬과 (5, 3) 크기의 행렬은 곱할 수 없다는 것입니다.
즉, 순서가 매우 매우 매우 중요합니다!!
앞 행렬의 행 크기와, 뒷 행렬의 열 크기가 동일해야 한다는 것입니다!
아까 전과 마찬가지로, (m, n)의 행렬에 곱할 수 있는 행렬은 (n , k) 꼴의 행렬뿐입니다.
(결괏값은 (m, k) 크기의 행렬로 나오겠죠.)



즉, 지금까지 하고 싶은 말이 무엇인고 하니...
우리가 Python이나 Tensorflow로 위의 Linear Regression을 구현하려면
지금까지 배웠던 H(x) = Wx + b 로 계산하는 것이 아니고,
H(X) = XW로 구현해야 한다는 것입니다!
이것을 특별히 더 강조한 이유는 간단합니다.
이거 처음 배울 때 저는 이 행렬 순서를 맞춰야 된다는 사실을 모른 채라 삽질을 오지게 했기 때문이죠 ㅎ
여러분들은 행렬의 크기를 맞추지 않아서 삽질하는 일은 없도록 합시다!

다음 포스팅에서는 Logistic Regression에 대해서 알아보겠습니다.
그럼 안녕!!
'인공지능 > 모두를 위한 딥러닝 (sung kim) lec' 카테고리의 다른 글
| 모두를 위한 딥러닝 부록편 - 미분의 개념과 Gradient Descent (1) | 2019.05.10 |
|---|---|
| 모두를 위한 딥러닝 (sung kim) lec5 - Logistic Classification (로지스틱 회귀분석) (0) | 2019.05.09 |
| 모두를 위한 딥러닝 (sung kim) lec3 - Gradient Descent (경사하강법) (0) | 2019.04.08 |
| 모두를 위한 딥러닝 (sung kim) lec2 - Linear regression & cost function (0) | 2019.03.30 |
| 모두를 위한 딥러닝 (sung kim) lec1 - 머신 러닝 기초 (0) | 2019.03.28 |
모두를 위한 딥러닝 (sung kim) lec3 - Gradient Descent (경사하강법)

안녕하세요.
이번 시간엔 머신 러닝의 꽃이라고 할 수 있는 Gradient Descent에 대해 알아봅시다.

저번 시간에 배웠던 내용을 잠시만 복습하고 들어가 봅시다.
우선, Linear Regression의 가설 함수는 H(x) = Wx + b 였고,
Cost function은 각각의 H(x) 값에서 y값(정답)을 빼준 후,
그 값들을 죄다 제곱해서 평균을 내주는 것이었습니다.
기억이 나지 않는다면, 이전 포스팅 (https://cding.tistory.com/12)에서 다시 한번 복습하고 와주세요!

그런데, 일단은 이해를 쉽게 하도록 하기 위해서 H(x)를 그냥 Wx라고 해봅시다.
(b를 빼준 것뿐, 일차함수라는 큰 틀은 변화하지 않았습니다.)
그러면, Cost function도 조금은 바뀌어서...
H(x)에서 y값을 빼주던 것을, Wx에서 y값을 빼주는 것으로 바꾸어도 상관없겠죠?
(H(x) = Wx 이므로)

그럼 이 상태에서 cost(W)의 값을 구해보도록 합시다.
X, Y가 왼쪽 표와 같이 주어진다면, 각각 W=1, W=0, W=2 일 때의 Cost값은 무엇일까요?
W=1일 경우,
X=1, Y=1에서 (W*x - y)^2 = (1 * 1 - 1)^2 = 0
X=2, Y=2에서 (W*x - y)^2 = (1 * 2 - 2)^2 = 0
X=3, Y=3에서 (W*x - y)^2 = (1 * 3 - 3)^2 = 0
이 세 가지 경우의 수를 모두 더하면 0+0+0 = 0, 평균으로 나눠도 0
즉, Cost(1) = 0입니다.
cost가 0이므로, W=1일 때 완벽하게 데이터에 들어맞는다는 뜻이죠.
W=0일 경우에는?
X=1, Y=1에서 (W*x - y)^2 = (2 * 1 - 1)^2 = 1
X=2, Y=2에서 (W*x - y)^2 = (2 * 2 - 2)^2 = 4
X=3, Y=3에서 (W*x - y)^2 = (2 * 3 - 3)^2 = 9
이 세 가지 경우의 수를 모두 더하면 1 + 4 + 9 = 14, 평균으로 나누면 14/3 = 4.66666...
즉, Cost(0) = 4.67입니다.
W=2 일 경우에는 어떨지, 직접 한번 해 보시길 바랍니다.
참고로, 답은 W=0일 때와 동일하게 4.67이 됩니다.

이렇듯, W값에 따라 cost(W)의 값은 변하게 됩니다.
W=1일 때 cost의 값은 0으로 최소가 되고,
W=2, W=0일 때 cost의 값은 약 4.67이 되는 식이죠.
이때, 이런 식으로 cost(W)에서 W의 값에 값들을 많이 집어넣게 되면 위의 그래프처럼 함수가 그려집니다.
(x축을 W로, y축을 Cost(W) 값으로 집어넣은 그래프입니다.)
위에서는 W=-3부터 W=5까지만 집어넣었지만, 다른 값들을 넣어도 여전히 이차함수의 그래프가 그려지게 되겠죠.
그런데, 어떻게 cost(W)의 값이 최소가 되는 W의 값을 구할 수 있을까요?

그래서 등장한 방법이 바로 Gradient Descent 알고리즘입니다.
(Gradient는 경사, Descent는 하강이므로 한국어로는 경사 하강법이라고 불립니다.)
위와 같은 상황에서 최소의 W값을 찾아주기 위한 알고리즘인데요,
굉장히 다양한 최소화 문제(특정 값을 최소화해주어야 할 때) 자주 사용되는 기법입니다.

일단은, Gradient Descent의 작동 방식에 대해 간단하게 먼저 알아봅시다.
우선, W를 랜덤 한 값으로 정해줍니다. (무엇으로 정해도 큰 상관은 없습니다.)
그런 후, 그 W의 값을 cost(W)의 값을 최소화시킬 수 있는 방향으로 바꿔줍니다. (보통 W값을 업데이트해준다고 표현합니다.)
그리고, 이 짓거리를 cost(W)가 최소가 될 때까지 반복합니다.
(저 위의 예시의 경우, W=1이 될 때까지 반복될 것입니다.)
그럼 여기서 당연히 의문이 하나 드실 것입니다.
"그래서 cost(W)의 값을 최소화시킬 수 있는 방향을 어떻게 아는데??"

자, 위의 사진에서 W의 값을 작은 공이라고 생각해 봅시다.
그러면, 공은 어느 방향으로 굴러가나요?
위의 경우, 경사가 왼쪽 아래로 져 있으므로 공은 왼쪽으로 굴러가게 될 것입니다.
그러면, 이 공은 어디까지 굴러갈까요?
cost(W) (위 이미지에선 J(w)라고 적혀있음)의 값이 가장 작아지는,
다시 말해서 가장 높이가 아래에 있는 곳까지 굴러갈 것입니다.
Gradient Descent는 이러한 원리와 동일하다고 봐도 됩니다.
W값이 처음 주어졌을 때, 우선 그 W값에 대한 경사를 먼저 구합니다.
그 후, 그 경사가 진 방향으로 W값을 바꿔줍니다.
경사가 왼쪽 방향으로 져 있다면, W값을 빼주고...
경사가 오른쪽 방향으로 져 있다면, W값을 더해주는 식으로 말이죠.
그렇게 한다면, 저 함수에서 가장 작은 cost(W)의 값을 가지는 W의 값을 구할 수 있게 됩니다.
Gradient Descent는 이렇게 단순한 생각을 갖고 만들어진 알고리즘입니다.
그런데, 그 각각의 W값에 대한 경사는 어떻게 구하냐고요?
그 경사를 구하기 위해서, 우리는 저 함수를 W값에 대하여 미분해 줄 것입니다.
(미분이 뭔지 잘 모르신다면, 간단하게 그냥 함수의 기울기를 구하는 방법 정도로 이해하시면 됩니다.)

지금부터의 내용은, 기본적으로 미분을 알고 있어야 이해가 가능합니다!
미분을 모르신다면, 그냥 저 아래로 쭉 내리시면 되겠습니다.
우선, f(x)^2를 미분하면 2 * f(x) * f'(x)가 됩니다.
그런데, 그 값에 그냥 m분의 1만 곱해버리면 상수 2가 남아버리니 계산하기 귀찮아지므로...
m분의 1 대신 2m분의 1을 곱하는 것으로 식을 바꾸겠습니다.

f(x)^2를 미분하면, 2 * f(x) * f'(x)가 된다는 사실을 이용하면,
(Wx - y)^2를 미분하면
2 * (Wx - y) * x 가 됩니다.
그리고 시그마 앞에선 2가 앞으로 넘어갈 수 있으므로,
2를 앞으로 넘기면 시그마 앞의 값은 1/2m * 2 = 1/m이 됩니다.
결국, W값은 W값에서 (Wx - y) * x의 평균을 낸 값을 뺀 값으로 업데이트해 줍니다. (위의 식 참고)
참고로, 위의 알파 값은 Learning Rate라는 것으로, 이에 대한 자세한 내용은 다른 시간에 알아봅시다.
Q. 왜 W값에서 "(Wx - y) * x의 평균을 낸 값"을 더하지 않고 빼는 것인가요?
A. 경사가 왼쪽을 향하고 있을 때, 그때의 미분 값은 양수인 가요, 음수인가요?
예, 경사가 왼쪽으로 져 있다면, 그 미분 값 (경사의 기울기 값)은 양수가 됩니다.
그런데 경사가 왼쪽으로 져 있으면, W값을 왼쪽으로 옮겨야겠죠? (즉, W값을 감소시켜야겠죠?)
그러므로, W값에서 양수를 빼주어야 W값이 감소하기 때문에, 저 값을 더하지 않고 빼는 것입니다.
반대로 경사가 오른쪽으로 져 있을 때에는 미분 값(기울기 값)이 음수가 되는데,
W값을 증가시켜 주어야 하므로,
음수를 빼주어서 W값을 증가시키는 것입니다.

그런데, 저 미분을 죄다 하고 있을 시간은 사람에게 없습니다.
그런 일 따위는 컴퓨터에게 시킬 수 있습니다.
즉, 미분 사실 몰라도 공식만 대충 집어넣으면 된다는 거죠,
(게다가 텐서 플로우를 비롯한 대부분의 머신러닝 툴에서는 Gradient Descent는 모두 지원합니다.)

그런데 만약 함수가 이따구로 생겼다면 어떻게 될까요?
어느 점에서 시작하느냐에 따라 경사가 진 곳이 죄다 다르므로, 향하는 방향이 죄다 다르게 됩니다.
결국, W값이 우리가 원하는 "함수 전체에서의 최솟값"으로 가는 것이 아니라,
"일정 구간만에서의 최솟값"으로 가게 됩니다.
이를 각각, "Global Minima"와 "Local Minima"라고 부릅니다.
아무튼, 저렇게 생긴 함수에선 그냥 W값이 Local Minima에 처박힐 가능성이 매우 높기에, Gradient Descent의 성능이 매우 떨어집니다.
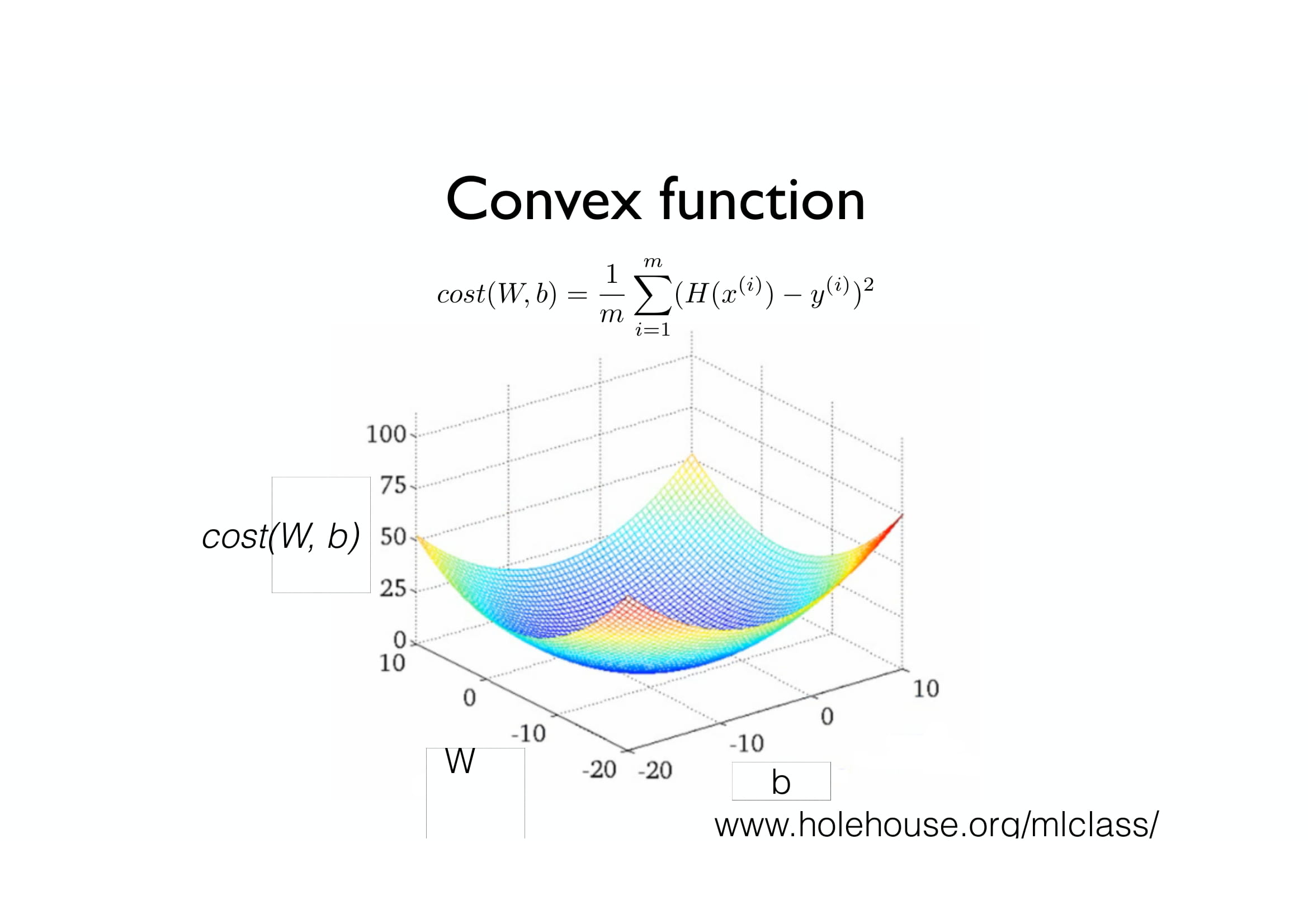
그러므로, 우리는 Cost function을 저렇게 이상하게 생긴 함수로 두면 안되고,
아름다운 밥그릇 모양 (중간이 패인 트램펄린 모양?)으로 생긴 함수를 사용하여야 합니다.
그러면, 결국 Local minima가 한 개뿐이므로 Local Minima가 Global Minima와 같은 것이 됩니다.
이런 식으로, Local minima와 Global minima가 동일한 아름다운 함수를 우리는 Convex function이라고 부릅니다.
그러므로, 우리는 Convex function을 Cost function으로 사용하여야 합니다.

다음 시간에는, Multi-variable Linear Regression(다변수 선형 회귀)에 대해 배워보겠습니다.
(왜 로지스틱이라고 적혀있는지는 잘 모르겠습니다;; 분명 다음엔 Linear regression인데;)
그럼 안녕!
'인공지능 > 모두를 위한 딥러닝 (sung kim) lec' 카테고리의 다른 글
| 모두를 위한 딥러닝 부록편 - 미분의 개념과 Gradient Descent (1) | 2019.05.10 |
|---|---|
| 모두를 위한 딥러닝 (sung kim) lec5 - Logistic Classification (로지스틱 회귀분석) (0) | 2019.05.09 |
| 모두를 위한 딥러닝 (sung kim) lec4 - Multivariable Linear Regression (다변수 선형 회귀) (1) | 2019.04.09 |
| 모두를 위한 딥러닝 (sung kim) lec2 - Linear regression & cost function (0) | 2019.03.30 |
| 모두를 위한 딥러닝 (sung kim) lec1 - 머신 러닝 기초 (0) | 2019.03.28 |
텐서플로우 - Linear regression 코드 정리
- 파이썬을 거의 모르는 사람도, 코드를 이해 가능할만큼, 함수와 기타 등등이 뭔지 정리함.
- 내가 강의할때 보거나 할것.
* 텐서플로우가 어떻게 돌아가는지에 대한 이해는 있어야함!
모르면 머신러닝 포스팅 lab 1&2 보기
import tensorflow as tf'텐서플로우' 라는 패키지를 불러와서, 그 이름을 "tf" 라고 하자.
* as tf 안하면 tensorflow 관련 함수 호출할때 tensorflow.~~~ 해야되는데,
as tf 하면 tf.~~~하면 됨, 아주 간편함!
x_train = [1, 2, 3, 4]
y_train = [0,-1,-2,-3]x,y값을 일단 선언해둠. (데이터를 이걸로 할거라 미리 저장해 놓는 것)
# Placeholder 설정
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# 변수 설정
W = tf.Variable(tf.random_normal([1]))
b = tf.Variable(tf.random_normal([1]))tf.Placeholder 뜻 : 지금 미리 값을 넣어두는 것이 아니고, 나중에 sess.run 할때 데이터를 집어넣을 것임.
뭔소린지 모르겠다면 머신러닝 포스팅 lab 1&2로 가서 확인할 것.
tf.Variable 뜻 : 텐서플로우의 변수선언.
tf.random_normal([1])) 뜻 : [1] 크기의 랜덤한 (정규분포를 따르는) 수를 생성함.
Linear regression 코드이므로, W,b값이 각각 하나이기 때문에 [1] 씩만 생성함.
hypothesis = X * W + bLinear regression 의 Hypothesis function H(x) = W*x + b 를 hypothesis로 선언함.
cost = tf.reduce_mean(tf.square(hypothesis - Y))Cost function이었던
$$(H(x) - y)^2 을 각각의 데이터 m개에 대하여 모두 더하고, m으로 나누어 평균을 구함.$$
을 구현한 것.
tf.square 뜻 : 제곱.
tf.reduce_mean 뜻 : 평균.
* hypothesis 는 x*W + b이고, x 는 크기 4의 배열이라 계산된 총 크기는 [4],
y도 [4] 이므로 둘이 빼면 그냥 다 더한거랑 똑같은 게 됨.
train = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)Gradient Descent 방법을 이용하여 train함.
minimize(cost) : cost를 최소화 시킬것임.
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(1001):
sess.run(train, feed_dict={X: x_train, Y: y_train})
if step%50 == 0:
W_val, b_val, cost_val = sess.run([W, b, cost], feed_dict={X: x_train, Y: y_train})
print(" < Step : %d>" %step)
print("Cost : ",cost_val,"\nW :",W_val,"\nb : ",b_val,"\n\n")
# evaluate training accuracy
print(f"W: {W_val} b: {b_val} cost: {cost_val}")session을 열음.
sess.run(tf.global_variables_initializer()) 뜻 : 아직 초기화되지 않은 (값이 박히지도 않은) 변수들을 죄다 초기화해줌.
이거 안하면 변수 터짐.
for step in range(1001) : 뜻 - 0부터 1000까지 돌릴것 ㅎ
sess.run(train, feed_dict = {X: x_train, Y: y_train}) 뜻 : train 함수를 실행시킴 (minimize(cost) 한것)
cost에는 tf.square(Hypothesis - Y) 가 있으니 Y값이 필요할 것이고,
Hypothesis 에는 X*W + b가 있으므로 X값이 필요함.
그 두개의 X,Y를 아까 선언해뒀던 x_train, y_train값으로 집어넣음.
if step%50 == 0: - step이 50의 배수일때 (50,100,150,200 ... , 1000번째 step에서 : )
W_val, b_val, cost_val = sess.run([W, b, cost], feed_dict={X: x_train, Y: y_train}) 뜻 :
W_val, b_val, cost_val 에 각각 W,b,cost의 값을 집어넣음.
cost의 값에는 위에서 언급했듯이 X,Y 둘다 있으므로, feed_dict 로 X,Y값으로 넣어줌.
아래는 간단한 print이므로 설명 생략.
끝~
'인공지능 > 딥러닝 개념 정리노트' 카테고리의 다른 글
| 딥러닝 개념정리 노트 - 머신 러닝 / Supervised learning / Unsupervised learning (0) | 2019.04.02 |
|---|