분류 전체보기
-
텐서플로우 - Linear regression 코드 정리2019.04.03
-
모두를 위한 딥러닝 (sung kim) lec1 - 머신 러닝 기초2019.03.28
-
태풍이 부네요2018.08.23
디미고에서의 일상 관련 글을 작성해볼까 합니다.
디미고에 입학한 지 이제 2년 차 접어들고 있는데, 어째 뭔가 학교에 대한 생각이 없어지는 기분입니다.
처음 입학하고 싶었던 때, 처음 입학했을 때의 기억은 다 어디로 가고
이제는 학교에서 뭘 하고 있는지도, 뭘 했었는지도 잘 모르는 채로 살아가는 것 같습니다.
하루하루가 너무 빨랐던 것 같습니다.
입학하기 전보다 깨어있는 시간은 더 길었지만, 정신을 차리고 있던 시간은 더 짧았던 것 같습니다.
제가 디미고에서 뭘 하고 살았는지도 사실 잘 모르겠습니다.
정보올림피아드 공모전 나가서 상도 타보고, 친구와 열심히 C언어 콘솔로 게임도 만들어 상도 타보고...
이것저것 분명히 한 것은 많았던 것 같지만 그마저도 기억에 잘 나지 않습니다.
이제부터라도 제 디미고의 일상들을 기록해야 할 것 같습니다.
그래야 나중에라도 제가 무슨 경험들을 했는지 기억이라도 하고,
제가 시도했던 많은 것들을 깨달을 수 있을 것 같습니다.
디미고 글을 쓰려는 다른 이유도 있습니다.
디미고에 입학하기 전에, 네이버에도 구글에도 여기저기 검색하며 디미고에 대해 알아본 적이 있었습니다.
하지만, 디미고 생활이 워낙에 바빠서인지... 글을 찾아보려 해도 현실적으로 쓴 글들은 찾아보기 힘들었습니다.
실제 디미고 생활은 어떠한지, 디미고에 들어오면 무엇을 할 수 있는지 등등
여러가지 정보들을 얻기는 쉽지 않았습니다.
컴퓨터에 관심이 많던 중학생들은 예전의 저처럼 인터넷에 디미고가 어떤지 검색하고 있었을 것입니다.
그리고 디미고의 경쟁률이 더 치열해진 지금은, 더욱 많은 학생들이 디미고에 대해 알고 싶어 할 것 같습니다.
디미고 기숙사 생활은 할 만 한지, 공부는 얼마나 빡세게 하는지...
이런 점에 대해, 허심탄회하고 솔직하게 좀 써보려고 합니다.
솔직히 조금 부끄러울 것 같기도 합니다.
제가 살아가는 이야기를 일기처럼 써내려 가는것 또한 조금은 낯부끄럽고,
누군가가 그걸 또 보는 것도 조금은 부담스럽긴 합니다.
물론 별로 볼것 같진 않지만요.
그래도 제 미래를 위해, 그리고 디미고를 바라보고 있는 학생들을 조금이나마 도울 수 있게
디미고에서 어떤 일들을 경험하는지, 어떤 것들을 하고 사는지
조금씩이라도, 그리고 조금 장황하게라도 적어가면서
제가 살아가는 이야기를 적어 나가야겠습니다.
혹시라도 디미고에 대해 알고 싶은 점들이 있는 중학생들이 있다면,
부담없이 댓글로 알고싶은 점에 대해 물어보세요.
댓글로 답해드리거나, 따로 글을 써서 알려드리겠습니다.
그리고, 디미고 다니는 놈들이나
제가 아는 사람들이 이상한 댓글 쓰거나
디미고 지망 중학생인척 하면서 별 요상한거 물어보는거 걸리면
그대로 그놈한테 달려가서
정의의 뿅망치로 명치랑 뚝배기를 깨버릴테니
조심하시길 바랍니다 ^^
'일상 > 디미고' 카테고리의 다른 글
| 디미고 일상 - 기숙사 밤 편 (3) | 2019.04.23 |
|---|---|
| 디미고 일상 - 시험 & 시험기간 편 (7) | 2019.04.22 |
| 디미고 일상 - 점호 (3) | 2019.04.18 |
| 디미고 진학 관련 글들, 제발 믿지 마라 (52) | 2019.04.11 |
| 디미고의 일상 (4) | 2019.04.10 |
강화 학습 강의 (CS234) 1강 (1) - 강화 학습이 뭘까? / Markov란?
원래는 Deepmind의 강의 영상을 바탕으로 강화 학습 관련 글을 작성하려 했으나, 얼마 전에 스탠포드 대학교의 강의인 CS234의 영상이 유튜브에 올라온 것을 보고 그를 바탕으로 글을 작성합니다.
슬라이드 / 렉쳐노트 : http://web.stanford.edu/class/cs234/schedule.html
영상 : https://www.youtube.com/playlist?list=PLoROMvodv4rOSOPzutgyCTapiGlY2Nd8u
강의 내용을 정리하고, 영어로 된 영상을 보지 않고도 강화 학습을 배울 수 있도록 글을 작성합니다.
* 주의 - 기본적인 머신 러닝에 대한 이해도가 있어야 합니다! 제 티스토리의 "머신 러닝 기초" 를 먼저 보시거나, 다른 머신러닝 강의를 보며 머신 러닝을 학습하는 것을 추천드립니다.

오늘부터 시작할 강화 학습 강의입니다.
언제나 그렇듯, 강화 학습이 무엇인지 먼저, 간단하게 강화 학습이 무엇인지 먼저 알아가 보도록 합시다.

강화 학습을 한 줄로 요약하자면,
"순차적 선택을 잘 하도록 학습하는 것" 이라고 합니다.
이 한 문장 속에 앞으로 해나가야 할 굉장히 많은 내용들을 함축하고 있는데, 한번 쪼개 보도록 하겠습니다.
우선, 인공지능에게 "순차적 선택"을 할 수 있도록 해야 합니다.
즉, Yes or No 로 이루어진 단순한 선택이 아닌, 게임을 플레이하듯, 운전을 하듯 순차적인 일련의 선택들을 잘해나가도록 해야 한다는 것이죠.
그리고, 그러한 선택을 "잘" 하도록 해야 합니다. 그러기 위해서는 무엇이 "좋은" 선택인지 알아야 하고, 상황에 따른 최적의 선택을 찾아내야 하죠.
마지막으로, "학습"을 해야 합니다. 그리고 이것이 바로 강화 학습 (사실 머신러닝 대부분)의 가장 중요한 부분이죠.
사실 AI의 가장 중요한 점은 이미 경험하지 않은, 즉 "확실하지 않은" 상황 속에서도 좋은 선택을 하게 만드는 것이죠.
특히 강화 학습에서는, 이전 경험에 빗대어 그 상황을 직접 경험하지 않고도 최적의 결과를 내는 방식으로 학습합니다.
(더 자세히는 나중에 설명합니다!)

일단 강화 학습의 예시를 보도록 합시다.
사실 CS234 강의에는 좀 다양한 예시가 나오긴 하는데, 그거 다 설명하기는 좀 그렇고 가장 대표적으로, 그리고 보통 가장 처음 해보게 되는 게임 강화 학습에 대한 예시를 보도록 하겠습니다.
https://www.youtube.com/watch?v=V1eYniJ0Rnk
위의 퐁같은 경우가 바로 강화 학습이 적용된 예시입니다.
순차적 선택 (밑의 바를 움직이는 것) 을,
잘 (최대한 점수가 높게),
학습 (컴퓨터가 플레이함)
시키는 것이죠.

강화 학습에서 중요하게 다루는 측면은 크게 네 가지로 분류할 수 있습니다.
바로, Optimization, Delayed consequences, Exploration, Generalization 입니다.
Optimization이란, 다양한 상황 속에서 할 수 있는 다양한 결정 중에서 가장 최적의 (또는 그냥 좋은) 결정을 하도록 만드는 것입니다. Optimization은 강화 학습 뿐만 아니라, 다른 머신러닝 기술에서도 다루는 내용입니다.
Delayed consequences는 지금 한 선택이 한참 나중에도 좋은 선택인지 아닌지 잘 모른다는 것입니다.
가령, 지금 당장 아이스크림을 5개를 동시에 먹어도 한 시간 정도는 배가 아프지 않지만, 한 시간 후에 갑자기 배가 아파올 수도 있겠죠? 이렇듯, 지금 한 일이 나중에도 영향을 미치는 것을 말합니다. 일반적인 머신 러닝에서는 볼 수 없는, 강화 학습만의 주요한 특징 중 하나입니다.
Exploration은 말 그대로, 탐험하는 것입니다. 많은 결정들을 하면서 세상에 대해 배우는 것이죠.
여기서 가장 큰 문제점은, 바로 우리는 우리가 이미 한번 해봤던 것에 대해서만 안다는 것이죠.
공부도 조금 해 봐야지 내가 얼마나 공부에 적성이 있는지 알게 되고, 게임도 조금 해 봐야지 재미있다는 것을 알게 되는 것과 마찬가지입니다.

마지막으로, Generalization입니다. 직역하자면, 일반화죠.
아까 전에 했던 퐁의 예시로 돌아가 봅시다. 사실 이 AI는 따로 게임의 룰을 알려주어 학습시킨 것이 아니라 단순한 픽셀 값들만으로 게임을 플레이하도록 학습시킵니다.
그런데, 만약 이런 AI를 수작업으로 만든다면 어떻게 될까요? 각 픽셀을 하나의 경우의 수로 놓는다면, 수없이 많은 경우의 수에 대한 선택들을 제시해야만 합니다. 사실상 말이 안 되는, 어마 무시한 값이죠.
그렇기 때문에, 이러한 것들을 단순한 픽셀로 볼 것이 아니라, 다른 방식으로 일반화시켜야 합니다. 데이터(픽셀 값)들로만 학습하는 것보다 훨씬 더 나은 성능을 제공할 뿐만 아니라, 더욱 고수준으로 해야 할 작업을 나타낼 수 있기 때문이죠.
이 네 가지 중에서, 가장 "강화 학습만의 특징"이라고 할 수 있는 것은 바로 "Exploration"입니다. AI Planning, Supervised Learning, Unsupervised Learning, Imitation learning 등 다양한 기술들은 모두 Optimization과 Generalization이 중요하고, 그중 AI Planning과 Imitation Learning에서는 Delayed Consequences 를 고려하기도 하지만, Exploration은 하지 않습니다. Exploration이 그만큼이나 독특한 특징이라는 것이죠.
... 여기까지가 15분짜리 내용입니다.. 줄일 거 줄인다고 썼는데도 기네요;;
계속한번 가봅시다!!

이제 한번 조금 더 자세히 들어가 봅시다.
들어가기에 앞서, 기본 용어들을 대충 정리하자면...
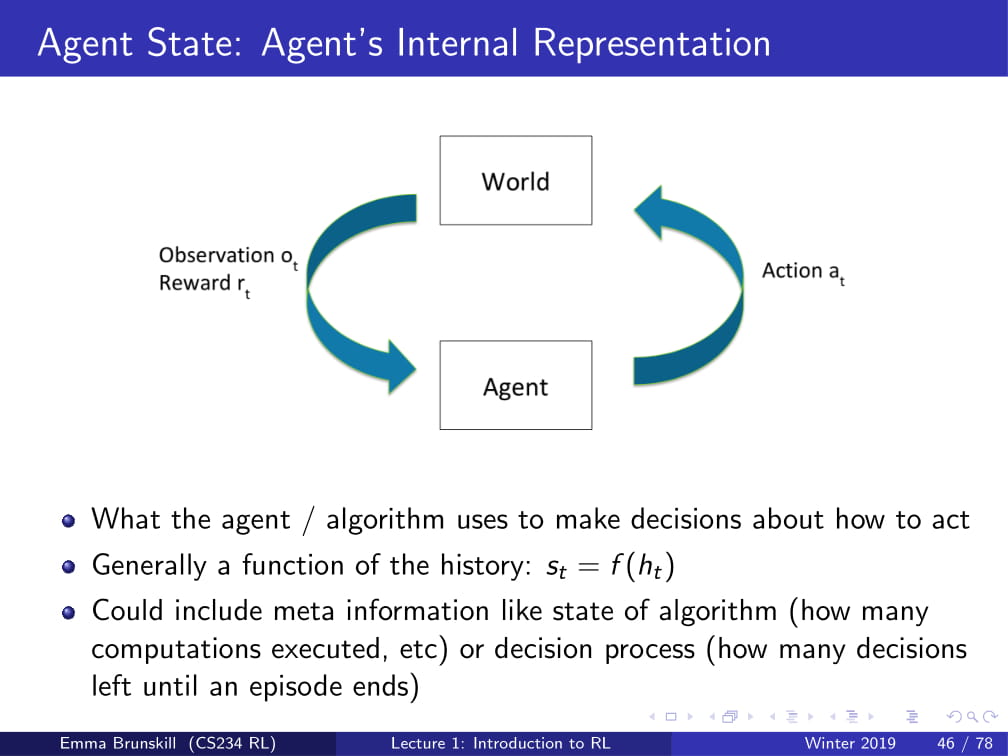
Agent : 우리가 학습시키고자 하는 AI.
Action : 행동.
Observation : 관찰. Agent가 보고 듣는 것.
Reward : 보상. 어떤 Action을 취했을 때 얻는 점수의 개념임.
World : 세상. 일반적으로 학습시키고자 하는 환경을 의미함. (게임의 경우 게임 세상)
(단어장 아님 주의)
그래서 강화 학습의 궁극적 목표는,
"Agent가 World에 대한 Observation을 통해, 최적의 Reward를 얻는 Action을 찾는 것" 입니다.
이를 위해선 즉각적인 보상과 먼 나중에 있을 잠재적인 보상의 균형을 맞춰줘야 할 수도 있고, (Delayed Consequence)
높은 reward를 얻기 위한 행동 전략을 필요로 할 수도 있습니다.
물론, 이것들이 필수인 것은 아닙니다. 문제 상황의 경우에 따라 필요할 수도, 필요하지 않을 수도 있습니다.

웹 광고의 경우, Agent는 웹에 띄울 광고를 띄워주고, 그때 시청 시간과 광고 클릭률 등을 보고(Observation) 학습합니다.
이 경우엔 즉각적 보상과 잠재적 보상의 균형을 맞출 필요도 없고,
특정한 전략을 요구하지도 않습니다.

혈압 조절 같은 경우, Agent가 환자에게 운동을 시키거나 약을 투여하는 행동 중 하나를 권유할 수 있습니다.
그리고, 만약 그 권유를 들은 환자가 건강해지면 +1의 보상을 얻고, 약 투여의 부작 용당 -0.05의 보상을 얻습니다. (잃는 거죠 ㅎㅎ)
운동을 바로 시작한다면 바로 건강해지진 못하겠지만, 추후에 건강한 범위 안에 들어올 수는 있겠죠.
이를 통해, 즉각적 보상과 잠재적 보상 사이의 균형을 맞춰야 할 필요가 있을 것입니다.
약을 투여한다면 즉각적으로 환자가 건강해질 수는 있겠지만, 추후 부작용이 있을 수도 있겠죠.
즉, 약을 투여하는 것에는 특정한 행동 전략이 필요하다는 것이죠.

이제 이것들을 조금 수식화(?) 시켜봅시다.
시간은 원래는 연속적이지만, 그 연속적인 시간 하나하나를 쪼갤 수는 없으니 시간을 불연속적으로 설정하고... (가령, 게임의 경우 프레임 단위)
지금까지의 내용을 대충 정리해 본다면,
각각의 time step t 에 대하여,
Agent 는 Action at 를 취하고,
World 는 at 에 대한 Observation인 ot 와 Reward인 rt 를 내며,
다시 Agent는 그 ot 와 rt 를 갖고 학습합니다.
(작은 영어 어떻게 치나요 ㅠㅠㅠ)
..라고 할 수 있겠죠?

그런데, 이런 a, o, r들을 어디다 써먹을까요?
우리가 Agent를 학습시킬 때, 어떤 방식으로 Agent를 학습시킨다고 했었죠?
과거의 경험을 바탕으로, 추후에 어떤 행동을 취할지 결정한다고 했었습니다.
그렇다면, a1, o1, r1,... at, ot, rt 들을 모아서 이것들을 바탕으로 다음 결정을 취한다고 할 수 있겠지요?
(t는 현재 time step을 의미합니다.)
이렇게 결정을 내릴 때 사용하는 정보를, State라고 합니다.
그리고, 이런 State는 결국 History를 바탕으로 나오는 것이므로,
각각의 State는 일종의 History의 함수이다. ( St = f(Ht) )
라고 할 수 있습니다.
여기서 함수라고 하면, 일차함수, 이차함수와 같은 개념보다도 일종의 프로그래밍에서의 함수로 보는 것이 더 적절해 보입니다. 즉, 일정 데이터 값들에 대해 특정 행동을 취하게 만드는 것입니다.

World State란, 실제로 세상이 어떻게 돌아가는지를 알려주는 정보를 의미합니다. 어떤 행동을 했을 때 어떻게 관측되고, 어떤 보상이 주어지는지를 의미하는 것이죠.
가령, 위의 게임인 퐁의 경우, 공이 블럭에 맞으면 블럭이 부서진다거나 블럭을 부수면 보상이 들어온다거나 하는 등의Observation과 Reward가 주어집니다.
하지만, 대부분 Agent에게는 이러한 정보가 주어지지 않습니다. 아까 Pong의 예시를 들 때, Pong의 Agent는 픽셀 값으로만 학습한다고 했었죠? 즉, 이 Agent는 "블럭을 부수면 점수가 들어온다" 라는 정보는 주어지지 않았었다는 것이죠.
그리고 어떠한 사실을 안다고 하더라도, Agent에게 별 쓸데없는 내용일 수도 있습니다. 가령, "Pong에서는 블럭들이 층별로 색이 다르다." 와 같은 것도 World State라고 할 수 있는데, 사실 이러한 내용은 Agent에게는 전혀 쓸데없는 내용인 것과 같은 것입니다.
그 반면, Agent State는 Agent가 특정 선택을 할 때 사용할 수 있는 정보입니다.
이러한 World State와 Agent State의 관계는, 인간의 시야로 예를 들 수도 있습니다.
우리 시야는 약 180도가량을 볼 수 있습니다. 이때, 이 우리의 시야 안에 들어오는 것들이 바로 Agent State입니다.
하지만, 세상은 우리가 보는 이 180도만 있는 것이 아니라, 내 뒤나 위나 아래에도 세상이 있습니다. 우리의 시야 안에 들어와 있지는 않지만, 확실히 존재하는 세상입니다. 이것이 바로 World State입니다.
아무튼, 다시 Agent State 이야기로 돌아오겠습니다. 아까 전에 State는 History의 함수라고 할 수 있다고 했었죠?
이때의 State는 보통 Agent State를 의미합니다. (World State는 어차피 Agent가 모르는 정보라서 크게 의미가 없습니다.)

이번엔 Markov Assumption에 대해 알아봅시다.
Markov Assumption이란, 충분한 정보가 담긴 State가 존재할 때,
이 State만으로 예측한 미래가 History로 예측한 미래와 같을 때, 이를 Markov 한 State라고 합니다.
즉, 현재의 State 하나만 주어지더라도, 지금까지의 모든 History와는 관계없이 미래를 예측할 수 있다고 하는 것입니다.
다시 말해, 미래를 예측하는 데는 과거에 대한 정보가 필요 없고, 그냥 그런 정보들을 잘 모아놓은 현재의 상황, State만이 필요하다는 것입니다.

그렇다면, 한번 예시를 들어 설명해 보겠습니다.
첫 번째로, 고혈압 조절을 예시로 들어보겠습니다.
State를 현재 혈압 수치라고 하고, 약을 투여할지 하지 않을지를 결정하는 것은 Markov 하다고 할 수 있을까요?
그렇지 않을 것입니다. 왜냐하면, State는 현재 혈압 수치만을 알려주기 때문에, 내가 지금 운동을 해서 혈압이 높아진 것일 수도 있고, 공포영화를 봐서 혈압이 높아진 것일 수도 있는데 현재의 혈압만을 보고 약을 투여할지 여부를 결정하는 것은 옳지 못하기 때문입니다.
두 번째로, 웹사이트 쇼핑 인공지능입니다.
State를 현재 구매자가 보고 있는 상품이라 하고, 그 구매자에게 어떤 다른 상품을 추천할지를 결정하는 것은 Markov 하다고 할 수 있을까요?
이것도 마찬가지로, Markov가 아닙니다. 지금 보고 있는 상품이 그냥 심심해서 랜덤으로 들어온 상품일 수도 있고, 광고를 잘못 눌러서 들어온 상품 페이지일 수도 있는데 그 사용자에게 다른 상품을 무작정 추천하는 것을 좋지 못한 행동이기 때문입니다.

그런데 왜 Markov Assumption을 사용할까요?
왜냐하면, 일반적으로 State를 잘 설정한다면, 언제나 Markov 하다고 말할 수 있기 때문입니다.
가령, State를 그냥 History 전체라고 한다면, 그 State는 언제나 Markov 하다고 할 수 있습니다. (결국 st = ht이므로..)
그리고, 실제로 대부분 최근의 Observation들만으로도 충분한 정보가 담긴 State가 됩니다.
즉, 가장 최근의 Observation만으로 이루어진 State도 Markov하다고 할 수 있는 경우가 많은 것이죠.
그리고, State는 사실 정확하면서도 작은 것이 좋습니다.
State가 커버리면, 연산하기에도 너무 어렵고, 데이터를 가져오는 것도 힘들며, 결과를 내는 성능에 영향을 끼칠 수도 있기 때문입니다.
가령, 우리 인생의 State가 우리 인생 History 전부라고 했을 때,
그 State를 어떻게 연산하는 것은 손도 못 댈 일이 될 것이며,
그 History의 데이터를 수집하는 것도 어려운 일이 될 것입니다.
또한, 모든 History를 그냥 State에 넣어버리면, 모든 각각의 State는 다른 것이 되므로, (가령, 팔을 들어 올리는 행위 하나만 봐도 최소한 몇 mm 정도는 차이가 날 것이므로...) 그것들만으로 미래를 예측하는 것이 힘들어져 결국 성능이 저하되는 결과를 불러오는 것입니다.
이러한 단점들은 사실 Deep Reinforcement Learning에 들어와서는 서서히 사라지고 있긴 하지만, 아무튼 우리가 지금 배울 내용들에 대해서는 굉장히 중요한 사안입니다.
.....까지가 40분 내용입니다;;
이렇게 쓰다간 한도 끝도 없이 길어질 것이 뻔하므로, 여기서 대충 마치도록 하고,
다음 시간부터 MDP에 대해 알아보도록 합시다!
'인공지능 > 강화 학습 정리 (CS234)' 카테고리의 다른 글
| 강화학습 강의 (CS234) 6강 - CNN + DQN (Deep Q Network) (0) | 2019.06.06 |
|---|---|
| 강화학습 강의 (CS234) 5강 - Value Function Approximation (4) | 2019.05.27 |
| 강화학습 강의 (CS234) 4강 - MC / SARSA / Q-learning (1) | 2019.05.08 |
| 강화 학습 강의 (CS234) 3강 - Model-Free Policy Evaluation (Monte Carlo / Temporal Difference) (3) | 2019.04.21 |
| 강화학습 강의 (CS234) 2강 - Markov Process / MDP / MRP (2) | 2019.04.15 |
텐서플로우 - Linear regression 코드 정리
- 파이썬을 거의 모르는 사람도, 코드를 이해 가능할만큼, 함수와 기타 등등이 뭔지 정리함.
- 내가 강의할때 보거나 할것.
* 텐서플로우가 어떻게 돌아가는지에 대한 이해는 있어야함!
모르면 머신러닝 포스팅 lab 1&2 보기
import tensorflow as tf'텐서플로우' 라는 패키지를 불러와서, 그 이름을 "tf" 라고 하자.
* as tf 안하면 tensorflow 관련 함수 호출할때 tensorflow.~~~ 해야되는데,
as tf 하면 tf.~~~하면 됨, 아주 간편함!
x_train = [1, 2, 3, 4]
y_train = [0,-1,-2,-3]x,y값을 일단 선언해둠. (데이터를 이걸로 할거라 미리 저장해 놓는 것)
# Placeholder 설정
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# 변수 설정
W = tf.Variable(tf.random_normal([1]))
b = tf.Variable(tf.random_normal([1]))tf.Placeholder 뜻 : 지금 미리 값을 넣어두는 것이 아니고, 나중에 sess.run 할때 데이터를 집어넣을 것임.
뭔소린지 모르겠다면 머신러닝 포스팅 lab 1&2로 가서 확인할 것.
tf.Variable 뜻 : 텐서플로우의 변수선언.
tf.random_normal([1])) 뜻 : [1] 크기의 랜덤한 (정규분포를 따르는) 수를 생성함.
Linear regression 코드이므로, W,b값이 각각 하나이기 때문에 [1] 씩만 생성함.
hypothesis = X * W + bLinear regression 의 Hypothesis function H(x) = W*x + b 를 hypothesis로 선언함.
cost = tf.reduce_mean(tf.square(hypothesis - Y))Cost function이었던
$$(H(x) - y)^2 을 각각의 데이터 m개에 대하여 모두 더하고, m으로 나누어 평균을 구함.$$
을 구현한 것.
tf.square 뜻 : 제곱.
tf.reduce_mean 뜻 : 평균.
* hypothesis 는 x*W + b이고, x 는 크기 4의 배열이라 계산된 총 크기는 [4],
y도 [4] 이므로 둘이 빼면 그냥 다 더한거랑 똑같은 게 됨.
train = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)Gradient Descent 방법을 이용하여 train함.
minimize(cost) : cost를 최소화 시킬것임.
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(1001):
sess.run(train, feed_dict={X: x_train, Y: y_train})
if step%50 == 0:
W_val, b_val, cost_val = sess.run([W, b, cost], feed_dict={X: x_train, Y: y_train})
print(" < Step : %d>" %step)
print("Cost : ",cost_val,"\nW :",W_val,"\nb : ",b_val,"\n\n")
# evaluate training accuracy
print(f"W: {W_val} b: {b_val} cost: {cost_val}")session을 열음.
sess.run(tf.global_variables_initializer()) 뜻 : 아직 초기화되지 않은 (값이 박히지도 않은) 변수들을 죄다 초기화해줌.
이거 안하면 변수 터짐.
for step in range(1001) : 뜻 - 0부터 1000까지 돌릴것 ㅎ
sess.run(train, feed_dict = {X: x_train, Y: y_train}) 뜻 : train 함수를 실행시킴 (minimize(cost) 한것)
cost에는 tf.square(Hypothesis - Y) 가 있으니 Y값이 필요할 것이고,
Hypothesis 에는 X*W + b가 있으므로 X값이 필요함.
그 두개의 X,Y를 아까 선언해뒀던 x_train, y_train값으로 집어넣음.
if step%50 == 0: - step이 50의 배수일때 (50,100,150,200 ... , 1000번째 step에서 : )
W_val, b_val, cost_val = sess.run([W, b, cost], feed_dict={X: x_train, Y: y_train}) 뜻 :
W_val, b_val, cost_val 에 각각 W,b,cost의 값을 집어넣음.
cost의 값에는 위에서 언급했듯이 X,Y 둘다 있으므로, feed_dict 로 X,Y값으로 넣어줌.
아래는 간단한 print이므로 설명 생략.
끝~
'인공지능 > 딥러닝 개념 정리노트' 카테고리의 다른 글
| 딥러닝 개념정리 노트 - 머신 러닝 / Supervised learning / Unsupervised learning (0) | 2019.04.02 |
|---|
딥러닝 개념정리 노트 - 머신 러닝 / Supervised learning / Unsupervised learning
- 설명 없이 간단하게 딥러닝 관련 용어 및 개념을 정리합니다.
Machine Learning (머신러닝) : 컴퓨터가 학습할 수 있도록 하는 알고리즘과 그 기술
사용하는 이유 : 명시적 프로그래밍으로 코드를 짜기엔 너무 어려운 문제들이 많음. 예) 스팸 메일 필터링
머신러닝의 종류
Supervised learning (지도학습) : 이미 답이 정해져 있는 데이터 (Training set)를 바탕으로 컴퓨터를 학습시킴.
사용 예시) 물체 인식 및 구분 (CIFAR 10), 손글씨 식별 (MNIST), 욕설 차단 프로그램
Unsupervised learning (비지도학습) : 답이 정해져 있지 않은 데이터를 바탕으로 컴퓨터를 학습시킴.
사용 예시) 구글 뉴스(https://news.google.com), 단어 군집화 (word clustering) 등
Training data set : 머신러닝 모델을 학습시키는데 필요한 데이터의 집합.
가령, 손글씨 인식 문제에서는 손글씨와 그 손글씨가 뭐라고 적혀있는지에 대한 정답,
단어 군집화 문제에서는 수많은 단어들.
+ Reinforcement Learning (강화 학습) : 데이터 없이 컴퓨터 혼자 학습하는 것.
에이전트 (컴퓨터)가 주변 상황 및 현재의 상황을 스스로 인식하여, 가장 좋은 방법으로 행동을 취하게 함.
예) 알파고, Atari Pong AI (https://www.youtube.com/watch?v=PSQt5KGv7Vk)
Supervised learning 의 종류
1. Regression (회귀)
Regression이란, "통계학에서, 회귀 분석은 관찰된 연속형 변수들에 대해 두 변수 사이의 모형을 구한 뒤 적합도를 측정해 내는 분석 방법이다" 위키백과 펌.
쉽게 말하자면, 그냥 원래 있는 데이터들을 바탕으로 다른 데이터들에 대한 정답 구하기.
예) 시험 성적 예측하기
2. Classification (분류)
2-1. Binary Classification (이진 분류)
두 가지 정답으로 이루어진 것들을 분류하는 것.
예) 어떤 사진이 개의 사진인지 / 고양이의 사진인지 구분하는 것
예2) 메일을 봤을 때 이게 스팸메일인지 / 그냥 일반 메일인지 구분하는 것
2-2. Multi-label Classification (Multinomial Classification이라고도 불림, 다중 분류)
세 가지 이상의 정답으로 이루어진 것들을 분류하는 것.
예) 손으로 쓴 숫자를 봤을 때, 이게 0부터 9까지 어떤 숫자인지 알아맞히는 것.(MNIST)
예 2) 이미지를 봤을 때, 이게 사람의 이미지인지 / 동물의 이미지인지 / 식물의 이미지인지 등으로 분류하는 것.
'인공지능 > 딥러닝 개념 정리노트' 카테고리의 다른 글
| 텐서플로우 - Linear regression 코드 정리 (0) | 2019.04.03 |
|---|
본 글은 스스로 정리 겸, 머신러닝을 처음 배우는 사람들도 쉽게 머신러닝을 배울 수 있도록 쓴 글입니다.
수학적 지식이 부족하더라도, 머신러닝이 어떻게 돌아가는지 최대한 쉽게 이해할 수 있도록 적는 것을 목표로 하고 있습니다.
sung kim 님의 '모두를 위한 딥러닝'의 자료를 사용하여 설명합니다.
* lab 1 이번 lab 2와 병합하여 설명하겠습니다.
깃허브 주소 : https://github.com/hunkim/DeepLearningZeroToAll
이번에는 Tensorflow를 활용하여 간단하게 Linear regression 코드를 작성해 보겠습니다.

우선, 코드를 짜기 전에 저번에 배웠던 Linear regression의 Hypothesis와 cost function을 리뷰해봅시다.
H(x)는 Hypothesis function, 즉 가설 함수로 "데이터가 아마 이런 식으로 나열되어 있을 것이다." 라는 것을 예측하는 함수입니다.
Linear regression의 경우, 이름 그대로 Linear한 직선인 H(x) = Wx + b 라는 식을 사용합니다.
Cost (W,b) 라고도 쓰이는 Cost function은 각각의 데이터에 대해서 가설함수 H(x)가 얼마나 잘 피팅되어 있는지 (적합한지) 나타내는 함수입니다. 값이 작으면 작을수록 가설함수 H(x)는 데이터에 더 적합하죠.
리뷰는 대충 이정도로만 끝내고, 이제 텐서플로우가 어떻게 돌아가는지 알아봅시다.
(만약 기억이 잘 나지 않거나 한다면, 이전 포스트를 보고 와주세요.)
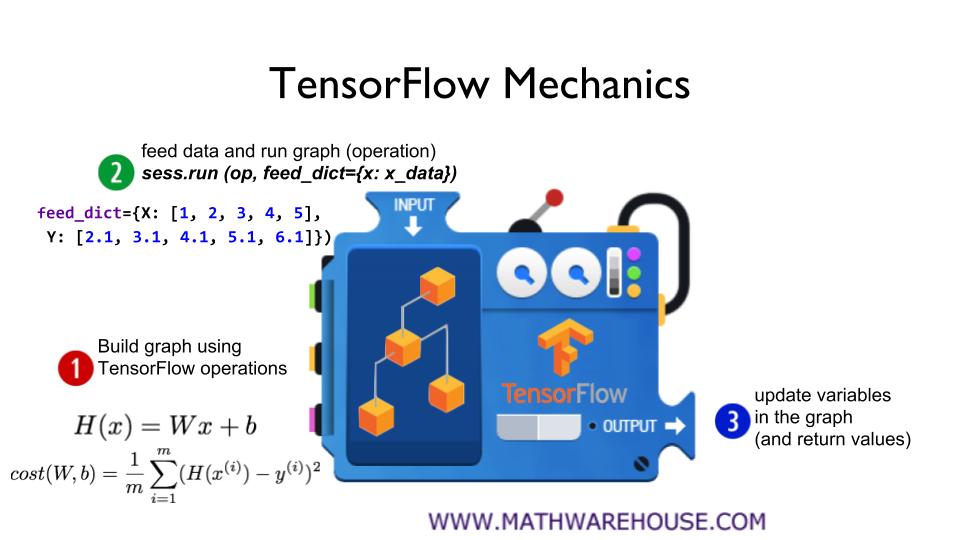
1. Tensorflow의 연산을 사용하여 그래프를 만든다.
2. 데이터를 집어넣고 그래프를 돌린다.
3. 그래프의 변수들을 업데이트하고, 값을 반환한다.
이게 뭔뜻이냐구요? 이제부터 하나하나 알아가 봅시다.
1. Tensorflow의 연산을 사용하여 그래프를 만든다.
일단 Tensorflow의 연산을 이용해서 그래프를 만듭니다.
그래프란, 우리가 만들 모델을 의미합니다.
만약 우리가 Linear regression의 모델을 만들고 싶다 한다면, Linear regression의 H(x)와 Cost function 등을 구현하는 겁니다.
이 때는 코드가 직접 돌아가는 것이 아니고, "나는 이런 모델을 만들 것이다!" 라고 컴퓨터에게 알려주는 것이죠.
자동차를 만드는 것을 예로 든다면, 자동차의 설계도를 작성하는 부분인 것입니다.
자동차의 엔진은 어떤 것을 사용할 것이고, 차체는 어떤 모양으로 만들 것이며, 바퀴는 어떻게 만들 것이고 등...
자동차를 만드는 데 있어서 필요한 모든 것들을 미리 만들어 놓는 것입니다.

다시 위 슬라이드로 돌아와서, 설명하겠습니다.
2. 데이터를 집어넣고 그래프를 돌린다.
이제 이 부분에서는 아까 전에 설계한 모델을 직접 만들고 실행시킵니다.
모델을 설계한 대로 데이터를 집어넣고, 모델에서 정의한 대로 코드가 실행되며 모든 연산들이 계산됩니다.
자동차의 예시를 다시 들어보겠습니다.
이번에는 아까 만들어놨던 설계도를 바탕으로 자동차에 필요한 재료들을 가져와서 실제로 자동차를 만들고, 직접 자동차를 타 보는 부분입니다.
차체에 타이어를 가져와서 붙이고, 엔진을 가져와서 붙이고, 그런 식으로 완성된 자동차를 직접 타는 것이죠.
Q. 왜 데이터를 1번 파트에서 집어넣지 않고 2번 파트에서 집어넣는 것인가요?
모델을 설계할 때에 데이터를 넣어버리면, 추후에 같은 모델로 다른 데이터를 집어넣기 쉽지 않다는 단점이 존재합니다.
Linear regression의 모델 하나만으로도 굉장히 많은 양의 문제를 해결할 수 있습니다.
시험점수 예측, 집값 예측 등 다양한 데이터들을 Linear regression으로 해결할 수 있다는 겁니다.
그런데 만약 설계도 처음부터 데이터를 박아버리면, 나중에 다른 데이터를 집어넣을 때 설계도 자체를 바꿔야 합니다.
자동차의 예시를 다시 가져오자면, 설계도에 자동차의 도색까지 다 해버리는 것과 비슷합니다.
똑같은 차라도 굉장히 다양한 도색을 할 수 있는데, 설계도에서부터 벌써 도색을 해버리면, 다음에 다른 도색을 하고 싶을때는 설계도를 다시 수정해야 한다는 것이죠.
일단 이정도로만 알아두고, 넘어가도록 합시다.
3. 그래프의 변수들을 업데이트하고, 값을 반환한다.
사실 이부분은, 아직까지 다뤄본 적이 없는 부분입니다.
다음 Lec 3. cost 최소화 부분에서 다루며 더욱 자세히 알아볼 것입니다.
간단하게만 말해두자면, cost를 최소화할 수 있는 방향으로 W값과 b값을 업데이트 해주는 과정 정도로 생각하시면 좋을 것 같습니다.

import tensorflow as tf # tensorflow 가져오기
#W,b값 선언하기
W = tf.Variable(tf.random_normal([1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
#Placeholder로 X,Y값 선언하기
X = tf.placeholder(tf.float32, shape=[None])
Y = tf.placeholder(tf.float32, shape=[None])코드는 자고로 몸으로 익히는 법.. 왠만하면 코드를 복사하지 말고 직접 타이핑하며 공부해 주세요.
tf.Variable : 텐서플로우에서 사용하는 변수 선언 방식으로 생각하시면 되겠습니다.
tf.random_normal([n]) : n의 크기만큼의 랜덤한 변수를 만드는 것입니다.
name선언은 나중에 그래프를 그릴 때 보기 편하라고 미리 지어주는 이름입니다.
Placeholder는 아까 설명한, Q. 왜 데이터를 1번 파트에서 집어넣지 않고 2번 파트에서 집어넣는 것인가요? 부분에 딱 들어맞는 함수로, 모델을 설계할때 직접 데이터를 쑤셔넣지 않고 나중에 2번 파트에서 집어넣기 위해 사용하는 함수입니다.
Placeholder를 쓰는 이유를 알고싶다면, 위의 Q.를 다시 한번 보고 와주세요.
X = tf.placeholder(tf.float32, shape=[None])
Y = tf.placeholder(tf.float32, shape=[None])
위의 두 줄의 코드는 X,Y를 각각 tf.float32라는 실수형 자료형으로, [None]이라는 shape로 만들라는 의미입니다.
이 때, [None]이라는 shape는 "내가 나중에 데이터 집어넣을 때 그 데이터 크기를 따라가면 돼!" 의 의미입니다.
# 가설함수 H(x) = X*W + b
hypothesis = X * W + b
# Cost function
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# 최소화 (다음 시간에..)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train = optimizer.minimize(cost)이제 데이터 선언은 끝났고, 이제 모델의 중심부를 구현해 봅시다!
가설함수 H(x)는 X*W + b 였던 것을 그대로, hypothesis = X * W + b 라고 입력해 줍시다.
cost = tf.reduce_mean(tf.square(hypothesis - Y))
이것은 무엇을 의미 하냐 하면..
tf.square(hypothesis - Y) : 가설 함수 H(x)에서 데이터를 뺀 것 만큼을 제곱하라!
tf.reduce_mean() : 그리고 () 안의 값 ( tf.square(hypothesis - Y) ) 을 평균을 내줘라!
라는 의미입니다 (대략적으로는)
optimizer = ... 부분은 나중에 lec 3 이후에, 다시 한번 정확히 설명하겠습니다.
train = optimizer.minimize
이 부분은, Cost를 최소화 시킬 것이다! 라는 의미입니다.
# 그래프 실행!
sess = tf.Session()
# 변수 초기화!
sess.run(tf.global_variables_initializer())
# 학습..
for step in range(2001):
cost_val, W_val, b_val, _ = sess.run([cost, W, b, train],
feed_dict={X: [1, 2, 3], Y: [1, 2, 3]})
if step % 20 == 0:
print(step, cost_val, W_val, b_val)sess = tf.Session()
sess.run(tf.global_variables_initializer())
위 두 코드는, 대략 이런 의미입니다.
"내가 이 위에서 짰던 모델을 실행시키고, 이제 변수들도 다 제대로 초기화 해줘!"
위에서 설명했듯, 1번 파트에서는 그저 설계도를 작성하는 부분이고, 어떤 것도 실제로 만들어지지 않습니다. 그렇기에, 변수들도 2번 파트에서 초기화 해 주어야 하죠.
그뒤의 나머지 부분들은, 2001번 만큼 모델을 학습시키겠다는 의미인데, 이것 또한 Lec 3 이후에 자세히 설명하겠습니다.
feed_dict = ...
의 부분만 설명하자면, 아까 전에 Placeholder로 지정해 두었던 부분에, 내가 넣고 싶은 데이터를 넣겠다는 의미입니다.
즉, 1번 파트에서 미리 넣어두지 않았던 데이터를 지금 집어넣겠다는 의미이죠.

위의 feed_dict 부분만 이렇게 바꿔주면, 아예 다른 데이터들을 집어넣어서도 훈련시킬 수 있습니다!
이렇게, Tensorflow로 기본적인 Linear regression 코드 작성 튜토리얼을 마치겠습니다.
다음에는 Lec 3로 찾아뵙겠습니다!
모두를 위한 딥러닝 (sung kim) lec2 - Linear regression & cost function
본 글은 스스로 정리 겸, 머신러닝을 처음 배우는 사람들도 쉽게 머신러닝을 배울 수 있도록 쓴 글입니다.
수학적 지식이 부족하더라도, 머신러닝이 어떻게 돌아가는지 최대한 쉽게 이해할 수 있도록 적는 것을 목표로 하고 있습니다.
sung kim 님의 '모두를 위한 딥러닝'의 자료를 사용하여 설명합니다.

안녕하세요. 이번 포스팅에서는 Linear regression 기술에 대해서 알아 볼 것입니다.

위의 표에 나온 것이 바로, Supervised learning에서 사용되는 Training data (Training set) 라는 것입니다.
어떤 값 x와, 그 특정한 x값에 대한 정답인 y값들이 나열되어 있는 것이죠.
위의 시험 성적 예측의 예시같은 경우, x값을 공부한 시간으로 주어주고, y값을 그 공부 시간에 따른 시험 성적으로 주어진 것입니다.
그렇다면, 우리는 위의 데이터를 보고 이런 생각을 할 수 있습니다. "공부 시간이 많을수록 점수가 높아지는구나!"
그런데, 만약 우리가 8시간을 공부한다면, 몇 점을 맞을 수 있을까요? 아마 9시간을 공부해서 나온 성적인 80점보다는 조금 낮은 점수가 나올테고, 3시간을 공부했을 때 나온 성적인 50점보단 높은 성적일 겁니다.
이렇게, 이미 갖고 있는 데이터(공부 시간당 성적)를 기반으로 특정 x값(공부할 시간)에 대한 정답인 y값(나올 성적)을 예측하는 데 사용되는 기술을 "regression" (회귀) 이라고 합니다. 그리고, 갖고 있는 데이터들은 labeling 된, 즉 이미 입력값과 그에 따른 정답이 존재하는 데이터이므로, 이것은 Supervised learning의 한 종류라고 할 수 있겠지요.

그렇다면, 이제부터 linear regression이 무엇인지 정확히 알아가봅시다.
설명을 간단히 하기 위해서, 데이터를 굉장히 단순한 형태로 놓겠습니다.
그리고 이것을 그래프에 그리면, 위의 오른쪽 그래프와 같은 형태가 될 것입니다.
X=1일때 Y=1, X=2일때 Y=2, X=3일때 Y=3 인 표와 그래프이죠.

그리고, 우리들이 알고 싶은 것은 X값이 4일때의 Y값, X값이 1.5일떄의 Y값과 같은 특정 X값에 따른 Y값입니다.
이것을 알기 위해서, 우리는 대략적인 "가설" 을 세울 필요가 있습니다. "대충 선 하나를 그으면 이 데이터를 잘 표현하는 선이 될거야!" 와 같이 말이죠.
Linear Hypothesis라 함은, 이렇게 어떤 선을 그었을 때 (일차함수를 그렸을 때) 그 선은 데이터를 잘 표현할 것이다! 하는 가설입니다.
일반적으로, 이렇게 Linear한 선으로 표현할 때 어느 정도 데이터를 잘 표현하는 경우가 많습니다. 가령, 내가 운동한 시간이 늘어나면 살도 그만큼 빠질 것이고, 공부를 한 만큼 성적도 그만큼 오르는 것도 Linear하게 표현할 수 있을 것입니다.(정확히 데이터에 들어맞는다는 것이 아니라, 어느 정도 잘 나타낼 수 있을 것이라는 겁니다.) 그렇기 때문에, 이 Linear hypothesis를 사용하는 것입니다.
그리고, 어떻게 그은 선이 가장 데이터에 적합한지를 알아가는 과정을 Linear regression의 학습과정이라고 합니다.

그렇다면 이제 선을 한번 그어봅시다! 일반적으로, 그래프 위의 선은 일차함수로 나타낼 수 있겠죠?
가령, 위의 파란 선은 y=x라는 일차함수 그래프로 표현할 수 있습니다.
이처럼, Linear한 선을 나타낼 때 사용하는 함수를 H(x)라 합니다.
그리고 H(x)는 일차함수이기에, H(x) = Wx + b 라고 둘 수 있을 것입니다. (y=ax+b와 같은 의미입니다!)
가령, 파란 선은 H(x) = 1x + 0 이라고 할 수 있고, 이떄 W값은 1, b값은 0이라고 할 수 있겠습니다.

그렇다면, 위의 세 개의 선 중 어떤 것이 가장 데이터를 잘 표현하고 있나요? 당연히 파란 색의 선이 이 데이터를 잘 표현하는 선이겠죠? 아무래도 세 개의 선 중 데이터에 가장 가까운 것이 파란색 선이니까요.
이렇게 가장 좋은 선을 알아내는 것을 조금 더 정확히 말하자면,
"H(x) = Wx + b에서, W값과 b값에 어떤 값을 대입해야 우리의 데이터에 가장 가까운 가설 H(x)가 만들어질까?"
라고 할 수 있습니다.
가령, 위의 노란색 선의 H(x)는 대략 H(x) = x/2 + 2 이므로, W=1/2, b=2 이고
파란색 선의 H(x)는 대략 H(x) = x 이므로, W=1, b=0입니다.
그리고 노란색 선의 H(x)인 W=1/2, b=2보다 파란색 선의 W=1, b=0이 더욱 우리의 데이터에 가까운 W값과 b값이 되는 것이죠.
바로 이러한 W값과 b값을 찾아내는 과정을 Linear regression의 학습이라고 합니다.
그런데, 여기엔 문제가 있습니다. 가장 적절한 W값과 b값을 찾아내기 위해서는, W값과 b값이 얼마나 좋은 값인지를 알아내야 합니다.
위에서는 직접 그림을 그려서 더 데이터에 가까워 보이는 선을 택했지만, 일일히 그렇게 직선을 그려볼 수도 없는 노릇입니다.
또, 가령 위의 노란색 선과 빨간색 선 중 어떤 선이 얼마나 더 적절한지 물어본다면, 어떻게 대답해야 할까요?

여기서 우리는 이런 아이디어를 생각해 낼 수 있습니다. "직선이 각각의 데이터를 나타내는 점들과의 거리가 작으면 작을수록, 데이터에 더 적합한 직선일거야!" 라구요.
결국, 직선을 최대한 데이터에 가깝게 놓는 것(적합하게 하는 것)이 가장 적절한 직선을 찾는 것이 우리의 목적이니까요.

그리고, "직선과 데이터가 떨어져 있는 거리"와 같이, 얼마나 우리의 직선이 데이터를 잘 맞추는지를 나타내는 것을 바로 Cost function(비용 함수) 라고 합니다. 그리고, Cost function을 통해 도출된 값은 error 또는 cost (오차값)라고 합니다.
직선과 데이터의 거리가 작으면 작을수록 좋으므로, cost는 낮으면 낮을수록 더 좋은 것이겠지요. (직선이 더 데이터에 잘 맞는다는 뜻 ㅎ)
그럼 Cost function은 어떻게 만들면 될까요?
우리의 가설 함수(직선) H(x) 에서 정답 데이터의 값 y를 빼면 되지 않을까요?
즉, Cost function : H(x) - y 라고 하면 되지 않을까요??
하지만...(그치만...) 그렇게 Cost function을 설정해버리면, 한 가지 문제가 생깁니다. 바로, 거리가 음수가 될 수도 있다는 것이죠. 위의 예시의 경우, Cost function을 H(x) - y 라고 설정해 버리면, x=1일때는 음수, x=3일때는 양수가 나와버려서 정확히 우리가 원하는, 직선과 데이터의 적합성 을 찾을 수 없게 됩니다.

그래서 고안한 식이 바로 위의 식입니다.
저 식이 의미하는 것이 무엇인고 하니, 모든 각각의 x값과 y값에 대한
$$(H(x) - y)^2$$ 을 모두 더한 후,
데이터의 개수인 m만큼 나눠줍니다. (각각의 데이터에 대한 오차의 평균값을 구하기 위함입니다.)
부연 설명을 첨가하자면...
(H(x) - y)를 제곱한 것에는 두 가지 이유가 있습니다.
첫째는, H(x) - y의 값이 음수가 아니게 하기 위해서 입니다.
위에서도 언급했듯이, 직선과 데이터의 거리가 음수이면 안되니까요.
둘째는, 너무 멀리 있는 데이터에 대해 추가적인 패널티를 주기 위해서 입니다.
Linear regression의 최종적인 목표는, 결국 데이터를 가장 잘 나타내는 직선을 찾는 것입니다.
그런데, 만약 엄청 멀리 있는 데이터에 대한 오차값과 가까이 있는 데이터에 대한 오차값의 차이가 크지 않다면,
직선이 일부 데이터에만 정확히 맞춰지고, 어떤 데이터들에 대해서는 전혀 맞춰지지 않는 경우가 발생합니다.
즉, 10만큼 멀리있으면 10만큼의 오차값을 추가하는 것이 아니라, 100만큼의 오차값을 줌으로써 최대한 직선을 많은 데이터에 맞출 수 있게 돕는 역할을 해 주는 것입니다.

결국, 최종적인 식은 다음과 같은 형태가 됩니다.
이 때, 특정 H(x)에 대한 Cost function을 위와 같이, Cost(W,b) 라고 씁니다.

자, 그럼 이제 우리의 다음 목표는, cost값을 최소화 시키는 방법을 찾는 것입니다.
결국, cost값이 낮아야 직선과 데이터의 거리가 최소화 되는 것이고,
결국 데이터와 가장 잘 맞는 직선이 나타날테니까요.
다음 포스팅에서는, cost값을 최소화시키는 방법에 대해서 알아보도록 하겠습니다.
확인문제 1. Cost function을 H(x) - y 로 설정하지 않는 이유는?
확인문제 2. Cost function에서, H(x) - y 의 값을 제곱하는 이유는?
확인문제 3. 위에서 설명한 Cost function을 사용하고,
데이터 (x,y) = { (1, 5), (2, 4), (3,2) }, 가설함수 H(x) = 2x - 1 라고 할 때 Cost값은?
답이 아리송한게 있다면, 댓글 남겨주세요!
'인공지능 > 모두를 위한 딥러닝 (sung kim) lec' 카테고리의 다른 글
| 모두를 위한 딥러닝 부록편 - 미분의 개념과 Gradient Descent (1) | 2019.05.10 |
|---|---|
| 모두를 위한 딥러닝 (sung kim) lec5 - Logistic Classification (로지스틱 회귀분석) (0) | 2019.05.09 |
| 모두를 위한 딥러닝 (sung kim) lec4 - Multivariable Linear Regression (다변수 선형 회귀) (1) | 2019.04.09 |
| 모두를 위한 딥러닝 (sung kim) lec3 - Gradient Descent (경사하강법) (0) | 2019.04.08 |
| 모두를 위한 딥러닝 (sung kim) lec1 - 머신 러닝 기초 (0) | 2019.03.28 |
모두를 위한 딥러닝 (sung kim) lec1 - 머신 러닝 기초
본 글은 스스로 정리 겸, 머신러닝을 처음 배우는 사람들도 쉽게 머신러닝을 배울 수 있도록 쓴 글입니다.
수학적 지식이 부족하더라도, 머신러닝이 어떻게 돌아가는지 최대한 쉽게 이해할 수 있도록 적는 것을 목표로 하고 있습니다.
sung kim 님의 '모두를 위한 딥러닝'의 자료를 사용하여 설명합니다.
+ lec 0은 따로 작성하지 않겠습니다.


이번 Lecture 1에서는, 머신러닝이 무엇인지 간단하게 알아보고, supervised & unsupervised, regression, classification이 무엇인지 간략하게 알아보도록 하겠습니다.

머신러닝은 'explicit programming', 즉 '명시적 프로그래밍'의 한계에서 착안한 기술입니다.
가령, 우리가 스팸메일을 필터링하는 프로그램을 작성해야 한다고 해봅시다. 어떤 점들을 고려해야 할까요?
일단 메일 내용이 이상한 기호로 도배되어 있는지 확인하고, 특정 상표명으로 도배되어있는지 확인하는 등 굉장히 많은 점들을 고려해야 할 것입니다. 그런데 그렇게 고려한다 한들, 스팸메일이 완벽하게 막히긴 할까요?

정말 어떻게 프로그래밍을 짠다 해도, 정말 오묘하게 글을 바꿔버린다던지, 정상적인 메일을 쓰는 척하면서 광고를 한다던지 등의 사례에 다 뚫려버리고 말겠죠? 위 사진처럼 스팸메일이 사진으로 온다면?? 더 필터링하기 힘들어질 것입니다.
머신 러닝은 이러한 explicit programming을 보완하기 위하여 만들어진 기술로, 인간이 직접 프로그래밍을 하지 않아도 컴퓨터가 알아서 학습하게 하여 explicit하게 programming을 하지 않아도 되게 만들어 줍니다. 가령, 우리가 명시적으로 어떤 어떤 글들을 막아라!라고 하지 않아도 알아서 글을 분석해서 막아준다는 것이죠.

그럼 이제부터 머신러닝의 종류 (학습 방법의 종류)에 대해서 알아보겠습니다.
첫 번째는 Supervised learning(지도 학습) 입니다.
Supervised learning은 인간이 직접 컴퓨터에 답이 정해진 데이터들을 입력하여 컴퓨터를 학습시키는 방법입니다.

Supervised learning의 예시 중 하나는, 이미지들을 고양이, 개, 머그컵, 모자 등과 같은 것들로 분류하는 것입니다.
우리가 컴퓨터에게 고양이 사진들을 "이 사진은 고양이란다!" 라고 알려주며 데이터를 입력하면, 컴퓨터가 그 데이터를 바탕으로, 다른 이미지들을 입력받아도 "아! 이건 고양이구나!" 하고 분류할 수 있게 하는 것이죠.

다음은 Unsupervised learning(비지도 학습)입니다.
이것도 Supervised learning과 마찬가지로 컴퓨터에게 데이터를 입력한다는 것은 동일하지만, 이번에는 답을 주지 않은 채로 컴퓨터에게 데이터를 입력합니다. 즉, 아까처럼 '이 사진은 고양이란다!' 하며 데이터를 던져주지는 않는다는 것이죠. 그리고, 그 상태로 컴퓨터가 알아서 데이터를 분류하도록 학습합니다.
가장 좋은 예시중 하나는 구글 뉴스입니다.

구글 뉴스는 위와 같이 여러가지 주제들을 바탕으로 뉴스를 제공합니다. 그중 사용자가 보고 싶어 하는 주제에 대해 "전체 콘텐츠 보기"를 선택하면, 그 주제에 대한 기사가 주르륵 나옵니다.
이런 인공지능은 어떻게 만들까요? 아까 전의 Supervised learning을 사용하기엔, 수많은 기사들이 엄청나게 쏟아져 나오고, 매일매일 새로운 주제로 기사들이 나오는데 이것들을 죄다 labeling 하기엔, 그러니까 "이게 어떤 주제다!" 하고 컴퓨터에게 알려주기엔 너무 힘들겠죠?
이럴 때 Unsupervised learning을 사용하면 됩니다. 컴퓨터에게 뉴스 기사 분류법을 학습시키고, 우리가 던져주는 뉴스들 중 같은 주제인 것들만을 분류해 주는 것이죠.

하지만, 우리들은 앞으로 Unsupervised learning에 대해서는 딱히 언급하지 않을 것입니다.
Unsupervised learning이 애초에 Supervised learning보다 학습하기 까다롭고, 조금 더 어려운 감이 있기 때문이죠. 게다가, 많은 문제들은 Supervised learning을 활용하여 해결될 수 있습니다.

Supervised learning을 사용하는 대표적인 예시들을 들어보겠습니다.
이미지 라벨링 : 이미지들을 각각의 태그로 분류하는 작업. 위의 개/고양이/머그컵/모자 예시에 해당한다.
이메일 스팸 필터링 : 스팸메일을 분류하는 작업. 위의 "히어로즈 오브 더 스톰" 예시에 해당한다.
시험 성적 예측 : 시험 성적 예측(...). 가령, 저번 시험의 성적들과 공부한 시간을 바탕으로 다음 시험에서 몇 점을 받을지 예측하는 것.
이러한 것들을 보면, 대부분 explicit하게 프로그래밍한 경우엔 해결하기 힘든 작업들이지만, 머신 러닝을 사용하면 explicit programming을 사용하는 것보다 훨씬 수월하게 위의 문제들을 해결할 수 있을 것입니다.

그리고, 이번에는 supervised learning의 종류에 대해서 알아봅시다.
이번에는 시험 성적을 예측하는 프로그램을 만든다고 가정해보죠.
"저번에 봤던 시험 성적들과 공부 시간을 종합했을 때, 내 다음 시험성적은 몇점일까?" 와 같은, 일련의 데이터를 통해서 어떠한 값 (내 공부시간)을 입력했을 때 특정한 값 (예측된 내 시험 성적)이 나오는 문제는, regression(회귀) 문제라고 합니다.
"내가 이만큼 공부했을 때 다음 시험을 pass할수 있을까?"와 같이, 어떠한 값 (내 공부시간)을 입력했을 때 PASS/FAIL과 같이 두 가지로 분류되는 문제의 경우, binary classification(이진 분류) 문제라고 합니다.
"내가 이만큼 공부했을 때 등급을 A,B,C,D,E,F 중 뭘 맞을까?"와 같이, 어떠한 값 (내 공부시간)을 입력했을 때 여러 가지 정답(A, B, C,...)중 하나를 예측하는 문제는, multi-label classification (멀티 라벨 분류) 문제라고 합니다.
크게 보자면, 내 데이터를 입력했을 때 특정한 값 (주로 숫자)가 나왔으면 좋겠다! 하는 것들은 regression을 사용하여 해결하면 되고, 특정한 태그들 (A,B,C, ... 또는 PASS/FAIL 등)가 나왔으면 좋겠다! 하는 것들은 classification (binary/multi-label)을 사용하여 해결하면 된다는 것입니다.



이렇게 우리는 머신러닝이 무엇인지, Supervised learning / Unsupervised learning이 무엇인지, 그리고 Supervised learning의 유형들 (regression, classification)에 대해서 알아봤습니다.
그럼 여기서 확인문제!
확인 문제 1. 머신러닝은 어떤 문제들을 해결하는데 주로 사용될까?
확인 문제 2. 어떤 사진들을 특정 태그로 분류하고 싶다고 할 때, Supervised learning 과 Unsupervised learning 중 어떤 방법을 사용해야 할까?
확인문제 3. 어떤 집의 위치, 크기 등을 바탕으로 그 집의 가격을 예측하는 프로그램을 작성하고자 할 때, regression과 classification 중 어떤 것을 사용해야 할까?
만약 이 문제 중 하나라도 풀리지 않는다면, 다시 한번 공부해서 확실히 내용을 익힐 수 있도록 하면 좋겠습니다.

다음 포스팅에서는 Linear regression이라는, regression 유형 중 가장 쉬운 모델 중 하나를 살펴보도록 하겠습니다.
'인공지능 > 모두를 위한 딥러닝 (sung kim) lec' 카테고리의 다른 글
| 모두를 위한 딥러닝 부록편 - 미분의 개념과 Gradient Descent (1) | 2019.05.10 |
|---|---|
| 모두를 위한 딥러닝 (sung kim) lec5 - Logistic Classification (로지스틱 회귀분석) (0) | 2019.05.09 |
| 모두를 위한 딥러닝 (sung kim) lec4 - Multivariable Linear Regression (다변수 선형 회귀) (1) | 2019.04.09 |
| 모두를 위한 딥러닝 (sung kim) lec3 - Gradient Descent (경사하강법) (0) | 2019.04.08 |
| 모두를 위한 딥러닝 (sung kim) lec2 - Linear regression & cost function (0) | 2019.03.30 |
태풍이 부네요
정전만 아니면 좋을 것 같습니다.
'일상' 카테고리의 다른 글
| 2022년, 한 해를 돌아보며 (2) | 2023.01.01 |
|---|---|
| 안녕하세요. 7019입니다. (0) | 2018.07.23 |
누구나 이해할 수 있는 딥러닝 - cs231n 5강 (Convolutional Neural Networks, CNN)
- cs231n 5강의 내용을 정리한 글입니다.
- 최대한 쉽게, cs231n 강의를 스스로 다시 이해하며, 처음 딥러닝을 공부하는 사람들도 쉽게 이해할 수 있게 정리해보았습니다.
- 저도 초보인지라 틀리는 부분이 있을 수 있고, 이해가 안 되는 부분이 있을 수 있습니다. 만약 틀린 부분이 있거나 잘 이해가 되지 않는 부분이 있다면, 바로 댓글로 질문해 주세요! 내용과 관련된 질문은 최대한 아는 선에서 대답해 드리겠습니다!
- 보는 중에 사진들에 나오는 수식 같은 경우는, 따로 설명하지 않았다면 건너뛰어도 됩니다.
- 이해가 잘 되지 않은 설명이거나, 설명이 명확하지 않은 것 같으면, 댓글로 피드백 부탁드립니다.

이번 시간에는 Convolutional Neural Network(컨볼루셔널 신경망, 줄여서 CNN)에 대해서 배워보겠습니다!

저번 시간에 인공 신경망에 대해 *간단히* 이야기했었던 거, 기억나시죠?
위 사진을 보고 기억이 나지 않는 것이 있다면, 저번 강좌로 돌아가서 다시 한번 봐주세요!

위의 사진은 CNN의 기본 구조입니다!
물론 지금 당장 이게 뭔지는 따로 해보신 분들이 아니라면 잘 모르시겠지만, 그냥 대강 구조가 이렇구나! 하고 넘기시면 됩니다.
다만, 이번 강좌가 끝난 후 다시 보았을 때에는 정확한 이해를 해야 합니다..!

자, 그래서 CNN이 뭔지, 이제부터 알아보도록 하겠습니다.

우선, 저번 강좌에서 배웠던 Fully Connected Layer을 다시 불러와 봅시다.
32*32*3의 이미지가 있으면, 그것을 3072*1의 크기로 변환시킨 것을 input값으로 했었죠?
그리고, Wx값들은 (클래스 개수인) 10 * 3072로 만들어 둔 뒤에,
input과 Weight를 곱하여 10개의 output 값들을 만들어 내는 layer가 바로 Fully connected layer였습니다.

그렇다면, Convolution Layer은 Fully connected layer와 어떤 점이 다를까요?
일단, Convolution layer에서의 input값은 fully-connected layer와는 다르게 원형을 보존한 상태로 둡니다.
32*32*3 크기의 사진이라면, 그 사진의 크기 그대로 보존해 놓습니다.

그리고, 우리의 weight값은 위의 자그마한 filter가 될 것입니다. 이번 예에서는, 5*5*3의 크기네요.
가로와 세로의 크기는 input의 크기보다 크지만 않으면 되지만, 이 filter의 깊이는 무조건 input값과 같아야 합니다. (여기서는 3)

그리고, 이렇게 마련된 5*5*3의 크기의 filter를, 왼쪽 위부터 모든 부분마다 점곱을 해줍니다.
그러니깐.. input 사진의 왼쪽 위 5*5*3 부분에 필터를 곱한 후에, 더하는 것이죠!
그 후에, 한 칸 왼쪽으로 옮겨서 해주고.. 맨 위쪽 끝까지 갔다면 한 칸 아래로 내려서 다시 해주고.. 하는 것이죠.
마치, filter를 image에다가 대고, 쭉 밀어준다는 느낌인 것이죠.
강아지들 털 밀듯이.. 왼쪽 위부터 오른쪽으로 쭉- filter를 image에 갔다 대고 나서,
조금 더 아랫부분도 쭉- 밀어주고.. 하는 과정이죠.
아무튼 그런 뒤에, 그런 뒤에, bias까지 더해줍니다.
bias가 뭔지는.. 기억 나시죠? 편향 값이요!
위의 계산에 대해 조금 더 자세히는 아래에서 나옵니다!

그렇게 하나하나 다 곱해주다 보면, 다음과 같이 28*28*1 크기의 output이 나옵니다.
간단히 계산을 해본다면.. 왜 이런 결과가 나오는지도 계산이 가능합니다.
그리고, 이 output값은 activation map이라고 하는데, 이는 이 사진이 가지는 특징을 나타내어 주는 역할을 하게 됩니다.

그런데, CNN을 사용할 때에는, filter를 하나만 사용하지는 않습니다!
다양한 필터를 사용하여, 필터마다 다른 특징을 나타내게 만들 것이기 때문이죠.
저번 linear classification 시간에, 막 '자동차' 클래스의 weight는 빨간 자동차만을 나타내는 그림이 있었고, 말은 머리가 두 개 달려있었고.. 그랬었죠? 하지만, CNN은 그러한 단점을 없애기 위하여 다양한 필터를 사용합니다. 그만큼 다양한 특징들을 추출해 내기 위함이죠.
그리고, 필터를 두 개 사용했으니 activation map은 두 개가 나오겠죠?
각각의 필터마다 점과 계산을 해 줄 테니 말이죠.

그러면, filter 6개를 사용한다면? 당연히 6개의 activation map이 나오겠죠!
그리고, 이것을 쌓아본다면.. 우리는 28*28*6 크기의 output, 즉 activation map을 얻은 것입니다!

그런데, CNN은 위의 Convolutional Layer과 activation function의 조합이 연달아 나오는 형식의 Network입니다!
잠깐! activation function이 뭔지, 저번 시간에 언급한 적이 있는데, 기억나시나요?
Non-Linear 하고, 대표 격으로는 ReLU가 있었던, 바로 그 function입니다.
더-욱 자세한 내용은 다음 강좌 때 나올 것이니, 뭔지 모르겠어도 그냥 그러한 function을 지난다라고만 알아 두시면 될 것 같습니다.
아무튼, Convolutional Layer을 한번 지나고, ReLU까지 지난다면, 28*28*6의 크기의 activation map이 생길 것입니다.

근데 아까 뭐라고 했었죠?
이 조합을 반복하면서 진행할 것이라고 했었죠?
그렇다면, 28*28*6의 이미지에 필터를 씌우려면, 크기는 어때야 할까요?
네, 가로, 세로는 별로 상관이 없겠지만, 적어도 깊이가 6이어야겠죠? input값의 깊이가 6이니깐요!
그렇다면, 28*28*6의 이미지에 5*5*6의 필터 10개가 들어간다면 다음 activation map의 크기는?
위의 사진에서처럼, 24*24*10의 크기가 되겠지요!
필터 1번에 activation map 1겹이 쌓인다고 생각한다면, 이해가 쉽겠죠?

그런데, 우리가 지금까지 오면서 무엇을 한 걸까요?
바로, 각각의 '뉴런'들이 찾고자 하는 특징들을 뽑아낸 것입니다.
filter는, 각각의 사진에서 어떠한 부분들이 있는지에 대한 정보를 얻어냅니다.
위의 사진에서 보이듯, 처음에는 약간 low-level, 즉 간단한 특징들을 얻어낸다면,
가면 갈수록 더욱더 복잡하고, 정교한 특징들을 얻어내는 것이죠.

그리고, 각 필터마다 위와 같은 activation map이 생길 것이고, 이는 사진의 어떠한 부분의 특징을 나타내 주는 역할을 합니다.
가령, 위에서 파랗게 네모 쳐져있는 필터와 activation map을 보시면, filter는 사진의 주황색 부분을 가리키고 있고,
그에 따라 activation map은 차의 백라이트 부분의 구조(특징)를 나타내고 있는 것을 확인할 수 있습니다.

자, 조금 더 들어가기에 앞서, 큰 그림을 한번 봐봅시다.
위의 사진은 CNN의 기본적인 구조입니다.
지금까지는 CONV와 RELU까지 했다면, 이제부터는 저 POOL이나 FC 같은 것들에 대해서 알아가 보도록 합시다.

그럼 조금 더 들어가 봅시다!
아까 전에, filter를 밀어주는 것에 대해서 더욱 자세하게 가본다고 했었죠?

일단, 7*7의 input이 들어오고, 우리는 3*3의 filter로 이를 밀어준다? 고 생각해봅시다.
그러면 위의 사진과 같이 왼쪽 위부터 시작해서..




이렇게 쭉- 밀어나가며 점곱을 하게 될 것입니다.
한 칸, 한 칸씩 오른쪽으로 옮겨주면서 계산하는 것이죠.
그러면, output의 사이즈는 5*5의 사이즈가 될 것입니다. 한번 계산에 숫자 하나씩이라 하고 한번 밀어보시면 되겠습니다.

그런데, 이번엔 한 칸씩 밀지 않고, 두 칸씩 밀어보면 어떨까요?


바로 이렇게 말이죠! (아래로도 두 칸씩 내려갑니다!)
그러면, output의 크기는.. 3*3의 크기가 되겠죠? 맨 위쪽 세 개, 중간쪽 세개, 아래쪽 세 개.. 의 숫자가 나올 테니깐요.
이와 같이, 미는 정도를 stride라고 합니다.
가령, stride가 1이라면, 1칸씩 민다는 것이고..
stride가 2라면, 2칸씩 민다는 것이죠!

그런데, 7*7 사이즈의 이미지에 3*3 사이즈의 필터를, 3칸씩 밀면서 옮길 수 있을까요..?
그렇지 못하겠죠! 세 칸씩 움직여버리면, 7*7의 이미지에 3*3의 필터가 낄 수가 없으니깐요.
위의 초록색 3*3 블록을 오른쪽으로 세 칸 움직이면, 오른쪽에 딱 한 줄만 남게 되는데, 그러면 오른쪽 한 줄이 손실되는 결과를 가져오기 때문이죠.

이것은 산술적으로도 생각할 수 있습니다.
우리의 Output size는 (N-F) / stride + 1로 계산할 수 있습니다. (N=이미지 크기, F=필터 크기)
N=7이고 F=3일 때..
stride가 1이라면, output의 사이즈는 (7-3)/1 + 1 = 5,
stride가 2라면, output의 사이즈는 (7-3)/2 + 1 = 3이 되지만..
stride가 3이라면, (7-3)/3+1 = 2.33이 되므로, output의 사이즈가 성립하지 않습니다!
크기는 당연히 자연수여야 하니깐요.

그리고, Padding에 대해서도 알아봅시다.
Padding이란, 이미지의 가장자리 부분에 어떠한 숫자들을 채워 넣는 것을 의미합니다.
마치, 우리 이미지에 노스페이스 패딩을 입혀준다! 고 생각하면.. 편하지 않을까요? 아무튼 우리의 이미지가 더 두꺼워지는 거니깐요 ㅎㅎ...
그리고, 실제 우리가 작업을 할 때에는, 가장자리에 0을 넣는, zero pad를 하는 것이 일반적이라고 합니다.
그렇다면, 7*7 이미지에, stride가 1이고, padding을 1픽셀만 가장자리에 덮어씌워준다면, output의 크기는 어떻게 될까요?
아까 전에, output size는 (N-F)/stride + 1이라고 하였으므로,
이번엔 N=9 (엄밀히는 7+2), F=3, stride=1이니..
(9-3)/1 + 1 = 7이 됩니다.
즉, output은 7*7의 크기가 되는 것이죠.
그리고, 일반적인 경우엔 convolutional layer은 stride는 1로 하고,
filter 크기가 F*F라면 padding은 (F-1)/2의 크기만큼 한다고 합니다.
아니 잠시만요!! 근데 이거 왜 하는 거임;;
저거 한다고 뭐가 좋아지나요??

자, 아까 전의 슬라이드로 한번 돌아가 봅시다.
32*32*3 크기의 이미지에다가 계속해서 filter를 적용시켰을 때, 크기가 (깊이 빼고) 32*32에서 28*28, 24*24...로 빠르게 줄어드는 것을 확인할 수 있습니다. 그러면, CONV를 한 5번만 해도, 크기가 12*12 정도로 줄어들 터인데, 이는 사진의 부분적인 요소들을 보존하자는 취지를 생각하면.. 별로 좋지 못하다는 것을 쉽게 알 수 있습니다.

그런데, 만약 10개의 5*5 사이즈의 filter에 (5-1)/2, 즉 2의 크기인 pad를 해준다면, output의 사이즈는?

아까 전의 공식인, (N-F)/stride + 1을 가져온다면,
N은 패딩 때문에 32+2*2인 36이 되었으므로,
(36-5)/1+1 = 32가 되고,
filter의 개수는 10개였으니깐, 총크기는 32*32*10의 크기가 될 것입니다!
오잉?? 크기가 보존되었죠?
이것이 바로 padding을 사용하는 이유입니다.
계속되는 convolution 과정에서, 사진의 크기를 그대로 유지시켜 주는 역할을 padding이 해 주는 것이죠.

그렇다면 여기서 질문!
32*32*3 사이즈의 input에다가, 10개의 5*5 필터를, stride 1, pad 2로 해놓는다면
위 layer에서의 parameters (더 간단하게는, filter에 있는 수의 개수)는 몇 개나 될까요?

일단 filter는 5*5*3이어야 하는데, 여기에 bias값까지 더해주어야 하므로, 각각의 필터에는 5*5*3+1개, 즉 76개의 parameter들이 있습니다.
그리고, filter는 10개라고 하였으므로, 총크기는 76 * 10 = 760개가 되겠죠?

자, 여기까지 왔습니다!
위의 슬라이드를 보며 지금까지의 내용을 정리해봅시다!
만약 W1*H1*D1의 크기인 input을 받았다면, (W=가로, H=세로, D=깊이)
필터의 개수인 K, 그들의 크기인 F, stride의 크기인 S, 그리고 padding의 수인 P가 각각 필요할 것입니다.(모두 hyperparameter입니다.)
그리고 이러한 필터들이 들어간다면
W2 = (W1 - F + 2*P) / S + 1,
H2 = (H2 - F + 2*P) / S + 1,
D2=K인 output값 W2*H2*D2가 만들어질 것입니다.
(기본적인 output size공식이 (N-F)/stride + 1 이기 때문이죠.)
그리고, Paramters의 개수는 (F*F*D1)*K + K가 될 것입니다.

그리고, 일반적인 세팅을 조금 말씀드리자면..
K는 2의 제곱, 일반적으로는 32,64,128,512 등이 사용되고,
F=3, S=1, P=1
F=5, S=1, P=2
F=5, S=2, P=?(아무거나 맞는 걸루다가)
F=1, S=1, P=0
등이 자주 사용됩니다.

그리고, 위의 예시들 중
F=1, S=1, P=0 이 있었는데, filter의 크기가 1*1이어도 되나? 생각하실 수도 있겠지만..
그래도 됩니다! padding이 없어도 크기가 그대로 유지되며, 다음 activation map도 아무런 탈 없이 나옵니다!
이러한 F=1을 사용하는 Convnet들도 존재하고요.. 나중에 더 자세히 파보시면 되겠습니다!


그리고, 위의 것들은 각각 Torch, Caffe라는 프레임워크를 사용하여 구현한 CNN입니다.
뭐.. 지금 딱히 중요한 건 아니고, 그냥 이런 프레임워크들을 사용해서 CONVnet을 짤 수 있다고요.(그리고 나중 가면 다 쓰게 될 거고..)
그리고 이 아래부턴 또 두뇌랑 어떤 연관이 있는지에 대한 부분인데..
제가 몰라서.. ㅠㅠ 죄송합니다...
그런데 그렇게 중요한 부분은 아니라.. 일단 거르도록 하겠습니다..





요기서 다시 시작!
저번에 Fully-connected Layer 했던 거.. 기억나시죠?
위에서도 한번 슬-쩍 말했었고요.
이거 일단 기억한 상태로, 다음으로 넘어가 봅시다.

자, 다시 이 사진으로 돌아와서 봅시다.
이제 우리가 해야 할 것들이 눈에 보이죠?
방금까지 CONV와 RELU를 끝냈으니.. 이번에는 POOL과 FC를 할 차례입니다!

Pooling 은 activation map의 크기를 downsampling 하는 과정을 이야기합니다.
즉, 이미지의 크기를 줄이는 것이죠.
'아니.. 아까 전에 이거 안 줄이려고 padding 한다며요? 근데 이번엔 또 왜 줄인대?'
왜 그러냐면.. 아까 전의 padding을 한 것은 크기 보존뿐만 아니라, 이미지의 부분적 특징을 살리기 위해서 한 것이었습니다.
계속해서 convolution을 한다면, 가장자리 부분의 특징이 잘 살아나지 못하니깐요.
하지만, 이번에 하는 pooling은, 이미지의 특정 부분을 잘라내는 것이 아니라, 사진 전체 부분을 유지한 상태로 픽셀만 줄이는 것입니다.
게임의 해상도를 줄이는 것을 생각하면 이해하기 편합니다. 1920*1080 해상도로 게임하다가, 딱 그 반 크기로 게임을 한다면, 전체적인 화면은 똑같겠지만, 뭔가 조금 화질이 안 좋다는 느낌이 팍 들겠지요?
뒤로 가면 갈수록 filter의 개수가 늘어나는 것이 일반적인데, 이런 식으로 늘여가다 보면 activation map의 깊이가 너무 깊어지게 되고, 위와 같이 224*224*64 같은 크기의 이미지가 되어 버립니다.
그런데.. 이렇게 된다면 계산하는 데에 너무 오랜 시간이 걸려서, 뭘 할 수도 없는 지경에 이르게 되겠지요?
하지만, pooling을 해서 activation map의 크기를 반으로 팍 줄여준다면.. 계산도 두배로 빨라지게 될 것입니다!
이것도 게임을 생각하면 편합니다. 해상도를 줄이면, 그래픽카드와 CPU가 해야 하는 연산이 조금 더 줄어드므로.. 렉 걸리던 게임도 잘 돌아가게 되겠죠?

Pooling의 가장 대표적인 방법으로는 MAX POOLING이란 것이 있습니다.
우선, 이 pooling layer의 filter를 준비합니다. (이 filter에는 parameter들이 있는 것은 아닙니다.)
위의 예에서는 4*4 크기의 사진에 2*2 크기의 filter로, stride는 2로 pooling을 합니다.
그러고 나서, filter를 convolution 하듯이 이미지에다가 MAX 연산을 해 줍니다.
위의 예에서는 빨간 부분이 처음 필터가 가는 곳인데, 저 위에 필터를 씌운다면, 1,1,5,6중 가장 큰 6만을 남겨놓고 나머지 숫자들은 모두 지워버립니다.
그 뒤, stride가 2이므로 오른쪽으로 두 칸 옮겨서 초록색 부분으로 갑니다. 그 뒤에, 다시 MAX 연산을 해서 2,4,7,8중 가장 큰 수인 8만을 남겨놓고 나머지는 다 지우고.. 뒤의 노란색, 파란색 부분도 마찬가지로 진행됩니다.
여기서 주의해야 할 점은, 일반적으로 stride는 filter끼리 서로 겹치는 것은 지양해야 합니다.
가령, 위의 stride가 1이라면, 빨간 부분과 초록 부분 사이에 걸치는 부분이 생기게 되는데, 이러면 조금 곤란해진다는 것이죠.
아예 안된다는 것은 아니지만.. 자주 그렇게 설정하지는 않습니다.

이와 관련된 공식 또한 존재합니다.
W1*H1*D1의 이미지가 있다고 했을 때,
pooling layer의 filter 크기 F, stride인 S가 있다면,
W2=(W1-F)/S + 1
H2=(H1-F)/S + 1
D2=D1
인 W2*H2*D2의 크기의 이미지가 됩니다.
참고로, Pooling layer에는 zero-padding을 하는 것은 일반적이지 않습니다.
일반적으로는, 저 위의 예처럼 F=2, S=2의 filter를 사용합니다.

드디어 마지막, FC Layer, 즉 Fully Connected Layer만 남았습니다!
저번 인공 신경망 시간에 Fully Connected Layer 했었던 기억.. 나시죠? 위에서도 했고요!
convolution 하고, ReLU도 해주고, Pooling도 하고.. 이 과정들을 반복하면서 나온 가장 마지막 activation map들의 pooling까지 끝났을 때, 우리는 그 이미지들을 FC Layer에 집어넣습니다.
일반적인 인공 신경망과 마찬가지로, 각각의 클래스마다 점수를 도출해 내기 위함이죠. 이렇게 한다면, 인공 신경망처럼 '자동차' 점수, '트럭' 점수 등등이 나오며, Loss 값도 구할 수 있을 것입니다.

https://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
위 링크를 따라 들어가시면, 직접 각 사진들의 activation map들도 보고, weight들도 보고, training 과정도 관여할 수 있습니다.
그냥 심심하면 들어가서 한번 봐보시고, 아니면 그냥 걸러도 됩니다.

이렇게, CNN에 대한 내용들을 모두 배웠습니다.
CNN은 CONV, POOL, FC layer들을 쌓아 올린 형태의 network입니다.
요즘 트렌드는 filter를 자그마하게 만들고, 더욱 깊은 아키텍처를 만드는 것이고, POOL과 FC layer를 빼서 그냥 CONV만 하게 만들기도 한다고 합니다.
일반적인 아키텍처(전체적인 구조)는 일반적으로,
CONV-RELU 여러 번 한 다음 POOL 하고.. 하는 것을 몇 번 반복해 주고, 마지막에 FC와 ReLU 몇 번 한 다음 SOFTMAX로 loss를 찾습니다.
최근의(2017년 기준으로) ResNet/GoogLeNet 같은 경우에는 이런 패러다임을 따르지 않았다고 하네요.
자, 이제 진짜 끝입니다!
CONV 하는 과정 및 이유, 장점과 Pooling, Padding, FC layer에 대한 내용까지 모두 이해하셨으면 좋겠군요.
아까 말했던, 저 위의 이미지를 다시 보면서, 하나하나 모두 기억이 나는지 확인해 보시는 것도 좋을 것 같습니다.
다음 강좌 내용은 인공신경망의 activation function(ReLU 그거 맞아요!), initialization, dropout, batch normalization 등에 대해 배우겠습니다.
그럼, 다음 강좌 때 봅시다!
'인공지능 > 누구나 이해할 수 있는 딥러닝(cs231n)' 카테고리의 다른 글
| 누구나 이해할 수 있는 딥러닝 - cs231n 4강(Backpropagation and Neural Networks) (0) | 2018.07.25 |
|---|---|
| 누구나 이해할 수 있는 딥러닝 - cs231n 3강(Loss Functions and Optimization) (6) | 2018.07.17 |
| 누구나 이해할 수 있는 딥러닝 - cs231n 2강 (2) | 2018.07.15 |
누구나 이해할 수 있는 딥러닝 - cs231n 4강(Backpropagation and Neural Networks)
- cs231n 4강의 내용을 정리한 글입니다.
- 최대한 쉽게, cs231n 강의를 스스로 다시 이해하며, 처음 딥러닝을 공부하는 사람들도 쉽게 이해할 수 있게 정리해보았습니다.
- 저도 초보인지라 틀리는 부분이 있을 수 있고, 이해가 안 되는 부분이 있을 수 있습니다. 만약 틀린 부분이 있거나 잘 이해가 되지 않는 부분이 있다면, 바로 댓글로 질문해 주세요! 내용과 관련된 질문은 최대한 아는 선에서 대답해 드리겠습니다!
- 보는 중에 사진들에 나오는 수식같은 경우는, 따로 설명하지 않았다면 건너뛰어도 됩니다.
- 이해가 잘 되지 않은 설명이거나, 설명이 명확하지 않은 것 같으면, 댓글로 피드백 부탁드립니다.

이번 강좌에서는, Backpropagation(역전파법)과 Neural Network(인공 신경망)에 대해서 알아보겠습니다!

우선, 저번 시간 복습부터 시작하겠습니다.
위의 scores function으로 각 클래스마다의 점수를 구한 이후에,
그 점수를 사용해서 SVM loss (또는 softmax loss)를 구하고,
거기다가 regularization을 더해서, 총 loss를 구한 다음에,
그 loss를 가장 적게 만들어 봅시다.

그런 다음, 산을 천천히 내려간다는 그 비유처럼, 조금씩 조금씩 loss가 내려가는 방향으로 분류기를 수정합니다.
이를 optimization이라고 하죠.

그리고, numerical 과 analytic, 기억 나시죠?
기울기를 조금씩 줄여주면서 optimization을 할 것이다!

그리고 지금까지 말한걸 computational graph로 표현한 것이 위의 슬라이드입니다.
그런데, 이건 그나마 f=Wx같은 간단한 거였으니깐 이런 식으로 예쁘게 그래프가 나오지, 나중에 나올 악랄한 식들도 존재하고, 그러면 그래프도 엄청나게 복잡해지고.. 이걸 하나하나 다 계산하는 건 미친 짓이라는 거죠 ㅎ

이게 대표적인 예인데, 이건 AlexNet이라는 Convolutional network를 computational graph로 나타낸 것입니다.
그게 뭐냐구요?
곧 할 거니깐, 그냥 그렇다고 알아두세요~!

이따구로 생긴, 징그럽다는 생각까지 들 정도로 이상하게 생긴 그래프도 있는데,

그걸 무수히 많이 사용하는 경우도 있으니..
저 블록 거의 하나하나마다 미분을 다 하고 있으면, 아무리 analytic이라도 엄청나게 오래 걸리겠죠?
그래서 나온 게 backpropagation(역전파법)인데... 음.. 어..
이것도 신나는 수학 시간이네요!
본격적으로 들어가기에 앞서, 드릴 말씀이 있습니다!
지금부터는 그냥 죄다 미분 및 계산에 관련된 내용입니다. 그렇기 때문에, 저런 계산에 약하신 분들은, backpropagation 부분 말미에 마지막 정리 부분만 봐주셔도 괜찮습니다!
게다가, 저조차도 계산을 잘 못하기 때문에, 중간중간 틀리는 부분이 있을 수도 있습니다.
설명 중간에 이상한 부분을 포착했다면 댓글로 저 좀 혼내주시면 감사하겠습니다 ㅎㅎ
또, 슬라이드가 이 부분은 굉장히 많습니다. 그만큼 슬라이드가 자세히 설명을 해 주고 있으니, 설명이 빈약한 부분은 슬라이드를 통해 더 자세히 이해할 수 있으면 좋겠습니다.
아무튼! 시작해 보도록 하겠습니다!

우리의 모델이 f(x, y, z) = (x+y) * z라고 해봅시다.
여기서의 예에서는 x=-2, y=5, z=-4로 두겠습니다.
그리고, q=x+y, f=q*z라고 할 때, 우리가 구하고 싶은 것은 밑의 식 세 개입니다.
f를 각각 x, y, z로 편미분 한 값을 원하는 것이죠.
왜냐고요??
입력값이 x, y, z일 때, 이 x, y, z값이 마지막 output 값에 끼치는 영향을 알고 싶은데, 그것이 바로 저 편미분 값이기 때문이죠.

자, 한번 거꾸로 가 봅시다!
일단 f를 f로 편미분 한 값은?

당연히 1!(팩토리얼 아님 ㅎ)

그러면, f를 z로 미분하면?

f=qz이므로, f를 z로 편미분 하니깐 당연히 q, 즉 3이 나옵니다!


같은 방식으로, f를 q로 미분한 값은, z인 -4가 되겠지요?


그런데, f를 y로 미분한 값은 어떻게 구할까요?
위에서 나와있는 Chain rule에 따라, f를 q로 편미분 한 값인 -4 와 q를 y로 편미분한 값을 곱해야 합니다.
그러면, q를 y로 편미분한 값은?
q=x+y이므로, q를 y로 편미분 하면 당연히 정답은 1이기 때문에
-4 * 1 = -4, 즉 f를 y로 편미분 한 값은 -4가 됩니다.
Chain rule이 뭐냐고요?
.. 우리 착한 수학자 형아들이 만들어 준거예요! 그냥 그렇구나! 하고 넘어갑시다!

마찬가지로, f를 x로 편미분 한 값도,
Chain rule을 이용하여 -4 * 1 = -4라고 구할 수 있습니다.

자, 이것을 보기 쉽게 그림으로 확인해 볼까요?
우선, x값과 y값을 입력으로 받고, f라는 함수에다가 집어넣어서 z라는 값을 얻어냅니다.
이때, 우리는 z를 x로 미분한 값과, z를 y로 미분한 값들을 얻어낼 수 있습니다.
그러고, z를 끝으로 L, 즉 loss를 계산했다고 해봅시다.
자, 이때는 역전파법을 어떻게 사용할까요?
우선, 마지막에서 시작합니다.
L을 z로 미분하는 것이죠.
그리고 나서, L를 각각 x, y로 미분한 값을 구할 때면, 아까 구해놨던 z를 x,y로 미분한 값과 chain rule을 사용하여 구할 수 있습니다!
그리고, 이 값들을 구해내는 것이죠.
이렇게, 입력값을 받아서 loss값을 구하기까지 계산해 가는 과정을 forward pass라고 하고,
forward pass가 끝난 이후 역으로 미분해가며 기울기 값들을 구해가는 과정은 backward pass라고 부릅니다.

다른 예제로는, 다음과 같은 그래프가 있는데...

얍!!!
자, 계산이 끝났습니다! 정말 쉽죠?
만약 직접 계산해보고 싶다면, 아래의 식 4개만으로도 충분히 모두 계산할 수 있으니, 한번 제대로 계산이 되었나 검산 한번 해보세요!
아니, 갑자기 왜 이렇게 스킵하냐고요? 왜 슬라이드 13개나 갑자기 넘기냐고요??
이걸 하나하나 다 계산해 보는 것에 큰 의미도 없을뿐더러, 그냥 계산 연습 수준의 예제라서 계산만 가능하다면 크게 이해하는 것에 어려움을 느끼진 않을 것이라 생각했기 때문입니다. 계산 못하면, 그냥 넘기셔도 됩니다!

그런데, 조금 특이한 점이 있습니다.
어떤 것을 미분을 하려고 할 때, 위의 sigmoid gate라고 적혀있는 저 부분만 떼서 보았을 때, 저 부분을 한 번에 미분이 가능하다는 것입니다! 즉,
0.73 부분에서 1/x부분 미분해서 -0.53, +1 미분해서 -0.53... 할 필요 없이,
그냥 한 번에 (0.73)*(1-0.73) = 0.2 라고 계산이 가능하다는 것이죠.
띠용?? 그럼 지금까지 했던 모든 미분을 죄다 한번에 할 수도 있는 거 아님?? 하실 수도 있는데..
사실 맞음! 엄청나게 긴 computational graph조차도 한방에 미분이 되게 할 수도 있습니다!
그런데.. 위에서 봤다시피 엄청나게 복잡하고, 수없이 많은 노드들이 연결되어 있는 그래프 같은 경우에는, 이게 사실상 불가능하겠죠?
그러니깐, 위의 sigmoid function과 같이 자주 사용되는 임의의 부분만 떼와서, 그 부분만 쉽게 계산할 수 있도록 하면 됩니다.
그런데 sigmoid function이 뭐냐고요??
그냥 중간에 껴들어가는 함수 언저리다~! 하고 생각하시면 됩니다. 나중에 다시 나오니깐, 뭔지 모르겠다고 끙끙대지는 마세요!

그리고, backpropagation을 하면서 자주 보일 패턴들입니다.
add gate는 덧셈을,
mul gate는 곱셈을,
max gate는 최댓값을 구하는 gate입니다.
그런데, 이것들의 backward pass를 할 때는, 조금 더 간단하게 계산이 가능합니다.
add gate가 나온다면, 이미 가지고 있던 gradient를 각각의 노드에 분배해 주면 됩니다.
mul gate가 나온다면, 현재의 gradient를 각각 숫자에 (위의 예는 x, y)에 곱해서, 바꿔치기해주면 됩니다.
max gate가 나온다면, 그냥 더 큰 쪽에만 gradient를 그대로 꽂아주고, 반대쪽은 씹고 넘어가면 됩니다.
이렇게 몇몇 gate에서는 간단하게 계산이 가능하다는 것을 알 수 있습니다.
자, 그럼 이제 위의 예제를 이 방식을 사용해서 한번 해보고 싶지 않으신가요?
저는 별로 해보기 싫으니깐 그냥 넘어가도록 하겠습니다 ㅎㅎ

그리고, 위와 같이 노드 하나에서 다른 노드 두 개로 모두 이어졌을 때, backpropagation을 수행하면 저 뒤의 두 개의 노드에서 오는 미분 값을 더해야겠죠?
반대로, 앞의 노드 하나만 바뀌어도 뒤의 노드 두 개가 모두 바뀌고, 또 그 뒤가 모두 바뀌고... 한다는 사실도 알아두시면 좋겠습니다.

그런데, 우리의 x, y, z들은 사실 어떤 한 변수가 아니었죠?
되게 여러 개가 나열되어 있는, 벡터였습니다! 그냥 수의 나열이라고 생각하시면 편해요!
그러니깐, 이런 짓거리를 벡터로도 한번 해봐야 겠.... 나요..?
.. 아니요! 안 할 겁니다!
위의 예처럼 그냥 계산만 복잡해졌다 이거지 딱히 다른 점도 없을뿐더러, 머리 터져요!!
그냥 슬라이드만 살짝궁 올려놓을 테니, 진짜로 해보고 싶으신 분들은 직접 계산 대입해서 하셔도.. 되긴.. 하는.. 데.. 비추드립니다 ㅎㅎ




아무튼, 여기까지 (간단하게나마) 했으니, 직접 한번 구현해보도록 합시다!
물론 저 위에 계산을 하나하나 다 하고 있자는 건 아니고, 그냥 어떤 식으로 이루어지는지만 확인할 겁니다.
우선, forward부분에서는 input이 주어지고, 그에 따른 loss값을 구할 수 있겠죠?
그러고 나서, backward 부분에서는 거꾸로 하나하나 미분해 가면서 미분 값들을 구하겠고요.
간단하게 하면, 이게 다예요!

쪼--끔만 더 들어가 보겠습니다.
아까 전에 gate들 중에서 mul gate를 예로 들어서 봅시다. (x, y, z는 다 벡터가 아니라 숫자라고 가정해요!)
일단, forward pass를 봅시다.
forward 부분에서의 인자 값은 간단하게 x와 y가 될 겁니다.
그리고, mul gate였으므로, x와 y를 곱해서 z값을 도출해 내고, 그 z값을 리턴하겠죠?
그렇다면, backward pass는 어떨까요?
우선, backward 부분의 인자는 어떤 것이 와야 할까요?
위 설명을 잘 읽으셨다면 아시겠지만, loss 값 L을 z로 미분한 값을 인자로 가져야겠죠?
그리고, 리턴 값은 당연히 L을 x, y로 미분한 값들이어야 할 겁니다.
우리가 backward를 하면서 구하고 싶은 값은 L를 x, y로 미분한 값이니깐요!

그리고, 위에서 설명했듯이, mul gate는 backward pass를 할떄, 서로서로 바꿔서 곱해준다고 했으니깐,
각각을 계산한 값들은 위와 같이
dx = self.y * dz
dy = self.x * dz
가 되겠죠?
이런 방식으로, forward pass와 backward pass를 구현할 수 있습니다!

물론 그걸 우리가 다 하나하나하고 있을 건 아니고, caffe 같은 라이브러리들이 대신 짜둔 것들을 우리가 써먹기만 하면 됩니다!
위에서 계산은 실전에서 그렇게까지 중요하지 않다고 한 이유가 바로 이건대, 우리가 직접 계산해야 될 것들은 별로 없기 때문이죠.

킹 갓 스탠퍼드 형님들은 이걸 저번에 배웠던 SVM과 섞어서 코드를 짜는 게 숙제라는데,
직접 해본 결과 도저히 backward pass를 짤 수가 없어서 GG 쳤었네요 ㅎㅎ
도전심이 들면 도전해보셔도 좋은데, 저처럼 이거 하느라 5시간씩 날려먹진 않으셨으면 좋겠네요..

자, 이제 정리해봅시다!
**** 이건 위에 안 읽으신 분들도 보셔야 돼요!! ****
인공 신경망은 굉장히 거대할 겁니다. 기울기, 즉 미분 값들을 하나하나 손으로 써 내려가는 것은 미친 짓입니다! (한번 해보시면 앎 ㅎ)
그래서, backpropagation(역전파법)을 사용할 겁니다.
chain rule이라는 일종의 수학 공식?을 사용하여, 모든 입력값 및 변수들에 대한 기울기를 계산해 나갈 겁니다.
그리고 이것들을 하기 위해서, 우리는 forward와 backward를 구현할 겁니다.
forward는 그냥 gate들을 거쳐가며 정방향으로 계산해 나가면서, 나오는 값들을 메모리에 저장해 나가는 것입니다.
backward는 그 값들을 토대로 뒤에서부터 계산하며 chain rule을 적용시켜, input 값이 loss값에 어떤 영향을 미치는지를 (기울기 값을) 계산할 것입니다.
여기서 나올 수 있는 질문 하나!
Q. 그런데, 굳이 거꾸로 계산하는 이유가 뭐임??
A. 정방향으로 계산하면서 하나하나 미분 값을 계산하는 것은 굉장히 연산의 낭비가 심합니다. 직접 한번 위의 예시들을 정방향으로 계산해 보면, 이미 했던 계산 또 하고 또 하는 자신을 발견하게 될 겁니다.
다른 질문 있으시면, (설명 안 했던 부분이라 하더라도) 댓글로 질문해 주시면 답변해 드리겠습니다 ㅎㅎ

그럼 이제 인공신경망을 건드려 볼까요?
아, 이번 시간에 그렇게 자세하게 들어가진 않습니다!
윗부분 읽으시면서 힘들으셨던 분들도, 쉽게 쉽게 이해하고 넘길 수 있는 부분일.. 겁니다.. 아마?

일단 인공 신경망을 우리의 신경망과 연관 짓지 말고 생각해보겠습니다.
원래 우리의 선형 분류기에서의 점수 계산은 그냥 f=W*x로 했었던 거, 기억 나시죠?
근데, 이제 그 폭을 한번 넓혀보겠습니다.
그냥 W라는 레이어 하나만을 지나는 것이 아니고, 다른 W 두 개를 지나게 만들어버리는 것이죠!
그러면 더욱 정확해지지 않을까? 하는 것이죠.
마치 초벌 된 치킨 맛과 재벌 된 치킨 맛의 차이랄까요? 물론 따로따로 먹어본 적은 없어서 잘 모르겠지만 아무튼 ㅎㅎ
위의 예에서는 f=Wx를 발전시켜
f=W2*max(0, W1x)
로 만들었습니다.
이를 조금 더 풀어보겠습니다.
우선, W1과 x를 곱해서 점수를 먼저 냅니다.
이거까지는 linear score function과 같죠?
그리고, 이 점수가 0보다 크면, W2라는 다른 레이어를 곱해줍니다. (0보다 작으면 그냥 0을 곱해줍니다!)
이렇게 이미 한번 곱해준 친구를 다시 한번 곱하는 것이죠.
그리고 이번 예에서는, W1과 x를 곱해줄 때 100개의 점수를 냅니다.
그 뒤, W2와 max(0, W1x)를 곱할 때에, 그 100개의 점수에서 10개의 점수로 줄여나갑니다.
(무조건 100개에서 10개로 줄여야 하는 것은 아닙니다! 하나의 예시일 뿐입니다!)
자, 그런데 대체 왜 max(0, W1x)라는 식이 쓰였을까요?
바로 non-linearity, 즉 비선형 식이 쓰여야 하기 때문입니다.
이에 대해서는 이후 6강에서 더욱 자세하게 다루겠지만, non-linearity 식이 중간에 껴들어가지 않는다면, 아무리 많은 레이어들을 합쳐봤자 결국 하나의 레이어와 같은 결과를 내기 때문입니다.
'어라? 그런데 그러면 max가 아니라 다른 것도 쓸 수 있지 않아요? 그냥 선형만 아니면 되는 거잖아요!'
네, 바로 그렇습니다. 위의 max(0, W1x)는 non-linearity 식 중 하나인 ReLU function이라는 것인데, 이후에 한번 나오고, 6강에서 다시 한번 보게 될 것입니다.
이 같은 non-linearity function은 위의 max(0, W1x)인 ReLU 말고도 다른 것들도 많은데, 이처럼 Linear 사이에 껴들어가는 non-linear 한 함수들을 일컬어 activation function이라고 합니다. 나중에 한번 더 나오니깐, 그때 더 자세하게 합시다!
자, 이러면 다중 레이어의 인공신경망의 기초를 알았는데, 이것을 왜 했는지가 중요하겠죠?
Linear Classifier를 배웠을 때, 한계점에 대해서도 배웠었죠?
각각의 클래스마다 하나의 사진만 나와서, 그에 최대한 가까운 사진들을 분류해내는 작업을 하는 것이었는데, 위의 그림을 보면 아시겠지만
자동차 같은 경우에는 그냥 아예 빨간 자동차의 경우만 제대로 자동차라고 인식하고, 다른 색상, 예를 들면 노란색의 차는 제대로 자동차라고 인식을 안 할 것이라고 예산할 수 있습니다.
하지만, 이와 같이 여러 개의 레이어를 덮어 씌웠다면, 중간에 100개의 h 중 하나는 빨간 자동차가 자동차라고 가리키는 노드도 있을 것이고, 노란 자동차가 자동차라고 가리키는 노드도 있을 것입니다.
그리고 이것 모두를 W2에다가 다시 한번 집어넣으니, 이젠 더욱 다양한 물체들도 인식이 가능한 것이죠.
어휴.. 슬라이드 하나에만 말할 것이 이렇게나 많다니!! 싶으시죠?
이 중에서 이해가 잘 안 되시는 것이 있어도, 걱정 말고 넘기셔도 됩니다. 어차피 5강과 6강에 걸쳐 다시 한번씩 계속 계속 설명해 드릴 테니까요.

그러면, 레이어 두 개가 아니라 세 개를 만들고 싶으면 어떻게 하면 될까요?
미리 만들어뒀던 2-layer를 그냥 따와서, non-linear 한 함수에 집어넣고, 다시 다른 레이어로 덮어 씌우면 되겠지요?
그것이 위 사진 중 가장 아래 식인,
f=W3*max(0 , W2*max(0, W1x))입니다.
그러면, 4-layer은? 5-layer은?
마찬가지로, 위의 f값에서 레이어를 하나씩, 하나씩 더 씌우면 되겠지요?

그럼 이제 조금 더, 인간의 신경망(뉴런)과 비교해볼까요?
...라고 하고 싶지만... 저는 저 뉴런의 구조와 같은 쪽에는 그냥 아예 무지한지라.. 설명이 불가능하겠네요..
그냥 우리가 방금 했던 인공 신경망이 우리 두뇌의 신경망에서 따온 것이라는 것만 알면.. 되겠습니다.
일단 슬라이드는 이해용으로 올려놓겠습니다만.. 흨 ㅠㅠ




아! 여기서부턴 다시 설명 시작 가능하겠네요 ㅎㅎ
아까 전에 Activation function부분입니다!
ReLU, 왼쪽 아래에 보이시죠? 저게 아까 봤던 max(0, W1x) 부분을 그래프로 나타낸 것입니다.
저것처럼, sigmoid, tanh, Maxout 등 다양한 친구들이 있습니다!
아 근데, 이거 지금 자세하게 다룰 거 아니고, 6 강가면 지겹도록 다루니깐, 그때 가서 봐요!

그리고, 2 레이어 인공신경망/3 레이어 인공신경망의 구조입니다.
우선 당연하게도 input layer에서 입력값이 주어질 것이고,
그다음 hidden layer라는 곳에는 x*W1값이 들어가게 되고,
output layer에서는 (위의 예에서라면) W2*max(0, W1x)가 들어가서, 결국 output에서는 점수가 뙇! 하고 나오겠죠?
3 레이어도 마찬가지로, W1*x가 첫 번째 계산, W2*max(0, W1x)가 두 번째 계산, 마지막엔 W3*max(W2*max(0, W1x))가 계산되겠죠?
이처럼, 중간중간에 모든 노드가 다음의 모든 노드에 영향을 끼치는 레이어를 fully-connected layer라고 합니다!
위의 Neural Network의 예에서도, 모든 W값들이 다음 값들에 영향을 미쳤으니, 그것도 fully connected layer라고 할 수 있겠죠?
또, 2-layer개에는 히든 레이어가 1개, 3-layer에는 히든 레이어가 2개... 이므로,
각각 1-hidden-layer 인공신경망, 2-hidden-layer 인공신경망 이라고도 불린다네요.

자, 그래서 우리는 인공신경망의 대략적인 구조를 알아보았습니다.
더욱 자세한 내용은 5강, 6강에 걸쳐 나오므로, 일단 이 정도만 알고 계시면 되겠습니다(그래도 어느 정도는 이해하셔야 합니다!)
이제 다음 강좌 때는, cs231n 5강의 내용인, CNN(Convolutional Neural Network)에 대해 알아보도록 하겠습니다!
'인공지능 > 누구나 이해할 수 있는 딥러닝(cs231n)' 카테고리의 다른 글
| 누구나 이해할 수 있는 딥러닝 - cs231n 5강 (Convolutional Neural Networks, CNN) (2) | 2018.08.01 |
|---|---|
| 누구나 이해할 수 있는 딥러닝 - cs231n 3강(Loss Functions and Optimization) (6) | 2018.07.17 |
| 누구나 이해할 수 있는 딥러닝 - cs231n 2강 (2) | 2018.07.15 |