분류 전체보기
-
Codeforces Round #635 (Div. 2) 후기 및 풀이 (A~D)2020.04.18
-
크리스마스2019.12.26
-
디미고 입학설명회 후기2019.10.20
Codeforces Round #636 (Div. 3) 문제 풀이 (A~D)


드디어 염원하던 블루 재등반 성공!!
어차피 다음 div2 풀면서 다시 떨굴 것 같긴 한데, 그래도 오프라인 개학 전까지 블루 재등반이라는 목표를 달성해서 신난다.
이번 난이도는 뭔가 Div3치고는 조금 어려웠던 느낌이었다. A번부터 뭔가 Div3답지 않았던거 같기도 하고...
저 B는 YES도 출력해야 되는지 모르고 왜 안되는지 낑낑대다가 C 풀고 나서야 알아챘다;;; 저것만 바로 풀었어도 +130도 가능했을텐데;
아무튼, 풀이나 하겠다.
https://codeforces.com/contest/1343/problem/A
Problem - A - Codeforces
codeforces.com
A. Candies
Vova는 사탕을 매일마다 구매하며, 첫날에는 x개, 둘째날에는 2x개, 셋째날에는 4x개, ... k째날에는 2^(k-1)x개의 사탕을 구매한다.
이 때, 구매한 사탕 개수 n이 주어졌을 때, k>1 (k>=2)을 만족하는 x를 구하는 문제이다.
k는 2 이상인 아무 정수나 상관이 없으니까, k=2인 경우, k=3인 경우 ... 로 나누어서 생각해 보자.
k=2인 경우, 구매한 사탕은 x+2x = 3x이므로 n이 3의 배수인 경우, x=n/3이 된다.
k=3인 경우, 구매한 사탕은 x+2x+4x = 7x이므로 n이 7의 배수인 경우, x=n/7이 된다.
계속 이런 식으로 x의 계수를 늘려주면서, n%(x의 계수)==0인 경우 x = n/(x의 계수)를 출력해 주면 된다.
또한, 무조건 입력 n은 가능한 것으로 나오고, 2^31이 넘어가는 수치는 입력으로 들어오지 않으니, 반복문은 최대 31번까지만 돌리면 된다.
등비급수를 활용하여 2^n-1으로 식을 세워도 좋고, 그냥 계속 더해줘도 좋다. 어차피 뭘 선택하든 TLE는 안뜬다.
https://codeforces.com/contest/1343/problem/B
Problem - B - Codeforces
codeforces.com
B. Balanced Array
사실상 A보다 쉬웠고, 그만큼 A보다 풀이자도 많았던 문제.
우선, n은 모두 짝수로 주어지며, n개의 배열 중 앞부분 n/2는 짝수, 뒷부분 n/2는 홀수이면서 앞부분과 뒷부분의 합이 동일한 원소 n개의 배열을 아무거나 출력해 주면 된다.
우선, n%4!=0인 경우에는, 자명하게 원소 n개의 배열을 만들 수 없다.
n이 4의 배수가 아니면, 앞부분의 원소와 뒷부분의 원소의 개수가 홀수가 되는데,
짝수+짝수+짝수=짝수, 홀수+홀수+홀수=홀수이므로 앞과 뒤의 합이 같을 수 없기 때문이다.
그렇다면 n%4==0인 경우에 어떻게 해주면 배열을 맞출 수 있을까?
여러 가지 방법들이 있겠지만, 본인은 그냥 가장 간단한 방법으로 풀었다.
예제에서 4 -> 2 4 1 5로 주어진 것을 활용해서,
n%4==0인 n이 주어졌을 때, 출력을 2, 4, 2+6*1, 4+6*1, 2+6*2, 4+6*2, .... , 1, 5, 1+6*1, 5+6*1, ...로 내게 했다.
즉, n==8인 경우에는 2 4 8 10 1 5 7 11이 나오고,
n==12인 경우에는 2 4 8 10 14 16 1 5 7 11 13 17이 나오고, ... 로 반복되는 것이다.
어차피 이렇게 하면 n이 4씩 더해질때 마다 앞부분과 뒷부분에 더해지는 값이 같이 때문에 무조건 앞부분과 뒷부분의 합이 같게 되고,
n<=200000인데 출력할 원소는 10^9보다 작기만 하면 되므로 출력 범위를 넘어설 일도 없다.
https://codeforces.com/contest/1343/problem/C
Problem - C - Codeforces
codeforces.com
D번보다 훨씬 풀기 쉬웠던 문제.
배열 하나가 주어지고, 해당 배열의 부분배열 중 양수와 음수가 번갈아 나오는 최대 길이의 부분배열의 합의 최대를 구하는 문제이다.
문제를 좀 축약시키느라 말이 어려워 보이는데, 풀이는 그냥 간단하다.
우선 생각해야 할 점은, 배열 처음부터 끝까지 부호가 동일한 구간의 모든 원소를 하나씩은 모두 가져와야 한다.
그렇지 않으면 부분배열의 길이가 최대가 되지 않기 때문이다.
그리고, 그 배열의 합의 최대를 구하기 위해서는, 각 구간에서 가장 큰 수를 찾아서 ans에 더해주면, 해당 값이 정답이 된다.
이를 대충 알고리즘을 설명하면 다음과 같다.
1.배열 첫번째부터 시작해서, a[i]와 a[i+1]의 부호가 같은지 다른지 먼저 체크를 해 준다.
2-1.만약 부호가 같다면, maxnum값을 max(maxnum, a[i])로 갱신만 해 주고 넘기면 되고,
2-2.부호가 다르다면, maxnum값을 갱신해 준 뒤 -1234567890으로 초기화 해 준뒤, ans에 maxnum을 더해주면 된다.
그냥 이렇게 진행하는 코드를 구현하기만 하면 되는 문제였다.
팁으로, 앞부분과 뒷부분의 부호가 다른지 확인하기 위해서는 간단하게 (lld)(a[i]*a[i+1])<0을 체크해 주면 된다.
저런 식으로 체크할 때 주의해야 할 점은 a의 범위를 잘 생각하고, long long을 사용해야 한다는 것이다.
또한, -1 10^9 -1 10^9 .... 처럼 배열이 주어지면 ans값이 int 자료형을 넘길 수 있다는 것도 생각해 주어야 한다.
아마도 이 문제를 틀린 사람들은 자료형이 넘어가는 것을 체크를 안해줬거나, 구현 실력 미숙이 아닐까 하고 생각한다.
https://codeforces.com/contest/1343/problem/D
Problem - D - Codeforces
codeforces.com
D. Constant Palindrome Sum
이번 contest에서 점수 떡상이냐 떡락이냐를 결정지었던 문제였다.
다행히 머리속에 풀이가 잘 떠올라 주어서 풀 수 있었지만, 못풀었다면 정말 슬플 뻔 했다.
배열의 길이 n과 k가 주어진다. 이 때 n은 짝수로만 주어진다.
그 다음에 길이가 n인 배열이 주어지는데, 이 배열의 원소들은 k보다 작거나 같다.
이 때 a[i]+a[n-i+1]의 값이 모두 같도록 배열을 바꿔주는 것이 목표이다.
(여기서 a[i]+a[n-i+1]는 그냥 팰린드롬 형식으로 1번째와 n번째, 2번째와 n-1번째... 의 합을 의미한다.)
이 때, 배열의 원소를 바꿀 때는 한번에 하나의 원소만을 바꿀 수 있고, 배열의 원소의 크기는 최대 k이다.
이 때 배열의 원소를 바꾸는 횟수의 최소값은 얼마인지를 구하는 문제였다.
우선, 한 팰린드롬 쌍(편의상 그냥 이렇게 부르겠다.)의 합을 다른 수로 바꾸기 위해선 최소 1번, 최대 2번의 변환이 필요하다.
가령 팰린드롬 쌍이 (1, 1)로 주어진 경우, 합을 k로 바꾸기 위해선 (1,k-1)로 한번, 2k로 바꾸기 위해선 (k,k)로 두 번 바꾸어 주어야 한다.
우선 가장 간단하게 생각할 만한 풀이는, 모든 팰린드롬 쌍의 합을 (k+1)로 바꾸어 주는 것이다.
한 쌍의 숫자 두개가 어떻게 주어지든, 두 숫자 중 단 한 번의 변환을 통해 해당 쌍의 합을 k+1로 만들어 줄 수 있기 때문이다.
(참고로, k+1은 쌍의 숫자로 k,k가 주어지든지, 1,1이 주어지든지에 상관없이 무조건 만들 수 있는 유일한 숫자이다.)
그렇다면, 우리는 정답은 무조건 n/2보다 작거나 같을 것이라는 것을 알 수 있다.
이제 들어오는 팰린드롬 쌍의 경우의 수를 생각해 보자.
만약 모든 팰린드롬 쌍의 합이 모두 다른 경우, 답을 어떻게 도출하면 될까?
이럴 경우엔 모든 팰린드롬 쌍의 합을 k+1로 바꾸는 경우(ans=n/2)와,
모든 팰린드롬 쌍의 합을 특정한 팰린드롬 쌍의 합으로 바꾸는 경우로 나누어 진다.
이 때, 후자가 답이 되기 위해서는 그 특정한 팰린드롬 쌍을 제외한 모든 팰린드롬 쌍에서 단 하나만의 원소를 바꾸어 주어야 하고, 이 때 정답은 n/2-1이 된다.
그렇다면 팰린드롬 쌍의 합들 중 중복하는 경우가 있다면 어떨까?
만약 모든 팰린드롬 쌍의 합을 가장 많이 중복된 팰린드롬 쌍의 합으로 바꾸는 경우를 생각해볼 수 있다.
하지만, 이렇게 했을 경우에도 답이 되기 위해선 한 쌍의 수 두개를 모두 바꾸는 경우가 중복된 팰린드롬 쌍보다 적어져야 한다.
즉, 이 문제에서 중요한 것은 "어떤 팰린드롬 쌍의 합을 특정한 수로 바꾸어 주기 위한 최소 연산 횟수"인 셈이다.
그렇다면 가장 처음 생각해 볼 만한 풀이는 이렇다.
우선, 모든 팰린드롬 쌍의 합을 찾는다.
그리고 나서, 각각의 팰린드롬 쌍의 합에 대하여, 모든 팰린드롬 쌍을 돌면서 해야 할 최소 변환 횟수를 계산한 뒤, 그 중 최소를 찾는다.
마지막으로, 그 최소값과 2/n값 중 작은 값을 정답으로 택한다.
하지만, 문제를 보면 알겠지만 팰린드롬 쌍은 최대 10만개까지 주어지고, 위 풀이는 O(n^2)이므로 시간 제한을 넘어가게 된다.
그래서 내가 생각한 풀이는, 다음과 같다.
우선 모든 팰린드롬 쌍을 돌며, 해당 팰린드롬 쌍의 합과 한 번 변환 시의 합의 최소 / 최대값을 구한다.
가령, 팰린드롬 쌍이 (3, 4)이고 k=7인 경우, 합 = 7, 합의 최소값은 (3,1)로 변환했을 경우의 4, 최대값은 (7,4)로 변환했을 경우의 11이다.
이렇게 주어진다면, 변환해야 할 합이 4이상 11이하이면 한번의 변환으로 맞출 수 있다는 뜻이고, 그렇지 않다면 두번의 변환을 거쳐야 한다는 것을 쉽게 알 수 있다.
그리고 이 최소값, 최대값을 저장해 준다.
본인같은 경우엔, map<int, int>에 key값으로 최소/최대값을 저장하고, value값으로는 최소일 경우 1, 최대일 경우 -1을 저장했다.
그리고 나서, 각각의 최소/최대 쌍에 대해, 다음과 같은 연산을 해 준다.
1. 오름차순으로 정렬된 팰린드롬 쌍의 합의 첫번째 원소를 골라서 저장한다.
2. sum+=map[key]로 sum을 구해 준다. (이 때, sum은 한번의 변환으로 해당 팰린드롬 쌍의 합을 만들 수 있는 쌍의 개수이다.)
3. 만약 현재 고른 팰린드롬 쌍의 합이 현재 key값보다 작다면, ans값을 갱신해 준다.
4. 반복이 끝나면, ans = min(ans, 2/n)으로 최종 답을 구해준다.
이 때, ans값은 다음과 같이 계산이 된다 :
ans = min(ans, sum - (해당 합을 만드는 쌍의 개수) + (n/2-sum)*2);
이렇게 해 주면, 훨씬 빠르게 ans값을 찾을 수 있다.
사실 본인이 코딩 실력이 좀 딸려서 비 효율적인 자료구조와 방법을 택했을지도 모르지만, 아무튼 뭐 풀렸으니 됐다 ^^
다른 사람의 코드를 보니 우선순위 큐를 사용할 수도 있고, 다양한 방법들이 있는 것 같다.
E,F는 그냥 읽자마자 "이건 내가 아직은 못푸는 문제다"라고 생각하고 때려쳤기 때문에 못풀었다.
언젠가 트리와 그래프 공부를 더 한 뒤에 풀어봐야겠다 ㅎㅎ
'PS > Codeforces' 카테고리의 다른 글
| Codeforces Round #635 (Div. 2) 후기 및 풀이 (A~D) (0) | 2020.04.18 |
|---|---|
| Codeforces Round #634 (Div. 3) 푼 문제들 풀이 (A~D) (0) | 2020.04.15 |
| Codeforces Round #633 (Div. 2) 푼 문제들 풀이 (A~C) (0) | 2020.04.13 |
Codeforces Round #635 (Div. 2) 후기 및 풀이 (A~D)

망 했 다!
B까지는 A한번 실수로 틀린거 빼면 기분좋게 10분컷 냈는데, C 보자마자 머리가 하얘져버렸다..
대략 1시간정도 C 잡고 있다가 때려치고 hack이나 하러 갔었는데, 조금만 더 했으면 C,D 둘다 풀 수 있었을텐데 하는 아쉬움이 남아 있다.
다음 Div3 대회가 곧 있으니까 그거 하려고 일부러 블루 안간거임 ㅎㅎ 아무튼 그런거임 ㅠㅠ
아무튼 간단하게 풀이나 해보겠다.
https://codeforces.com/contest/1337/problem/A
Problem - A - Codeforces
codeforces.com
A. Ichihime and Triangle
a,b,c,d를 입력받고, a<=x<=b<=y<=c<=z<=d를 만족하고 각각 x,y,z를 변의 길이로 하는 삼각형이 존재하도록 x,y,z를 출력하는 문제였다.
이 문제는 사실 삼각형의 존재 조건(중학수학)만 알면 쉽게 풀린다.
가장 긴 변의 길이가 다른 두 변의 길이보다 작아야 한다는 조건 말이다.
그런데, 이걸 어떻게 x,y,z에 적용할까?
물론 여러 가지 방법이 있을 수 있지만, 가장 확실하고 적절한 방법은 가장 긴 변을 두개를 만드는 것이다.
가장 긴 변의 개수가 두개라면 무조건 삼각형이 만들어지기 때문이다. (1, 100, 100으로도 삼각형이 만들어진다.)
그러면 이제 문제풀이는 끝났다. y<=c<=z이므로, y==z==c로 놓는다면 x는 a<=x<=b를 만족하는 어떤 수를 고르더라도 x,y,z로 무조건 삼각형이 만들어진다.
즉, 간단하게 a,c,c 또는 b,c,c를 출력하면 정답이다.
https://codeforces.com/contest/1337/problem/B
Problem - B - Codeforces
codeforces.com
B. Kana and Dragon Quest game
적 몬스터의 체력 h가 주어지고, Void Absorption 스킬의 사용횟수 n, Lightning Strike 스킬의 사용횟수 m이 주어진다.
이 때, 최대 n,m번 스킬을 사용하여 적 몬스터를 죽일 수 있는지 (h<=0으로 만들 수 있는지) 여부를 출력하는 문제이다.
Void Absorption 스킬은 적 체력을 반으로 깎고, 10을 회복시켜준다. (h = h/2 + 10)
Lightning Strike 스킬은 적 체력을 10만큼 깎는다. (h = h - 10)
우선, 어떤 순서로 스킬을 사용해야 최적의 스킬 사용일지를 생각해 보아야 한다.
체력을 반으로 줄이는 것은 상대방의 체력이 높을수록 효과적이므로, 적의 체력을 반으로 줄이는 것은 최대한 먼저 실행해야 한다.
두 번째로 생각할 점은, Void Absorption 스킬은 적의 체력을 회복시켜 줄 수도 있다는 것이다.
그렇다면 어떤 경우에 Void Absorption 스킬로 적 체력이 회복될까?
간단한 식으로 보자면, h < h/2 + 10, h/2 < 10, h < 20 즉 체력이 20 미만인 경우 Void Absorption 스킬을 사용하게 되면 적의 체력을 회복시킬 수도 있다는 것이다.
그리고 결국 적의 체력을 최대한 줄이는 것이 중요하므로, 적의 체력을 회복시키는 것은 결코 최적의 움직임이 될 수 없으므로, h<20인 경우에는 Void Absorption 스킬을 사용하면 안된다.
정리하자면, h>20인 경우에는 Void Absorption 스킬을 최대한 많이 사용하고, 그 뒤에 Lightning Strike 스킬을 최대한 많이 사용해 주면 된다.
코드로 나타낼 때는, 다음과 같이 나타내면 된다.
while (h>20 && n>0) h = h/2 + 10, n--;
if (h - m*10 <=0) printf("YES");
else printf("NO");
여담으로, 이 문제를 hack을 해보려고 여러 코드를 살펴봤는데, 문제가 워낙에 간단해서 hack을 하기가 힘들었다.
실제로, "먼저 n번 나누고 그 후에 m번 뺀 값"과 "먼저 m번 뺀 값" 중 하나만 0 이하이면 정답이라는 코드도 pass하게 되니..
https://codeforces.com/contest/1337/problem/C
Problem - C - Codeforces
codeforces.com
C. Linova and Kingdom
위 결과에서 보면 알겠지만, 대회 시간 안에 못풀었다.. ㅠㅠ
풀만했던 문제였는데 트리를 다루는게 아직 미숙해서 못푼 것 같다. 앞으로 좀 더 연습해야겠다
아무튼 풀이를 해 보도록 하겠다. (대회 끝나고 바로 다음날 일어나서 풀었다)
간단하게만 문제 설명을 해 보자면,
n개의 도시와 n-1개의 도로가 주어지고, 모든 "산업 도시"에서 수도로 사람이 올 때, 각각의 사람이 지나가는 "관광 도시"의 개수의 합의 최대값을 구해야 한다.
이 때, 산업 도시는 k개이고 나머지 모든 도시 (즉, n-k개의 도시)는 관광 도시이다.
사실 풀이는 설명만 들어보면 무척 간단하다.
일단, 1번 도시가 최종 목적지이므로 1번 노드가 루트인 트리를 만들어 준다.

일단 처음엔 간단하게, 단 하나의 산업 도시만을 고른다고 생각해 보자.
그럴 경우, 어떤 도시를 산업 도시로 골라야 할까?
그렇다. 1번 도시로 가는 길이 가장 긴 도시를 고르면 된다.
즉, 부모 노드의 개수가 가장 많은 노드들을 고르면 된다는 뜻이다.
위 예시에서는, 5, 6, 7중 하나만 고르면 될 것이다.
그리고 그렇게 산업 도시를 3개까지 고르면 5, 6, 7을 고르면 될 것이다.
그러나 4번째 산업 도시를 고를 때, 고려해야 하는 것이 하나 더 있다는 것을 알게 된다.
만약 3번 도시를 고르게 되면, 이미 골랐던 5번, 6번 도시에서 1번 도시로 가는 데 만나는 관광 도시의 개수가 하나 줄어들어 버리기 때문이다.
그리고, 어떤 노드를 고르게 되면 최대로 얻을 수 있는 점수는 해당 노드의 자식 수 만큼 줄어들게 된다.
(즉, 3번 노드를 고르게 되면 자식 노드의 개수인 2만큼 최대 점수가 줄어들게 된다.)
반면에 2번 도시를 산업 도시로 고르게 되면, 2번 노드는 자식 노드가 없으므로, 가장 최적의 상태가 완성된다.
또한, 어떤 노드의 자식 노드가 산업 도시가 아니라면, 해당 노드를 고르는 대신 무조건 자식 노드를 골라야 최적의 점수를 얻을 수 있다.
(조금 더 쉽게 말하면, 우리는 무조건 산업 도시를 리프 노드 근처부터 시작해서 천천히 루트 노드에 가까운 쪽으로 골라야 한다는 것이다.)
이는 자명한데, 만약 어떤 산업 도시의 자식 노드가 관광 도시라면, 해당 도시의 자식 노드를 산업 노드로 만들면 1점 더 높은 점수를 얻을 수 있기 때문이다.
따라서, 우리는 그리디하게 (부모 노드 개수 - 자식 노드 개수) 가 가장 큰 도시부터 하나씩 골라가면 된다.
이제 어떻게 해야할지는 알았으니, 이를 구현하면 된다.
우선, DFS를 사용하여 각각 노드의 부모 노드 개수와 자식 노드 개수를 구한다.
그런 뒤, (부모 노드 개수 - 자식 노드 개수)를 한 배열을 내림차순으로 정렬하여 앞에서부터 k개를 더하면, 그게 정답이다.
//여기서부턴 여담임 ㅎ
사실 대회 시간에 풀 때, 여러 문제점들이 있었다.
우선, 가장 처음 생각한 풀이는 그냥 부모 노드의 개수만을 생각한 풀이였다.
사실 그래서 그냥 나한테 조금 더 익숙한 BFS 방식으로 훑으면서 부모 개수를 채웠다.
그러고 나서 봤더니, 자식 노드에도 신경을 써야한다는 사실을 그제서야 깨닫게 되었고, 뇌절이 시작되었다;;
일단 "그리디하게 짜면 안되지 않을까?" 라는 생각으로 고민을 엄청 했었다.
그리고, "우선 리프 노드를 고른 뒤 해당 노드의 모든 부모 노드를 돌면서 점수를 1씩 깎자"라는 매우 비효율적인 생각을 하게 되었고,
당연히 n<=100000인 조건 안에서는 TLE가 뜰 것이 분명했기에, 문제를 던지기에 이르렀다.
차라리 그냥 처음부터 DFS로 짰으면 더 쉽게 풀었을 것도 같은데, 아쉽다.. ㅠ
https://codeforces.com/contest/1337/problem/D
Problem - D - Codeforces
codeforces.com
D. Xenia and Colorful Gems
솔직히, 얘가 C보다 훨씬 쉬웠던 것 같다.
사실 대회 시간엔 얘를 볼 생각을 딱히 못했는데, 대회 다음날 금방 답이 나와서 허탈했다...
다음부터 뇌절오면 그냥 다음 문제로 거르는 습관을 들여야 되는건가? 싶기도 하다..
아무튼! 풀이나 하도록 하자.
우선 red, green, blue 각각의 색깔의 보석의 개수 nr, ng, nb가 주어진다.
그리고 나서, 각각의 보석의 크기가 순서대로 nr, ng, nb개씩 주어진다.
각 색의 보석을 하나씩 고른 것을 순서대로 x, y, z라고 할 때, (x-y)2 + (y-z)2 + (z-x)2의 최소값을 구하는 문제이다.
(아래에서는 편의상 그냥 위 연산을 '거리'라고 하도록 하겠다.)
일단 r, g, b 배열을 오름차순으로 정렬을 해 놓고, ans를 r[0], g[0], b[0]의 거리로 놓는다.
그 뒤 r[1], g[0], b[0]의 거리, r[0], g[1], b[0]의 거리, r[0], g[0], b[1]의 거리 중 가장 작은 놈을 찾고, ans를 ans와 해당 값중 작은 값으로 바꿔주고, 가장 작았던 색의 index값을 1 올려서 위를 반복한다.
즉, 가장 거리가 작은 경우를 그리디하게 하나씩 골라주면서 진행하는 것이다.
말이 좀 어려운데, 그냥 대충 예시를 하나 들어서 설명을 하는게 나을 것 같다.
입력은 input case 1의 예시와 동일한,
2 2 3
7 8
6 3
3 1 4
로 하도록 하겠다.
우선 각각을 오름차순 정렬을 해 준다.
r : 7 8
g : 3 6
b : 1 3 4
그 뒤, ans = (7-3)^2 + (3-1)^2 + (1-7)^2 = 16 + 4 + 36 = 56으로 설정해 두자.
r[1], g[0], b[0] : (8-3)^2 + (3-1)^2 + (1-8)^2 = 25 + 4 + 49 = 78
r[0], g[1], b[0] : (7-6)^2 + (6-1)^2 + (1-7)^2 = 1 + 25 + 36 = 62
r[0], g[0], b[1] : (7-3)^2 + (3-3)^2 + (3-7)^2 = 16 + 0 + 16 = 32
그러므로, ans = min(ans, 32) = 32가 되고, b의 index를 1 올려준다.
다음 단계로 넘어가 보면,
r[1], g[0], b[1] : ...
r[0], g[1], b[1] : ...
r[0], g[0], b[2] : ...
이런 식으로 계속 진행하다 보면, 결국 nr+ng+nb번 반복 후에는 끝나게 된다.
그리고, 그렇게 나온 ans의 값이 최적의 해가 된다.
그런데, 어째서 이렇게 하면 정답이 도출될까? 저 알고리즘의 반례가 없을까?
오랜만에 그림판을 켜서 그림을 그려서 설명해 보도록 하겠다.

보석의 크기를 위치로 변환해서 그린 수직선이다.
위 그림을 보면 어느 정도 직관적으로 이해가 되지 않는가?
약간의 부연설명을 해 보도록 하겠다.
우리의 목적은, 저 중에서 각각의 색의 점 하나씩을 골라 가장 거리가 가까운 조합을 찾아야 하는 것이다.
알고리즘을 진행시키다 보면, 조금씩 더 점들이 밀집하게 된다.
그리고 임계점을 넘어가게 되면, 즉 더 이상 현재까지 구한 최적해보다 최적의 값을 찾을 수 없다면, ans값은 다시 조금 커진다.
그리고 나서 다시 ans를 최적에 맞게 줄이고, 어느 순간 또 커지고 ... 를 반복하게 된다는 것이다.
따라서, 위 방식으로 그리디하게 수행해 나가면, 최적해를 찾을 수 있게 된다.
하지만 직관을 도저히 믿을 수 없다면, 조금 엄밀하게 증명을 해 보도록 하겠다.
최적해가 위 알고리즘을 통해 나오지 않기 위해서는, 아래 두 조건을 만족하는 r,g,b가 존재해야 한다.
1) b[x],g[y+1],r[z]의 거리가 b[x],g[y],r[z]의 거리, b[x+1],g[y],r[z]의 거리, b[x], g[y], r[z+1]의 거리보다 더 작다.
2) b[x+1], g[y], r[z+1]의 거리가 b[x+1], g[y+1], r[z+1]의 거리보다 작다. (즉, g가 더 작은 값에서 더 최적의 값이 존재한다.)
이런 경우가 존재한다면, 그리디하게 선택했을 경우 최적해를 보장할 수 없다.
하지만, 이런 경우가 과연 존재할까?
2)번 조건이 만족하기 위해선, 1)에 의하여 b[x+1], g[y], r[z+1]의 거리는 무조건 b[x+1],g[y],r[z]의 거리보다 작아야 한다.
(b[x+1], g[y], r[z+1]의 거리 < b[x],g[y+1],r[z]의 거리 < b[x+1],g[y],r[z]의 거리)
그리고, r[z+1]은 r[z]보다 무조건 크기 때문에, r[z]는 b[x], g[y], r[z] 중 가장 큰 수는 아니어야만 한다.
또한, b[x+1], g[y], r[z+1]의 거리는 b[x], g[y], r[z+1]의 거리보다도 작아야 한다.
마찬가지로, b[x+1]은 b[x]보다 무조건 크기 때문에, b[x]는 b[x], g[y], r[z]중 가장 큰 수는 아니어야 한다.
따라서, g[y]가 b[x], g[y], r[z] 중 가장 큰 수가 되어야 한다.
그런데, 이는 1) 조건인 "b[x],g[y+1],r[z]의 거리가 b[x],g[y],r[z]의 거리보다 작아야 한다"에 위배된다.
따라서, 위 조건을 만족하는 r,g,b의 값은 존재하지 않고, 따라서 최적해는 위 알고리즘을 통해 항상 구할 수 있다.
사실 이걸 이렇게까지 엄밀하게 증명하고 풀었던 것은 아니라, 증명하는데 꽤 애먹은 것 같다 ㅎㅎ;
이렇게 했는데도 아직 좀 꺼림칙하다면, 에디토리얼의 풀이를 보기를 권한다.
사실 본질적으로 동일한 풀이이긴 하지만, 이해하기는 더 도움이 될 것이다.
이렇게 Codeforces Round #635 (Div. 2)의 A~D풀이를 끝내도록 하겠다.
E,F는 언젠가 실력이 되면 그때나 풀어보도록 하고 ㅎㅎ...
다음 Div3에서 꼭 블루 갔으면 좋겠다. 위 C 문제 덕에 DFS, 트리 공부도 더 할 수 있게 되기도 했고 말이다.
'PS > Codeforces' 카테고리의 다른 글
| Codeforces Round #636 (Div. 3) 문제 풀이 (A~D) (2) | 2020.04.22 |
|---|---|
| Codeforces Round #634 (Div. 3) 푼 문제들 풀이 (A~D) (0) | 2020.04.15 |
| Codeforces Round #633 (Div. 2) 푼 문제들 풀이 (A~C) (0) | 2020.04.13 |
Codeforces Round #634 (Div. 3) 푼 문제들 풀이 (A~D)
E 풀수 있을것 같은데? 아니 안되나? 으악!!
하고 터져버린 contest...
어차피 D까지는 거의 다 풀었겠지만 그래도 후기 쓰는 느낌으로 푼 문제들의 풀이를 해보도록 하자.

https://codeforces.com/contest/1335/problem/A
Problem - A - Codeforces
codeforces.com
A. Candies and Two Sisters
문제가 무척이나 간단하고 쉬웠다.
숫자 n이 주어지고, 해당 n을 a>b (a>0, b>0, a+b=n)을 만족시키게 나누어 주는 경우의 수를 물어보는 문제였다.
경우를 두 가지로 나누어 보자.
1. n%2==0, 즉 n이 짝수일 때,
경우의 수는 정확히 n/2 - 1번이 나오게 된다. 가령 n이 6일 때, (5,1), (4,2)로 두 가지 경우가 존재한다.
2. n%2==0, 즉 n이 홀수일 때
경우의 수는 정확히 n/2번 나오게 된다. 가령 n이 7일 때, (6,1), (5,2), (4,3)으로 세 가지 경우가 존재한다.
이를 식 하나로 정리하면,
ans = (n-1)/2 로 정리할 수 있다.
그래서 그냥 n을 입력 받아서 (n-1)/2를 출력하면 되는 문제였다.
https://codeforces.com/contest/1335/problem/B
Problem - B - Codeforces
codeforces.com
B. Construct the String
n, a, b를 입력받아서 크기 a의 substring에서 정확히 b개의 distinct한 글자가 들어가게 string을 만들어야 하는 문제였다.
풀이 방법이 여러 가지가 나올 수 있는 문제였다.
일단 내가 처음 생각해서 제출한 방법은 다음과 같았다.
1. 우선 크기 a-b+1만큼 모두 'a'로 채운다.
2. 그 뒤, b-1만큼 b,c,d,...으로 채운다.
3. 반복한다.
라는 생각으로 문제를 풀었다.
그런데 내 친구들이 푼걸 보니, 그냥 더 간단하게 처음부터 끝까지 b번만큼 abcdabcd...으로 반복하면 되더라...
어떻게 풀었건, 이런 방법들로 풀면 OK일것같다.
https://codeforces.com/contest/1335/problem/C
Problem - C - Codeforces
codeforces.com
C. Two Teams Composing
한 쪽 팀에는 같은 능력치를 보유한 사람만, 다른 한 쪽 팀에는 서로 다른 능력치를 보유한 사람만으로 채울 때 최대 몇명까지 팀을 채울 수 있는지를 물어보는 문제였다. (양쪽 팀의 사람 수가 같다는 전제 하에)
어떻게 나눠야 최대 인원으로 팀을 나눌 수 있을지 생각해보자.
우선, 모두가 동일한 능력치를 가진 팀의 최대 인원은, 입력받은 숫자 중에 가장 자주 나온 숫자의 개수와 동일하다.
즉, 1 2 3 4 4 4 가 입력으로 주어지면 동일한 능력치 팀은 최대 3명이다.
모두가 다른 능력치를 가진 팀의 최대 인원은 반대로, 입력치의 서로 다른 숫자의 개수가 될 것이다.
즉, 1 2 3 4 4 4 가 입력으로 주어지면 서로 다른 능력치 팀은 최대 4명이다.
여기서 주의해야 할 점은, "서로 다른 숫자"에는 "가장 많은 개수의 숫자"도 포함된다는 것이다.
자, 이제 서로 다른 숫자의 개수와 가장 자주 나온 숫자의 개수를 구한 뒤 어떻게 해야 할지 경우를 나눠보자.
1. 서로 다른 숫자의 개수 > 가장 많이 나온 숫자의 개수인 경우
ex) 1 2 3 4 5 5 5
이 경우, 최대로 많이 나눠도 가장 많이 나온 숫자의 개수 (5 5 5로 3개)까지만 팀이 나눠지므로, 가장 많이 나온 숫자의 개수가 정답이 된다.
2. 서로 다른 숫자의 개수 < 가장 많이 나온 숫자의 개수
ex) 1 2 3 3 3 3
이 경우, (1, 2, 3), (3, 3, 3)으로 나눌 수 있으니, 서로 다른 숫자의 개수가 정답이 된다.
3. 서로 다른 숫자의 개수 == 가장 많이 나온 숫자의 개수인 경우
ex) 1 2 3 3 3
이 경우, (1, 2), (3, 3)으로 최대 2명까지만 나눌 수 있으니, 서로 다른 숫자의 개수 - 1 이 정답이 된다.
이렇게 경우의 수를 세 가지로 나누면 손쉽게 정답을 구할 수 있다.
참고로, "서로 다른 숫자의 개수"에 "가장 많이 나온 숫자"를 포함하지 않으면 문제를 풀기 무척 까다로워 진다.
가령, 입력이 1,2,3,3,3,3으로 주어진 경우, 분명 서로 다른 숫자와 가장 많이 나온 숫자의 개수는 각가 2,4이지만 정답은 3이 되야 하기 때문이다.
https://codeforces.com/contest/1335/problem/D
Problem - D - Codeforces
codeforces.com
D. Anti-Sudoku
솔직히 C보다 쉬운것 같은데;;
완성된 스도쿠를 최대 9개의 숫자를 바꿔서 각 줄과 블럭에 두 개 이상의 숫자가 겹치게 해야 한다.

일단, 각 블럭과 각 줄에 딱 하나씩만 죄다 숫자를 바꿔보자.

일단 나는, 저렇게 동그라미 친 부분의 숫자를 바꾸도록 했다.
해당 a[i][j]를 a[i][j]%9+1로 바꾸면 무조건 다른 숫자로 바뀌게 된다.
또한, 이렇게 하면 모든 줄, 블럭에 각각 숫자가 하나씩 바뀌므로 무조건 안티-스도쿠가 완성된다.
근데 다른 사람 코드 보다가 알았는데, 이렇게 할 필요도 없이 그냥 모든 숫자 '1'을 '2'로 바꾸면 완벽하게 해결되더라;
똑똑한 사람은 참 많은 것 같다.
딱 이렇게 40분컷 내고 장렬히 전사하고 말았다.
사실 E1을 풀 작정으로 1시간 20분동안 달렸으면 풀 수 있을만 했는데,
E2를 풀 작정으로 생각을 해버려서 그만...
E1 풀었으면 블루 갈만도 했는데 ㅠㅠ
사실 끝나고 나서 다른 문제들도 조금 풀긴 했는데, 에디토리얼 보고 푼거라 풀이로 울리긴 좀 그렇다 ㅎ;
'PS > Codeforces' 카테고리의 다른 글
| Codeforces Round #636 (Div. 3) 문제 풀이 (A~D) (2) | 2020.04.22 |
|---|---|
| Codeforces Round #635 (Div. 2) 후기 및 풀이 (A~D) (0) | 2020.04.18 |
| Codeforces Round #633 (Div. 2) 푼 문제들 풀이 (A~C) (0) | 2020.04.13 |
Codeforces Round #633 (Div. 2) 푼 문제들 풀이 (A~C)
https://codeforces.com/contest/1339
Dashboard - Codeforces Round #633 (Div. 2) - Codeforces
codeforces.com

이번 코드포스는 A 문제 이해를 못하겠어서 거르고 B,C풀고 A를 풀었다.
그 대신 B,C를 1시간만에 풀고 A도 1시간 언저리에 해결했는데 D,E를 건드리지를 못하겠어서 그냥 gg친 대회 ㅠㅠ
c++ 트리 공부 언젠가 꼭 해야겠다. 트리 문제 나올때마다 풀지를 못하니;;
https://codeforces.com/contest/1339/problem/A
Problem - A - Codeforces
codeforces.com
A. Filling Diamonds
문제에서 주어진 공간을 다이아몬드로 채우는 경우의 수를 출력하면 되는 문제였다.
대체 왜 이걸 이해를 못한건지;;
아무튼 문제 이해했다고 치고, n=3일때 부터 생각을 해 보면...

위 도형을 다이아몬드 모양으로 채우기 위해선 어떻게 해야 할지 생각을 해 보자.
일단 위쪽 줄과 아래쪽 줄의 삼각형 갯수가 5개인 홀수이므로 적어도 한 다이아몬드는 세로로 서 있는 형태여야 한다.
그런데 한 다이아몬드가 서 있는 형태이면, 나머지 자리는 무조건 한 가지 경우로 고정되게 된다.



그리고 이러한 점은 n=4, 5, 6, ... 일때도 동일하게 적용이 된다.

따라서, 정답은 그냥 서 있을 수 있는 다이아몬드의 갯수이고, 이는 n값과 동일하다.
https://codeforces.com/contest/1339/problem/B
Problem - B - Codeforces
codeforces.com
B. Sorted Adjacent Differences
배열 하나가 주어졌을 때, 해당 배열을 |a1−a2|≤|a2−a3|≤…≤|an−1−an| 을 만족하도록 바꾸는 문제이다.
어렵게 생각하면 무척이나 어려워질 수 있는 문제이다. 특히 두 번째 input example이
4
8 1 4 2
---------
1 2 4 8
이렇게 들어오는지라 문제 풀이 방식을 생각하기 이전에 이 예제에 너무 현혹되었으면 풀기 까다로웠을 것 같다.
일단 풀이먼저 말하자면, 무척이나 간단하다.
우선, 배열을 정렬해 준다.
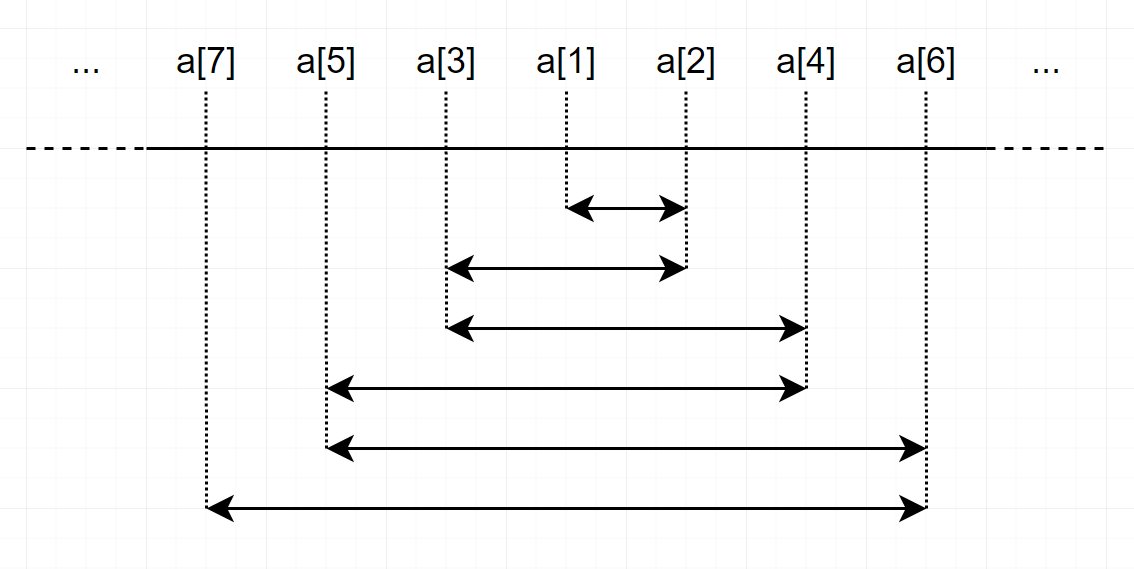
5 -2 4 8 6 5 --> -2 4 5 5 6 8
그 뒤, 가운데 원소를 출력한 뒤, (n이 짝수여도 그냥 n/2번째 원소를 출력하면 된다.) 해당 원소의 한칸 오른쪽 원소, 한칸 왼쪽 원소, 두칸 오른쪽 원소, 두칸 왼쪽 원소 ... 를 출력해 주면 된다.
위의 예시에서는, 5, 5, 4, 6, -2, 8이 되겠다.
이렇게 해 주면, 배열이 정렬되었으므로 중앙에서 멀어질수록 당연히 중앙의 원소와의 거리 (|a1−a2|)가 커지게 되고, 이를 오른쪽, 왼쪽을 반복해주면 자명하게 절댓값의 크기가 커지게 된다.
추가) 에디토리얼에 이해가 쉬운 사진이 있어 첨부한다.
https://codeforces.com/contest/1339/problem/C
Problem - C - Codeforces
codeforces.com
C. Powered Addition
다른 Div2 C번 문제보다는 쉬웠던 것 같다.
(그래서인지 푼 사람도 5000명이 넘어가고 ABC다풀어도 점수가 별로 안올랐다 ㅠㅠㅠ)
우선 문제에서 관찰할 수 있는 것들을 살펴보자면,
1) x초 동안 더할 수 있는 최대 수는 2x - 1이다. (1초 후엔 1, 2초 후엔 1+2=3, 3초 후엔 1+2+4=7...)
2) x초 동안 더할 수 있는 수는 0~2x - 1이다. 즉, x초가 지났을 때, 0~ 2x - 1 중 원하는 수만큼 더해줄 수 있다. (5=1+4, 1+2+4 등으로 표현할 수 있으므로)
3) 1),2)를 통해 알 수 있는 점으로, 만약 aₙ > aₙ₊₁ 이면, aₙ₊₁ - aₙ만큼 더하는 것이 가장 빠르게 aₙ <= aₙ₊₁를 만드는 방법 중 하나이다.
4) 3)에 의하여, non-decreasing 배열로 만들 때 가장 최적의 방법 중 하나는 aₙ > aₙ₊₁이면 aₙ₊₁ - aₙ만큼 더해주는 것이다.
따라서 정답을 구하는 알고리즘은 다음과 같다.
i=0부터 n-1까지,
if aᵢ > aᵢ₊₁ : max_t = max(max_t, aᵢ₊₁ - aᵢ);
ans = log2(max_t) + 1;
언제나 그렇지만, 이런 문제들을 풀고 나면 "엄청 쉬운 문젠데, 왜 이렇게 오래 걸렸지..?" 하는 생각이 들곤 한다.
언젠가 D,E도 풀고 풀이를 올릴 수 있는 날이 왔으면 좋겠다...
'PS > Codeforces' 카테고리의 다른 글
| Codeforces Round #636 (Div. 3) 문제 풀이 (A~D) (2) | 2020.04.22 |
|---|---|
| Codeforces Round #635 (Div. 2) 후기 및 풀이 (A~D) (0) | 2020.04.18 |
| Codeforces Round #634 (Div. 3) 푼 문제들 풀이 (A~D) (0) | 2020.04.15 |
크리스마스

인터넷에 가장 사람이 모이지 않는 날
더러운 인싸놈들!
'잡담' 카테고리의 다른 글
| 이미 어제 하나 썼던 기념) 2018 정보올림피아드 썰 - 2편 (4) | 2019.05.05 |
|---|---|
| 정보올림피아드 보고 온 기념) 2018 정보올림피아드 썰 - 1편 (1) | 2019.05.04 |
디미고 진학 관련 이야기들 - 디미고 커트라인, 디미고 면접 등

글쓰기 앞서서 세줄 요약
1. 제발 학원 말들 좀 믿지 말자.
2. 경쟁률 보고 너무 쫄지 말고, 자기 점수를 믿자.
3. 면접은 솔직하게, 말 잘 못해도 되니까 진솔하게 답하자.
-- 시작하기 앞서, 본인은 일반전형 웹플과 학생임을 알려드립니다. --
안녕하세요, 오늘은 디미고 진학 관련 이야기를 좀 해보려 합니다.
벌써 오늘부터 특별전형 원서 접수가 시작됐네요.
또, 곧 11월 15일부터는 일반전형 원서 접수가 시작됩니다.
재작년 이맘때쯤 원서 준비하던 제 모습이 새록새록 떠오르기도 하고, 곧 진짜 3학년이 된다는 생각에 조금 두렵기도 하네요.
디미고 진학을 원하는 친구들은 이미 원서 준비는 거의 다 끝났겠지요?
다들 인터넷에서 이런저런 정보들을 검색을 다 해봐서 다들 어느 정도 커트라인은 알 테고, 또 다들 학교에 대한 이런저런 것들도 다들 알 거라고 생각합니다.
그래도, 제 블로그에 자주 올라왔던 질문 기준으로 진학 관련해서 이야기를 좀 해보고자 합니다.
1. 학교 입학 커트라인은 몇 점인가요?
일단, 많은 분들께서 커트라인이 어떻게 잡히는지 궁금해하시는 것 같습니다.
그리고, 다들 검색 많이 해보셔서 알겠지만, 디미고 홈페이지 기준으로 커트라인이 130~135점이라는 다소 애매한 답변이 돌아옵니다.
그런데 사실 학교 측에서도 이런 식으로밖에 공지를 못하는 이유가 과별로, 연도별로 차이가 좀 있기 때문입니다.
저, 그러니까 17기 웹플과 일반전형 기준으로는 130점대 중후반이면 거의 다 1차는 합격했다고 보시면 됩니다.
그리고 135점만 넘어가도 사실상 모든 과에서 1차 합격은 어느 정도 안정권이라고 볼 수도 있겠습니다.
(하지만 맹신하시면 안 됩니다! 매년 들어오는 입학생들의 수준이 상이합니다!)
특별전형 같은 경우는 당연히 교과점수 커트라인은 조금 더 낮은 편입니다.
대략 120점 중후반대 점수도 어느 정도 합격했다고 합니다.
물론 특별전형 같은 경우에는 실적물들도 보기 때문에 그저 교과점수만 보고 입학권을 결정짓긴 힘듭니다.
그래도 어차피 원서접수를 할 생각이라면, 그리고 특별전형 준비를 이미 했다면 당연히 그냥 원서를 내보는 게 낫겠죠?
2. 디미고 경쟁률은 어떤가요?
이것도 위의 커트라인 관련 질문과 비슷한 맥락으로, 학교 측에서도, 그리고 저희 학생들도 경쟁률이 어떨지는 알 수가 없습니다.
게다가, 이비/디컨같은 경우는 뽑는 인원 자체가 34명인지라 연도별로 굉장히 다를 수 있습니다.
일단 학교 홈페이지에 게재되어 있는 내용으로 어느 정도 답변을 하자면,
2017년 11월 29(수) 창의인재전형 최종 경쟁률
e-비즈니스과 : 3.05 대 1
디지털콘텐츠과 : 4.3 대 1
웹프로그래밍과 : 4.68 대 1
해킹방어과 : 4.85 대 1
라고 합니다. 참고로 제가 듣기로는 저번 연도 (2019년 입학생) 같은 경우는, 디컨과가 굉장히 경쟁률이 높았다고 합니다.
다만, 경쟁률이 너무 높은 것 아닌가 하고 걱정하실 필요는 솔직히 없을 것 같습니다.
어차피 내신 높은 학생들의 수는 정해져 있는지라, 일단 어느 정도 성적 커트라인에 맞기만 하면 경쟁률에 상관없이 합격하니까요 ㅎㅎ
(예전에 학원 다닐 때 선생님께서 해주셨던 말씀이 기억나네요. 경쟁률 낮은 학교에 지원하고 싶으면 서울대 의예과 넣으라고 하시던...ㅋㅋㅋ)
아무튼, 너무 경쟁률에 쫄지 않으셨으면 좋겠습니다.
3. 디미고 면접 준비는 어떻게 해야 되나요?
아마 이번 글 중에서 가장 중요한 질문이 아닐까 싶습니다.
우선 본격적으로 이야기하기 앞서, "학원 글은 그냥 다 무시하라"라고 조언드리고 싶습니다.
(조금 더 자세한 이야기는 제 블로그 글 https://cding.tistory.com/25 를 참고하시면 좋겠습니다.)
정말 입학생 및 선생님 기준에서 봤을 때, 정말 말도 안 되는 소리만 하고 있는 것들이 대부분입니다.
그리고 사실, 입학생 중에서 면접 학원을 다닌 학생은 정말 극소수인 데다가, 다닌 학생들 마저도 별로 쓸데가 없었다고 하는 실정입니다.
정말로, 학원 가서 헛돈 쓸 바에 그냥 치킨이나 사 먹고 든든하게 면접 보러 가는 게 낫습니다.
(진짜 면접 보시면 그때서야 "아 진짜구나" 하실 겁니다.)
각설하고, 그래서 진짜 디미고 면접 준비는 어떻게 해야 될까요?
우선, 디미고 홈페이지의 "자주 묻는 질문"을 확인해 봅시다.
"
IT우수인재특별전형(특별전형)의 면접은 본인이 제출한 실적에 대한 검증, 학교(단체)생활에 대한 적응, 생활기록부 내용을 바탕으로 한 질문이 이뤄집니다.
창의인재전형(일반전형)의 면접은 중학교 정보교과 또는 워드프로레서 자격증 취득시 배우는 컴퓨터 상식 또는 실생활(뉴스 등)에서 접할 수 있는 수준의 IT상식에 대한 질문과 학교(단체)생활에 대한 적응, 생활기록부 내용을 바탕으로 한 질문이 이뤄집니다.
본교에서 가장 중점으로 다루는 부분은 대인관계와 인성에 대한 부분입니다.
이 부분은 단기간 학원에서 만들어지는 것이 아니라, 지금까지 성장하면서 만들어지는 것을 명심하세요.
"
그리고 놀랍게도, 정말 저 말들이 모두 사실입니다.
예, 저도 입학하기 전에 저거 보고 나서 많이 답답했습니다. 많이 애매모호하죠?
하지만 저것을 그냥 곧이곧대로 믿으시면 되겠습니다. 왜인지는 지금부터 차차 말해보도록 하겠습니다.
일단 일반전형 기준으로 먼저 설명드리겠습니다. (제가 일반전형 입학생이라 ㅎㅎ)
우선, 면접실(?)에 다른 학생 두 명과 함께 들어가시면, 선생님께서 세 분 앉아계실 겁니다.
그리고는 이제 학생들에게 질문을 시작하시겠지요.
자, 그리고 당신이 이 면접을 보는 선생님이라고 생각해 보세요.
그런데 이 면접을 보시는 선생님들은 사실 면접실마다 다 다릅니다. (당연히도 말이죠.)
그런데 당연하게도 면접마다 점수를 어느 정도 통일할 필요가 있을 겁니다.
거기다가 선생님들이 학생들을 유추할 수 있는 점은 (자기소개서가 없는 관계로) 생활기록부밖에 없습니다.
그러면 과연 일반 전형의 경우 학생 관련해서는 어떤 질문을 하게 될까요?
예, 그냥 생기부에 있는 내용 질문밖에 할 수 없을 겁니다. 이 학생이 정말 중학교 때 잘 살았는지 일단 물어보는 게 중요하니까요.
또 어떤 질문을 하실 수 있을까요?
선생님들은 학생들이 우리 학교, 즉 디미고에 입학해서 학생이 잘해 나갈 수 있는지 알아보셔야겠지요?
그러면 당연하게도 인성 관련 및 학교 생활에 잘 적응하는지 여부를 질문할 수밖에 없을 겁니다.
그리고 마지막으로 IT 관련 질문을 하게 될 겁니다.
그런데 사실 면접실마다 조금씩 다르긴 하지만, 면접실에 아예 정보 관련 선생님이 없는 경우도 있습니다.
(저 같은 경우에 그랬습니다. 심지어 문과 선생님들밖에 없으셨습니다 ㅎㅎ..)
그런데 아까 언급했다시피, 면접 점수를 어느 정도 통일할 필요가 있습니다. (형평성에 맞게 말이죠.)
그러면 엄청 어려운 질문이 과연 나올 수 있을까요?
가령, "인공지능에서 Gradient Descent가 무엇인지 수학적 관점에서 논하고, 더욱 좋은 성능의 인공지능을 만들기 위해 Vanilla Gradient Descent를 어떻게 바꿀 수 있는지를 논하시오." 같은 질문이... 들어올까요?
조금 과장하긴 했지만 저렇게 어려운 질문이 들어올 리가 만무합니다.
(본인이 인공지능에 대해 엄청 자신 있다는 듯이 말한 게 아니라면 말이죠 ㅎㅎ;)
그러니까, IT질문은 정말 위에서 언급한 것과 같이 컴퓨터 상식 선에서 나옵니다.
그렇다고 이걸 또 따로 공부할 것도 아닌 게 정말 질문하시는 내용이 막 어떻게 공부를 할 수 있는 게 아니라, 진짜 그냥 본인이 컴퓨터에 관심만 있었어도 다 답할 수 있는 내용입니다.
그럼 이제 또 이런 질문이 들어오겠죠.
"아니 그래서 대충 어떤 질문이 나오는데요?" 내지는, "님은 질문이 뭐였는데요??" 같은 질문 말이죠.
그러면 이에 대한 답변은 하나밖에 없을 것 같습니다.
"걱정하지 마시고, 그냥 편한 마음으로 오세요. 어차피 뭘 공부하든 딱히 의미 없을 겁니다."
그냥 긴장만 하지 마시고 질문하는 말씀에 답만 잘하세요.
어차피 선생님이 질문하시는 IT질문도 답하지 못하는 수준이면 컴퓨터에 관심이 별로 없는 거라 입학해서도 잘 못 지낼 확률이 높습니다.
그리고 추가적으로, 그거 답 제대로 못해도 사실 합격하는 경우도 종종 있습니다.
어차피 선생님들께서 정량적인 점수를 매기면서 막 질문 1번은 5점, 2번은 3점... 이런 식으로 면접을 보는 게 아니라서 말이죠.
그러면 일반전형 면접 준비는 어떻게 해야 될까요?
간단합니다. 우선 자신의 생기부를 그냥 한번 쭉 읽어보세요. 그리고, 자신이 어떻게 살아왔나를 되짚어 보세요.
거기서 자신이 무슨 생각을 했는지 아니면 지금 어떤 생각을 가지고 있는지 곰곰이 생각해보세요.
그리고 가장 중요한 것은 자신이 생각하는 바를, 그리고 디미고에 입학해서 잘할 자신이 있는지를 점검하시고 그것을 자신감 있게 잘 말하는 연습을 하세요.
솔직히 선생님들이 질문하는 내용을 죄다 매끄럽고 유연하게 받아치기를 기대하는 것이 아닙니다. 그저 학생이 이 학교에 와서 잘할 수 있을지를 보는 겁니다.
그러니까 그냥 말을 엄청 매끄럽게 하거나 말을 엄청 아름답게 하려고 하지 마시고 그냥 진심이 드러나게 말할 수 있는 능력만 기르시면 됩니다.
참고로 제 이야기를 잠깐만 하자면, 저도 재작년 이맘때쯤에 면접 준비랍시고 인터넷에서 컴퓨터 상식도 막 검색해 보고 디미고 면접 질문이 뭐가 나오는지도 검색을 많이 해봤습니다.
그리고 면접을 보고 난 뒤에 정말 다 부질없다는 것을 깨달았습니다.
그냥 진실된 마음으로 면접에 임하시면 될 것 같습니다.
그리고 특별전형 같은 경우, 저는 면접을 안 봐서 잘 모르겠지만, 어차피 기본적인 내용은 다 비슷합니다.
다만 특별전형은 조금 더 생각해야 하는 부분이 있겠죠. 바로 자신의 실적물과 자소서입니다.
그런데 특별전형 면접 준비는 더 간단합니다.
자신이 직접 만든 프로그램이라면 웬만하면 기본적인 알고리즘이나 구동 방식은 기억하겠죠?
그냥 자신이 만든 프로그램에 대해 설명만 잘하시고 물어보는 실적물 관련 질문에 답만 잘하시면 됩니다.
자소서 같은 경우는, 진실되게 쓰셨다면 웬만하면 또 괜찮게 보실 수 있을 겁니다.
생활기록부 관련 질문이랑 비슷하게 그냥 진실되게만 말하세요.
근데 이렇게 보니까 특별전형이 더 쉬운 것 같기도 하고...
특별전형도 일반전형과 마찬가지로 그냥 진실되게 자신의 생각을 잘 말하기만 하시면 됩니다.
거기다 추가적으로 자신이 뭘 구현했는지, 어떻게 구현했는지 잘 생각하고 가시면 될 듯합니다.
거짓말하면 다 들키게 되어 있으니까 진실되게 말하세요.
참고로 당연하겠지만 사소한 거짓말이라도 면접 때 했다가 걸리면 얄짤없이 잘리겠죠? (그 학생의 신빙성이 바닥을 치게 되는 거니까요.)
가장 중요한 것은 진실되게 말하는 것이라는 것을 알아두셨으면 합니다.
이쯤까지 읽으셨으면, 이런 생각들을 하실 수 있을 것 같습니다.
"내가 지금까지 봤던 진학 글이랑은 조금 다르네..? 뭐지?"
예, 지금까지 봤던 글들은 아마 대부분 학원에서 작성한 홍보 글이라 그런 겁니다.
네이버에 검색해 보니 막 "킬링 멘트를 준비해라", "질문을 알고 가는 것이 중요하다" 등등 말도 안 되는 소리 (착한 말 ㅎㅎ)을 하는데 그거 호구 잡기 하고 있는 겁니다.
뭐 어차피 갈 사람들은 이미 갔을 테지만...
면접 보고 나오시면 아마 알게 될 겁니다.
혹시라도 모르니까 그래도 학원을 가는 게 낫지 않겠냐고요?
아까도 말씀드렸지만 그거 갈 바에 치킨 한 마리 맛있게 뜯고 배 든든하고 자신 있게 면접 보러 가시는 게 낫습니다.
정 걱정되신다면 화장실 거울 앞에서 한 번 연습해 보시는 것도 괜찮겠고요.
그리고 예상 질문에 대해서 많이들 물어보실 것 같습니다.
그런데 여러 학원 홍보글에서 말하다시피 예상 질문이 엄청나게 중요하진 않습니다.
왜냐고요? 어차피 예상 질문 아나 모르나 제가 위에서 언급했던 것처럼 그냥 진솔하게만 자소서를 쓰고 생기부 작성을 했다면 다 답할 수 있을 거니까요.
면접 쪽에만 너무 힘을 들여 쓴 감이 없지 않아 있는데, 이걸 가장 궁금해하실 것도 같고 학원에 농간에 놀아나지 말라는 의미에서 좀 길게 써봤습니다.
다시 한번 강조합니다만 "진실되고 솔직하게, 있는 대로 답하세요". 그것이 가장 좋은 면접 준비 방법입니다.
그리고 너무 두려워하거나 무서워하지 마세요. 생각보다 많이 쉬울 거고, 잘 해낼 수 있을 겁니다.
여담이지만, 사실 친구들한테 물어봐도 열에 여덟은 사실 면접 준비 안 하고 왔습니다.
저도 이것저것 많이 검색해 본 것은 사실이지만 그렇다고 면접 준비를 막 예상 질문 생각하고 그러진 않았거든요.
(솔직히 그때 검색해서 얻은 내용들 하등 다 쓸데없었습니다. 이 글을 쓰는 것도 사실 그것 때문입니다.)
그 외, 답변이 힘들거나 간단한 질문들
Q. 제 점수가 ~~~ 인데, 입학 가능할까요?
A. 135점 이상이면 입학 가능이고, 그 아래면 아슬아슬할 수 있습니다.
Q. 제가 특별 전형 실적물을 ~~~ 하게 만들었는데, 몇 점 정도 나올까요?
A. 그건 담당 선생님이 봐도 답변 못하실 겁니다. 자신이 봤을 때 괜찮은 것 같다면 그냥 자신감을 가지세요!
Q. 그래서 면접 질문이 뭔가요?
A. 하늘이 무너져도 안 알려줍니다. 애초에 알려줄 필요도 없습니다.
Q. 디미고에 괴물들이 많이 온다는데... 정말 무서워요 ㅠㅠ 제 이 미천한 실적물로 입학할 수 있을까요?
A. 사실 이미 원서 다 썼겠지만 답해드리자면, 사실 괴물들 별로 없습니다 ㅎㅎ; 게다가 어차피 학생들에게 그런 괴물 같은 실적물을 바라는 게 아니기 때문에 그냥 중학생 기준에서 조금만 잘하면 다 점수는 괜찮게 주실 겁니다.
모쪼록 입학 지망생 분들께 도움이 되었으면 좋겠고, 그 외 진학 및 학교 관련 질문들이 있으면 댓글로 남겨주시면 되겠습니다.
늦어도 2일 안에는 답장드리겠습니다. ㅎㅎ
그럼, 다들 화이팅하시길 바랍니다!
'일상 > 디미고' 카테고리의 다른 글
| 디미고, 3년을 돌아보며 - 디미고 입학과 새내기 시절 (51) | 2021.01.31 |
|---|---|
| 디미고, 3년을 돌아보며 - Intro (4) | 2021.01.31 |
| 디미고 입학설명회 후기 (0) | 2019.10.20 |
| 디미고 시험기간 - 최대 헬게이트, 고2 1학기 기말 (11) | 2019.06.29 |
| 디미고 일상? - 노트북 편 (8) | 2019.04.24 |
강화학습 강의 (CS234) 8강 - Policy Gradient

- 본 포스팅은 CS234 8강의 내용을 정리합니다.
참고로, 8~10강까지의 내용은 비슷한 내용을 주제로 연강을 하게 됩니다.

이번 시간에는 Policy Search, Policy Gradient에 대해 배워보도록 하겠다.

저번 시간에, 우리는 파라미터 θ에 대해 (w에 대해) value값 및 action-value (Q)을 찾는 방법을 배웠다.
그래서, 그렇게 생성된 value값을 사용하여 직접 policy를 만드는 방식을 사용했다.
(ε-greedy 방식을 사용해서 최대의 value값을 가지는, 또는 랜덤한 policy를 찾는 방법을 사용했던 것을 생각해보자.)
그런데 이번 시간에는, 우리는 policy πθ를 직접 파라미터로 사용할 것이다.
즉, value 값에서 policy를 찾는 것이 아니라, θ (또는 w)의 값을 토대로 policy를 직접 얻을 것이다.
또, 지금까지와 비슷하게 model에 대한 접근 없이, model-free한 RL을 진행하게 될 것이다.

들어가기에 앞서, 사실 reinforcement learning도 policy를 기반으로 할지, value를 기반으로 할지 등에서 조금씩 나뉜다.
Value-Based라고 한다면, ε-greedy와 같은 형식으로 policy를 도출하게 되고,
Policy-Based라면 Value function 없이 직접 policy를 배우게 된다.
Actor-Critic은 그 사이에 있는 놈들인데, 나중에 다루게 될 것이니 일단 넘기도록 하자.

Policy-Based RL이 가지는 장점과 단점들에 대해 살펴보자.
우선, 장점들을 먼저 살펴보자면, Parametrization을 통해 policy를 나타내는 것이 더욱 효율적일 때가 있다. (사실 상황에 따라 다르긴 하다.)
또, high-dimensional / continuous action space의 경우 action-value pair을 사용하는 것 보다 훨씩 효율적이며,
stochastic policy, 즉 무작위적 policy를 가질 수 있게 된다.
value function을 바탕으로 policy를 짜면, 보통 최대의 value값을 갖는 policy를 선택하는데, 이는 stochastic한 policy를 얻지 못하게 막는다.
그런데 왜 stochastic policy가 필요한지는 후술하도록 하겠다.
단점들도 있는데, 우선 대부분의 policy-based RL은 global optima에 수렴하지 않고, local optima에 수렴하는 경우가 많다.
또, 일반적으로 policy를 계산하는 것은 sample inefficient 하다. (sample의 갯수가 많아야 한다는 뜻)

그런데, 아까 전에 stochastic policy를 학습할 수 있는 것이 장점이라고 했는데, 왜 stochastic policy가 필요할까?
가장 간단한 예시로, 가위바위보를 하는 Agent를 만든다고 생각해보도록 하자.
만약 모든 policy가 deterministic 하다면 어떨까?
예를 들어, 처음에는 바위를 내고, 전판에 상대가 보를 냈으면 다음판엔 가위를 내고, ... 하는 식으로 학습되었다고 해보자.
그렇게 학습을 끝낸 후 사람과 가위바위보를 시키면 잘 해낼 수 있을까?
가위바위보를 한판만 하는 거면 모르겠지만, 여러 판 하다 보면 결국 사람이 이게 어떤 메커니즘으로 흘러가는지 알게 되고, 그냥 처음에 보를 내고, 그 다음에 주먹을 내고, ... 하는 식으로 간파가 가능하다.
즉, 가장 최적의 policy는 사실, 가위바위보 셋 중 하나를 랜덤으로 내는 것이다.
아직 잘 와닿지 않는다면, 다음 예시를 통해 조금 더 와닿게 해 보겠다.

위와 같은 grid world가 있다고 하자.
당연히 저기 있는 돈꾸러미가 goal이고, 해골 무늬에 들어가면 죽게 된다.
(해골이나 돈꾸러미에서 시작하는 일은 없다고 가정한다.)
Agent는 동서남북 네 방향만을 관찰할 수 있어서, 동서남북의 칸에 벽이 있나 없나만을 알 수 있다.
또, 자신이 하얀 블럭 위에 있는지 회색 블럭 위에 있는지도 알 수 없다.
자, 이에 따라 돈꾸러미에 들어가는 policy를 짠다면 어떻게 될까?

우선, 하얀색의 블럭 세 개에서의 policy는 자명하게 구할 수 있다.
왼쪽 흰 블럭의 policy를 생각하면 : 왼쪽과 위쪽에 블럭이 있고, 아래쪽에 블럭이 없으면 오른쪽으로 간다! 가 될 것이고,
오른쪽 흰 블럭의 policy를 생각하면 : 오른쪽과 위쪽에 블럭이 있고, 아래쪽에 블럭이 없으면 왼쪽으로 간다! 가 될 것이다.
또, 가운데 흰 블럭은 : 위에만 블럭이 있으니, 아래로 간다! 가 policy가 될 것이다.
이렇게 하면 흰 블럭 위에 있을 때는 최적의 policy가 된다.
문제는 회색 블럭에 있을 때이다.
저 두 블럭에서는 사실 들어오는 feature가 동일하다. "아래, 위에 블럭이 있고, 왼쪽, 오른쪽은 비어 있다" 라는 feature이다.
하지만 저 feature에 대해 어떤 한 가지의 policy를 정할 수 있을까?
만약 "왼쪽으로 간다"라는 policy를 정한다면, 왼쪽 위 흰 블럭 또는 회색 블럭에서 시작하는 경우에는, 영원히 goal에 도달하지 못하게 될 것이다.
반대로 "오른쪽으로 간다"라는 policy를 정한다면, 오른쪽 위 흰 블럭 또는 회색 블럭에서 시작하는 경우에 goal에 영원히 도달하지 못한다.
하지만 Value-based learning같은 경우에는 거의 greedy한 방식으로, deterministic한 policy를 정하게 된다.
이렇게 deterministic한 policy를 정하는 경우, 이처럼 갇히게 되는 경우가 발생하여 좋지 못한 policy가 되고 만다.

그렇다면, 위의 회색 블럭의 policy를 "50% 확률로 왼쪽으로, 50%확률로 오른쪽으로 간다" 라고 잡으면 어떻게 될까?
어디서 시작하더라도, 충분한 시간 뒤에는 결국 goal에 도착하는 이상적인 policy가 완성되게 된다.
이것이 바로 stochastic policy가 필요한 이유이고, 이것이 바로 Value-Based RL이 아닌 Policy-Based RL이 필요한 이유이다.
Value-Based RL같은 경우 위와 같은 Stochastic Policy를 학습하지 못하지만,
Policy-Based RL은 저런 optimal stochastic policy도 할습할 수 있기 때문이다.

이제 본격적으로 policy based RL을 시작해 보도록 하자.
우리의 목표는 최고의 파라미터 θ를 찾아서 parametrized πθ를 찾는 것이다.
그런데, πθ가 얼마나 좋은지 어떻게 알 수 있을까?
우선 episodic environments (H steps 또는 terminal까지)의 경우, J(θ)를 start state의 Value값으로 둘 수 있다.
그리고 continuing environments 같은 경우, πθ의 평균값을 사용하거나, time-step당 reward의 평균을 사용한다.
오늘은 대부분 episodic 한 경우만 다루겠지만, 손쉽게 continuing / infinite horizon인 경우로 연장시킬 수 있다.

그리고 알아둘 점이 하나 있는데, 바로 policy based RL은 "optimization" 문제라는 것이다.
즉, 최대의 Vπθ를 갖는 parameter θ를 구해야 한다는 것이다.
물론 gradient-free한 방식도 사용할 수는 있다. (위 ppt에 나열된 방법)
하지만, 요즘에는 일반적으로 gradient를 사용하는 방식을 자주 사용한다. (강의명도 policy gradient다!)

Gradient-Free 방식을 사용한 예시 중 하나가 바로 위 예시이다.
사람이 걷기 편하게 보조하는 기계를 학습시키는 것인데, 자세한 내용은 다음 유튜브를 참고하기 바란다.
https://www.youtube.com/watch?v=Dkp_xjbRYCo

그리고, 사실 Gradient Free한 방식은 꽤나 잘 먹힌다. 그래서 간단한 baseline으로 자주 사용된다.
어떠한 policy parameterization을 대상으로도 잘 먹히고, 심지어는 미분 불가능한 경우에도 잘 작동하는 방식이다.
또, 병렬화 작업도 매우 쉽게 된다.
하지만, 치명적인 단점이 있는데, 바로 sample-efficient 하지 못하다는 것이다.
즉, 학습하는 데 매우 많은 데이터가 필요하다.

그러니까 Gradient-Free 방식은 이제 저기로 제쳐두고, policy gradient 방식에 대해 알아보자.

그렇다면 Policy Gradient가 그래서 어떻게 작동하는지 설명해보겠다.
우선 V(θ) = Vπθ로 둔다. 그리고 아까 말했다시피, 오늘은 episodic MDP의 경우만을 생각하자.
그러면 Policy Gradient 알고리즘을 사용하여 V(θ)의 local maximum을 찾을 수 있다. (Gradient Descent 사용)
그렇게 θ에 대한 V(θ)의 local maximum을 찾을 때 사용되는 식은 위 ppt에서 볼 수 있다.
이 떄, 언제나 그래왔듯 α는 learning rate이다.

그래서 이제 Gradient 계산을 해야 하는데...
필자는 아직 고등학생인지라 수학에 대해 아직 좀 많이 무지하다.
Finite Difference가 뭔뜻인지 (한정된 차이?는 아니지 않겠는가;;) 인터넷에 검색해 보니까, "유한 차분법" 이라는 방법이라고 한다.
그래서 이번 슬라이드는 완벽하게 이해하지 못했다.
그래도 이해한 것이라도 끄적여보자면,
우선 닫힌 공간 [1, n]의 있는 모든 k에 대하여, θ에 대한 k의 편미분을 계산한다.
그리고 그 편미분 값을 조금 바꿔서(약간 증가시키거나 감소시킨다는 얘기인가?) 실제 미분값에 근사시킨다.
그 뒤, n dimension을 따라 n번 evaluate해서 policy gradient를 계산한다.
이 방식은 간단(??)하지만, 약간 노이즈가 있고 inefficient한 방식이다. 하지만, 가끔 효율적으로 사용되는데,
미분 불가능한 policy를 포함해 어떠한 policy에도 작동할 수 있기 때문이다.

이 방식을 사용하여, 로봇 AIBO를 걷게 시킨 실험도 있다. (2004년)

어떻게 parameterization을 했는가 보니,
state를 두지 않고, 위 슬라이드에 나온 대로 parameterization을 진행하여, 각각의 파라미터에서 랜덤으로 -ε, 0, ε 셋 중 하나를 더해 policy를 얻었다고 한다.

그런데 위에서 이거 2004년에 했다고 했는데, 이걸 어떻게 computational effecient 하게 진행했냐면,
우선 로봇 3개를 한번에 구동한다.
그리고 각각 iteration마다 policy 15개를 evaluate한다.
그리고, 각각의 policy도 3번씩 evaluate하고 (noise를 줄이려고) 그것의 평균을 구한다.
이렇게 했더니, 각 iteration이 7.5분 안에 끝났다고 한다.
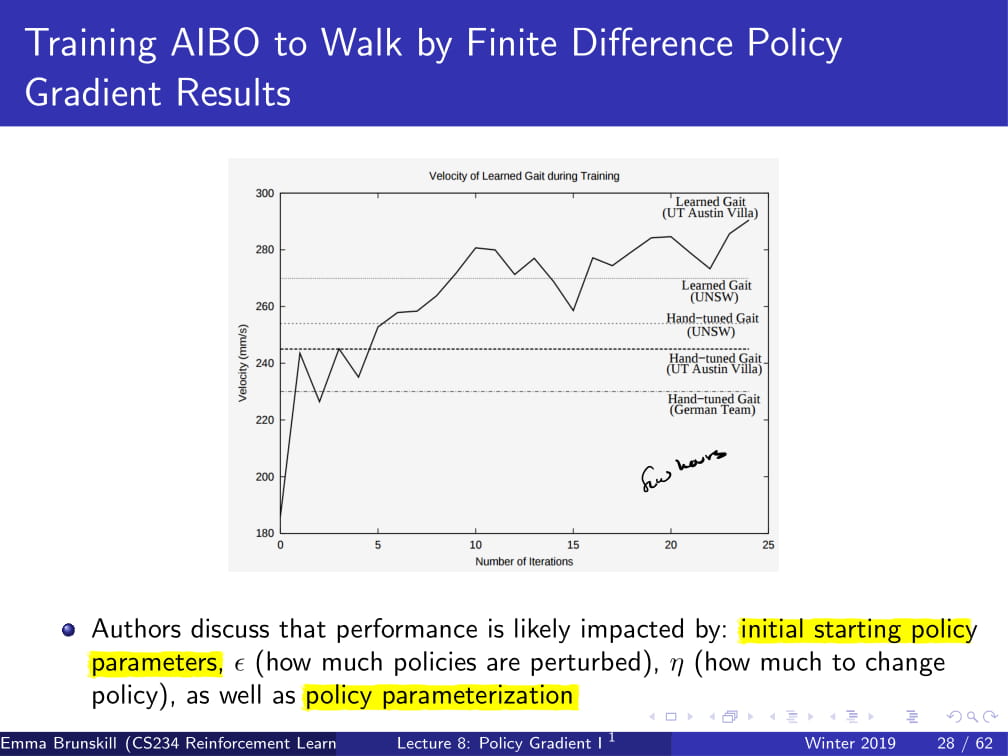
그렇게 traning 시켰더니, 꽤 잘 하는 모습을 보여줬다고 한다.
그리고 이 AIBO의 성능은 초기 starting policy parameter, ε (더하고 빼지던 정도), α (learning rate), 그리고 policy parameterization 등이 영향을 미쳤다고 한다.

그리고, 이번에는 방금의 Finite Difference 방식이 아니라 그냥 analytical 하게 gradient를 구하는 방법을 알아보자.
당연하게도, 이 방식을 사용하려면 policy πθ가 미분 가능해야 하고, gradient를 알고있다고 가정해야 한다.
(즉, 이것 자체가 연산 가능하다는 것을 알고 있어야 한다는 것이다.)

그리고 이 방식을 사용할 때는, likelihood ratio policy라는 것을 사용한다.
우선, 이 방식은 Episodic 한 방식에서만 사용되며, 예전부터 해왔듯이 trajectory를 설정한다.
(당연히 episodic이므로 마지막에 Terminal이 있어야 한다.)
그리고, Reward function R은 그냥 trajectory의 reward값의 평균이다.
또한, 이렇게 두면 Policy value는 해당 policy를 따랐을 때의 Reward값의 평균이 되는데, 이를 다시 쓰면 해당 episode에서, 즉 trajectory를 따라갈 때 얻는 Reward R과 확률 P의 곱의 평균이다.
(policy에서 확률이 왜 나오냐 할 수도 있겠지만, 이제는 이것이 deterministic하지 않는다는 것을 알아야 한다!)
그리고, 이제부터 나오는 대부분의 수식들에는 Reward Function이 그대로 쓰이기 보단, 위의 형태와 같이 Probability P와 R의 곱 형태로 나오게 될 것이다.

그리고 이 상태에서, 위 V(θ)의 Policy Gradient를 구하면 (θ에 대해 Gradient한다), 위와 같게 된다.
딱히 설명할 필요는 없겠지만 대충이라도 설명을 해 보자면,
첫 번째 줄에는 그냥 양변에 gradient를 씌워 준 것이고, (이 표현이 맞는지는 모르겠지만... 뭔뜻인지 알겠지??)
어차피 θ를 인수로 갖는 것은 P(𝛾;θ) 뿐이니 저 시그마 안으로 들어가 준 다음에,
P(𝛾;θ)/P(𝛾;θ) 를 곱해준다. (1을 곱한 것과 같다.)
그리고, P(𝛾;θ)를 분수 아래로, ∇θP(𝛾;θ)를 분수 위로 올리면, P(𝛾;θ)R(𝛾) * ∇θP(𝛾;θ)/P(𝛾;θ)가 된다.
그런데, ∇θlog(P(𝛾;θ)) 는 1/P(𝛾;θ) * ∇θP(𝛾;θ)라고 한다.(왠지는 필자도 잘 모르겠다 ㅠㅠㅠ)
그래서 이를 정리하면, 맨 아래 식이 나온다.
이 식을 사용하는 이유는, policy를 사용하여 trajectory 몇 개를 sampling 한 뒤에, reward를 조금 구하면서 Gradient를 구할 수 있기 때문이다.
즉, 어떻게 Gradient를 구해야 할지에 대한 방법을 얻게 된 것이다.

어떻게 Gradient를 구하는지 조금만 더 자세히 보자면,
우리의 목적은 policy parameters θ를 찾는 것이므로,
θ에 대해 Gradient를 아까 위에서 한 것처럼 구한 뒤에,
그 값을 그냥 policy 몇 번 돌려서 구한 값과 유사한 값으로 맞춰주면 되는 것이다.

...그런데 우리가 지금 뭘 하고 있는걸까?
그냥 일반적으로 Gradient Descent를 사용하는 다른 알고리즘을 생각하면 편하다.
우리는 지금, Gradient를 구하는 방법을 알게 되었다.
그런데 우리의 trajectory는 Policy Parameter θ에 따라 달라지지 않겠는가!
그러므로, 현재 parameter가 가지는 reward값이 가장 커지도록 parameter값을 바꿔준다고 생각하면 된다.
조금 더 자세히 하자면, 그 sample이 얼마나 좋은지에 비례해서 그 sample이 나오게 만드는 확률을 높여주는 방향으로 진행된다.
현재 trajectory의 state에서 앞으로 가는 것이 가장 reward가 높은 행동이라면, 앞으로 가는 확률(로그가 씌워져 있긴 하지만)을 높이는 방향으로 parameter를 움직인다.

조금 더 직관적으로, 위 그래프를 보자.
f(x)는 Reward Function이고, P(x)는 trajectory이다.
그래서, 좋은 reward를 갖는 trajectory를 갖게 parameter를 조정하게 된다. (위 예시에서는, 아마 가장 오른쪽의 값이 가장 reward가 높은이다.)
그냥 이게 다다. 매우 직관적이지 않은가?

이제 우리가 할 것은, 위 Trajectory를 State와 Action에 대한 식으로 풀어 쓰는 것이다.
일단 위 식에서 Trajectory를 갖는 ∇θlogP(𝛾⁽i⁾;θ) 를 보면, parameter θ를 가질 때, i번째 trajectory의 Log Probaility의 미분값이다.
그런 일단, P(𝛾⁽i⁾;θ) 이 부분만 위의 식 μ(s₀)𝚷πθ(at|st)P(st+1|st, at) 라고 나타낼 수 있다.
왠지 대충만 설명하자면, 결국 P(𝛾⁽i⁾;θ)의 의미는 i번째 trajectory의 Prob을 의미하는데,
현재 policy에서 state가 주어졌을 때 action이 나올 확률에 dynamics model P를 곱해준 뒤에, initial state distribution까지 곱해주면, 결국 같은 것을 의미하는 식이 되는 것이다.
그리고 로그를 다시 안쪽으로 넣어주면, product pi 는 sigma가 되어 이와 같이 쓰일 수 있고,
그런데 이를 또다시 θ에 대해 미분해 주면, 신비로운 일이 잇어난다.
우선 왼쪽의 logμ(s₀)는 θ와 독립적이므로, θ에 대한 편미분을 하면 0이 된다.
오른쪽의 P(st+1|st, at) 또한 θ와 독립적이므로, θ에 대한 편미분값은 0이다.
그러면 결국엔 θ를 갖는 식 하나, 가운데 log(πθ(at|st))만 θ에 대해 편미분해주면 되는, 간단한 현상이 일어난다.
그래서 결국 마지막 식이 도출되게 된다.
근데 우리가 왜 이 짓을 했을까?
첫 번째 식과 마지막 결과식을 비교해 보자.
첫 번째 식에는 trajectory가 포함되어 있으므로, dynamics model이 무조건 필요하게 된다.
그런데, 이렇게 trajectory를 state와 action에 대한 식으로 바꿔 주니, dynamics model이 더 이상 필요하지 않다.
그냥 단순한 policy의 logprob값의 편미분값으로만 위 식이 표현이 되는 것이다!

그리고 우리는 위 식을, Score Function이라고 부르게 된다.

이제 지금까지 나온 내용을 다시 뭉쳐보자면 위와 같다.
우리는 좋은 parameter θ를 찾고자 한 것이다.
그리고, V(θ)의 편미분값은 사실 위 (1/m)Σ(i=1 ~ m)R(𝛾(i))∇θlog(P(𝛾(i); θ))이다.
또, 아까 전에 저 P(𝛾(i); θ)을 풀어 쓴 대로 써보면, (1/m)Σ(i=1 ~ m)R(𝛾(i))∇θlog(πθ(at|st))가 된다!
위 식을 조금만 풀어서 쓰자면, trajectory를 m번씩 돌 때, 각각의 trajectory에서 나온 Reward값의 평균에다가,
∇θlog(πθ(at|st))를 곱한 식이 된다.
즉, ∇θlog(πθ(at|st))를 score function으로 갖는 함수가 완성된다. (reward에다가 저 값들만 곱하면 Value값이므로)
또한, 이것도 마찬가지로 dynamics model이 필요없는, 매우 간결한 식이 된다.

그리고, 이 Policy Gradient Theorm은 뒤 식을 약간 일반화 시킨 식이다.
policy objective function J를 J1(episodic reward), JavR(time step당 평균 reward), 1/1-𝛾 * JavV(평균 value)라고 한다면
다음과 같은 식이 써진다. (위 ppt 참조 ㅎㅎ)

그런데, 위와 같은 식은 unbiased하긴 하지만 매우 noisy하다.
대충 딱 보면 monte Carlo 방식이 떠오르지 않는가?
사실상 trajectory의 episodic reward라던지, trajectory의 평균 reward를 갖고 계산한다는 점이 말이다.
그래서, 이러한, 매우 noisy하다는 문제점을 해결하기 위해 여러 가지 방법을 사용한다.
오늘은, Temporal structure과 Baseline에 대해 알아보고, 다음 시간에 추가적인 테크닉들을 설명하겠다.

우선, Temporal Structure는, 말 그대로 우리 model에게 "지금 우리가 하고 있는 것은 temporal 한, 즉 시간적 구조가 나타나는 일이란다" 하고 알려주는 것이다.
이것을 하기 위해서, 위와 같은 공식들이 유도된다.
한번 쭉 읽어보면 딱히 필자가 유도하지 않더라도 어느 정도는 다 이해할 것이라 믿고 넘기겠다.
...사실 필자가 이해하지를 못하겠다 ㅠㅠㅠ
혹시라도 필자를 이해시켜줄 수 있는 용자가 있다면, 댓글로 조언 부탁바란다 ㅠ
(사실 이 강의 설명이 이렇게까지 늦은 이유도, 수식들 하나하나 다 이해하면서 넘어가느라 그랬는데, 여기서부턴 도저시 모르겠다 ㅠㅠ)
다만, 마지막 줄에서 logπθ(at, st)는 logπθ(at|st)의 오타인 것 같다.




위 내용들은 나--중에, 필자가 저 수식들을 이해할 정도의 실력이 되면 그때 다시한번 도전해 보도록 하고,
다음 시간엔 Policy search에 대한 더 많은 이야기들을 해 보도록 하겠다.
그럼... 좀 씁쓸하긴 하지만...
안녕!
'인공지능 > 강화 학습 정리 (CS234)' 카테고리의 다른 글
| 강화학습 강의 (CS234) 7강 - Imitation Learning / Inverse RL (1) | 2019.08.26 |
|---|---|
| 강화학습 강의 (CS234) 6강 - CNN + DQN (Deep Q Network) (0) | 2019.06.06 |
| 강화학습 강의 (CS234) 5강 - Value Function Approximation (4) | 2019.05.27 |
| 강화학습 강의 (CS234) 4강 - MC / SARSA / Q-learning (1) | 2019.05.08 |
| 강화 학습 강의 (CS234) 3강 - Model-Free Policy Evaluation (Monte Carlo / Temporal Difference) (3) | 2019.04.21 |
디미고 입학설명회 후기
저번주 토요일, 그러니까 10월 12일날 입학설명회를 갔다.
내 블로그 게시판을 보면 알겠지만, 당연히 예비 신입생 입장으로 간 건 아니고, 입학설명회 도우미를 하러 갔었다.
금요일날 다른 친구들 죄다 귀가할 때, 친구 몇몇이랑만 학교에 남아서 이런저런 준비를 했다.
몇몇 얘들은 체육관에서 매트깔고 의자놓고, 몇몇 얘들은 기숙사 정리하고 학교 교실 정돈하고,
나랑 몇몇 얘들은 (한 20명정도는 되는 것 같다) 족구장 잡초를 뽑았다.
무슨 족구장에 잡초가 그렇게 나냐고 할 수도 있겠지만, 진짜 잡초가 풍년이더라.
사람이 잡초먹고 살 수 있으면 우리학교 족구장에서 살아도 될 정도였다.
아무튼, 그러고 나서 다음날 뭐할지에 대한 얘기를 듣고, 좀 쉬다 기숙사 들어가서 일찍 잤다. (12시에 ㅎ)
나는 기숙사 앞에서 주차 안내를 맡게 되었는데, 사실상 선생님이랑 친구랑 해서 3명 (좀 사람 몰릴때는 5명)이나 있어서 주차안내라기 보단 그냥 지나다니시는 분들께 인사나 드리면서 학교에 대한 이런저런 얘기나 한 것 같다.
(아마 입학설명회 오신 분들은 웬만하면 절 보지 않았을까.. ㅎㅎ)
아무튼 주차안내를 하고 있는데, 입학설명회 두시간 전쯤부터 차가 한둘씩 들어오다가, 한시간 전쯤부터는 꽤 들어왔고, 한 30분쯤 남으니까 차가 무슨 쭉쭉 들어오는게 솔직히 좀 놀랐다.
(여기서 꿀팁 : 최소한 30분 전쯤에는 와야지 그나마 가까운 곳에 주차할 수 있다. 거기다가 입학설명회 전에는 학교도 둘러보고 기숙사도 둘러볼 시간이 있으니 꼭 30분 전에는 오면 좋겠다.)
들어오는 사람들을 보면서, 학교 안에서는 학교를 욕할지라도, 분명 들어오고 싶어 하는 사람들이 많은 학교라는 것을 실감케 되었다.
그와 동시에, 조금 안타깝다는 생각도 했다.
저렇게 우리 학교에 들어오고 싶어 하는 사람들 중, 여기 오는 사람들만 입학 원서를 낸다 하더라도 반은 떨어지는 것이 아닌가, 하고 말이다.
물론 입학설명회에 온다고 해서 다 입학원서를 내는 것도 아닐거고, 입학설명회 온 사람들만 입학 원서를 내는 것은 아니겠지만 말이다...
아무튼 그렇게 주차안내도 끝나고 체육관, 그러니까 입학설명회장 안으로 들어갔다.
사실 사람이 그렇게 많지는 않았다. 내가 입학하기 전에 갔던 입학설명회 때보다 사람이 적었을 정도였다.
그 때는 체육관 의자에 사람이 다 차고도 모자라서 체육관 복도에서 서서 들었는데, 이번부터는 매달 입학설명회를 진행해서 사람이 좀 적게 온다고 한다.
친구가 말한 바로는, 약 750명 정도가 입학설명회를 신청했다고 한다. (당연히 학부모 포함이다.)

여담이지만, 1학기때는 3000명이나 왔다고 하던데;;;
750명이 온 이번에도 주차장 자리가 부족해서 쩔쩔맸었는데, 3000명이나 왔으면 얼마나 힘들었을지 ㄷㄷㄷ
1학기때 입학설명회 도우미 안하길 잘 한것 같다 ㅋㅋㅋ
그렇게 입학설명회까지 끝나고 나서, 학교에서 다른 학부모님들과 이런저런 이야기를 했었다.
디미고는 성적이 어때야 들어올 수 있는지, 면접은 어떤지, 생활이 힘들지 않은지 등등...
그렇게 이야기하고 있자니, 뭔가 디미뽕에 찬 느낌이다.
솔직히 객관적으로 그렇게까지 좋은 학교는 아닌게 맞지만, 그래도 이렇개 들어오고 싶어 하는 사람들이 많은 학교에 있구나.. 하는 느낌이었다.
근데 진짜로 솔직히 말하자면, 입학설명회는 그렇게 중요하지는 않다.
까놓고 말해서 웬만한 정보들은 책자에 다 있는데다가, 모르는 정보가 있더라도 카톡으로, 또는 전화로 문의하면 되니깐...
사실 입학설명회는 그냥 학교를 한번 둘러본다는 느낌으로 왔으면 한다.
어차피 입학설명회 들어도 올 사람은 다 오고, 떨어질 사람은 다 떨어지니깐...
아무튼, 결론은 이렇다.
생각보다 디미고를 오고 싶어 하는 사람은 실제로도 많구나.
그리고, 디미고 관련해서 잘못된 정보를 가진 사람들도 더러 있구나. (학부모님들과 이야기하다 보면 가끔씩...)
그러니까, 디미고 관련 글들도 조금은 더 쓰면 좋겠구나... 하고 생각했다.
사실 최근 시험보느라, 대회준비도 하느라 이것저것 바빠서 블로그 글을 잘 못썼으니깐.
저번에 쓰기로 한 글들부터 좀 쓰려고 한다.
그러니까 이번 기회에 다음 글들을 먼저 예고하겠다!
Coming Soon : 면접 관련, 입학 관련, 대입 관련 이야기들
ps) 그나저나, "디미고 일상"으로 검색하면 네이버 외부 사이트 탭에 내 글이 가장 먼저 뜨는 것을 봤다.
물론 네이버 블로그 글들에 가려져서 조금 아래 보이긴 하지만, 그래도 감동이다 ㅠㅠㅠ
ps2) 면접 질문 뭔지 말하겠다는 거 아닙니다 ㅠㅠㅠㅠㅠㅠㅠㅠ
'일상 > 디미고' 카테고리의 다른 글
| 디미고, 3년을 돌아보며 - Intro (4) | 2021.01.31 |
|---|---|
| 디미고 진학 관련 이야기들 - 디미고 커트라인, 디미고 면접 등 (330) | 2019.11.04 |
| 디미고 시험기간 - 최대 헬게이트, 고2 1학기 기말 (11) | 2019.06.29 |
| 디미고 일상? - 노트북 편 (8) | 2019.04.24 |
| 디미고 일상 - 기숙사 밤 편 (3) | 2019.04.23 |
openAi gym CarRacing 훈련 중간결과
- 훈련 environment : CarRacing-v1 (https://github.com/NotAnyMike/gym)
NotAnyMike/gym
An improvement of CarRacing-v0 from OpenAI Gym in order to make the environment complex enough for Hierarchical Reinforcement Learning - NotAnyMike/gym
github.com
https://notanymike.github.io/Solving-CarRacing/
Solving CarRacing with PPO - Mike.W
Solving Car Racing with Proximal Policy Optimisation I write this because I notice a significant lack of information regarding CarRacing environment. I also have expanded the environment to welcome more complex scenarios (see more). My intention is to publ
notanymike.github.io
위 링크를 참고하여 제작했습니다.
Proximal Policy Optimization (줄여서 PPO) 알고리즘을 사용하여 훈련하였습니다.
timestep 100만회 colab에서 훈련시켰고, 어느 정도 쓸만한 결과가 나왔습니다!


이렇게 좋은 모습들을 보이기도 하는 반면,
어디서 막혔는지;;; 가끔 보면 이상한 장면들도 나오곤 합니다.

너무 굴곡이 깊거나 하면 그냥 그대로 탈선해서 돌아오려고 하지도 않는 모습을 보이기도 하고,

????????
이해할수도 없이 그냥 멈춰있기도 하고;;;

갑자기 Agent가 술마셨는지 시작하자마자 어기적대면서 그대로 풀로 들어가서 주차하기도 하고;;;
한 천만번 정도는 돌린 다음에 하면 거의 완벽하게 되지 않을까 싶습니다.
'인공지능 > 실습 자료' 카테고리의 다른 글
| Q-learning w/ e-greedy policy (FrozenLake / Taxi) 코드 (0) | 2019.05.13 |
|---|
강화학습 강의 (CS234) 7강 - Imitation Learning / Inverse RL

- 본 포스팅은 CS234 7강의 내용을 정리합니다.
* 강의 앞부분에 DQN을 정리하는 부분이 있는데, 그 부분은 그냥 빼고 설명하겠습니다.

오늘 배울 것들로는,
Behavioral Cloning, Inverse Reinforcement Learning, Apprenticeship Learning 등이 있습니다.

지금까지 우리는 Optimization과 Generalization에 대해서 배웠었다.
어떻게 최적의 policy를 찾아가는지, 그리고 어떻게 그것을 일반화 시킬지에 대한 이야기를 많이 했었는데,
이번에 볼 것은 바로 Efficiency, 즉 효율성이다.
컴퓨팅 파워를 많이 사용하지 않고 최적의 policy를 찾는 방법에 대해서 알아볼 것이다.

일반적인 MDP에서는, 좋은 policy를 찾기 위해서는 굉장히 많은 양의 sample들이 필요했다.
가령 DQN같은 경우, 굉장히 오랫동안 훈련시켜야, 즉 최대한 많은 양의 sample들이 있어야 좋은 성적을 낼 수 있었다.
그런데, 실제 강화 학습의 경우 이런 sample들을 얻기란 쉽지 않다.
만약 우리가 우주선을 발사하는 강화학습 Agent를 만들어야 한다면 어떨까?
수없이 많은 우주선 발사를 실패해야만 진짜 제대로 된 우주선 발사를 볼 수 있을 것이다.
그렇게 되면 천문학적인 비용이 깨지게 될 것이므로, 사실상 이런 방식의 RL로는 우주선 발사는 택도 없다는 것을 알 수 있다.
자율주행 자동차도 비슷하다. 스스로 운전하는 자동차를 만들어야 하는데, 수없이 많은 사고 이후에야 운전을 제대로 할 수 있다면, 아무도 그 비용을 감수하지 않으려고 할 것이다.
그렇다면, sample의 갯수를 줄일 수 있지 않을까?
그냥 아무것도 알려주지 않은 상태로 Optimal policy를 얻기를 기대하기 보다는,
이 강화 학습 과정을 도와줄 추가적인 정보나 구조들을 알려준 뒤에 훈련시키면 되지 않을까?
오늘은 이 아이디어를 Imitation Learning을 통해 살펴보자.

지금까지 우리들은 Reward를 통해서 Agent를 학습시켰었다.
DQN, Q-learning, MC 등등 모두 다 reward function을 사용하여 최대의 reward를 얻을 수 있도록 하는 것이 주요 포인트였다.
이 방식은 매우 간단한 방식으로 훈련이 가능하다는 점에서 좋지만, 아까 위에서 언급했듯 너무 많은 sample을 요구한다는 단점이 있다.
이는 데이터를 얻기 쉬운 가상의 환경 (시뮬레이터 등)이라면 큰 문제가 안되겠지만, 아까 위에서 말했던 우주선이나 자율주행 자동차같은 예시의 경우에는 이런 방식은 올바르지 못할 수 있다.

그리고, reward를 산정하는 방식도 조금 생각을 해 보자.
가령 자율 주행 자동차의 reward를 산정하려면 어떻게 해야할까?
만약 이 reward를 사고날 때 -10, 안나면 +0.1 이런 식으로 두면 어떨까?
그러면 아마 이 Agent는 어떻게 해야 사고가 나고 어떻게 해야 사고가 나지 않을지 알아내느라 한참을 고생할 것이다.
그러면 모든 상황에 대해서 적절한 reward를 대입해주면 어떨까?
우선 이 방식은 너무 오랜 시간이 걸리기도 하고 (초마다 reward를 넣어준다고 해도 1시간동안 운전한다면...),
이렇게 reward를 정해준다고 해도 reward의 상태가 매우 불안정해질 수 있다.
이를 보완하기 위한 대안책으로는, 바로 reward를 demonstration, 즉 실제로 어떻게 하는지 보여주면서 reward를 implicit하게 주는 것이다.

이렇게 demonstration으로 reward를 산정하려면 어떻게 해야할까?
바로 학습시킬 일의 전문가를 데려와서 demonstration trajectory를 만들어 학습시키는 것이다.
가령 자율 주행 자동차를 만든다고 한다면, 운전을 매우 잘하는 어떤 사람을 데려와서 실제로 한번 운전시켜 보는 것이다.
그렇게 얻은 State/action sequence들을 강화 학습 Agent에게 줌으로써 그것을 바탕으로 학습시키면 된다.
이 Imitation learning 방식은 reward를 일일히 부여하거나 특정 policy를 따르도록 하게 하려는 것이 아닐 경우에 효율적이다.

이제 Imitation learning의 기본적인 setting에 대해 설명해 보겠다.
우선, Input은 지금까지와 비슷하게 State space와 action space로 이루어져 있고, Transition model P가 주어진다.
다른 점은, reward function R은 주어지지 않는다. 그 대신, (s0, a0, s1, a1, ....) 과 같은 demonstration을 주어준다.
(위에서 설명했던 것과 비슷하다.)
이제부터 Behavioral Cloning, Inverse RL, Apprenticeship learning에 대해 배울 것인데, 각 종류에 대한 목표 과제는 다음과 같다.
Behavioral Cloning : supervised learning을 통해 스승(전문가)의 policy를 직접 배울 수 있게 하자!
Inverse RL : reward function R을 demonstration을 통해 얻을 수 있을까?
Apprenticeship learning : R값을 좋은 policy를 생성하는데 사용할 수 있나?
이제부터 Behavioral Cloning부터 차근차근 알아가 보자.

Behavioral Cloning 방식은 이 강화 학습 문제를 기존의 머신 러닝 문제를 푸는 방식대로 생각하는 것이다.
즉, 원래 자주 사용하던 Supervised learning 방식을 사용하자는 것이다.
우선 policy class를 설정해 두고, (인공 신경망, decision tree 등등을 사용할 수 있다.)
expert의 state와 action의 sequence를 supervised learning model의 input/output으로 두고 Agent를 학습시킨다.
자율 주행 자동차를 예시로 들자면, 만약 왼쪽으로 코너를 돌 때의 action이 대부분 핸들을 왼쪽으로 꺾는 것이라면,
supervised learning model은 다음부터 왼쪽으로 돌아야 한다는 state를 받을 때 action은 핸들을 왼쪽으로 꺾어야 한다고 학습할 것이다.

하지만, 이 Behavioral Cloning 방식에는 큰 문제가 하나 있다.
Compounding Error (직역하면 합성되는 에러..?)라는 문제점이 바로 그것이다.
이는 Supervised learning은 모든 데이터가 iid라는 것을 전제로 한다는 것 때문에 발생한다.
여기서 iid란 각각의 데이터들이 독립적이고 동일한 확률분포를 가진다는 것을 의미하는데, 조금 더 쉽게 하자면 그냥 모든 데이터 아무거나 하나를 뽑아도 다른 데이터와 연관이 없다는 것을 전제한다는 것이다.
(그래서 Supervised learning에서는 데이터가 어떻게 주어지든 그 데이터의 순서를 마구 섞어서 input으로 집어넣어도 된다.)
그런데, 분명 우리가 주는 데이터 state, action pair은 시간의 흐름에 따라 이어지는 데이터이다.
즉, (s0, a0, s1, a1, s2, a2, ...)라는 데이터에서 분명 s0이 s1보다 먼저, s1이 s2보다 먼저 있는 state라는 것이다.
하지만 Supervised learning에서는 이러한 데이터의 시간적 구조를 싸그리 무시하고, 모든 데이터를 iid라고 가정하기 때문에,
언제 어떤 state였는지는 중요하지 않고, 그냥 특정 state에서 특정 action이 취해지길 바라고 있는 것이다.
자율 주행 자동차의 예를 다시 한번 들어보자.
사람의 경우, 고속도로를 달리는 중 휴게소가 가고 싶다면 휴게소 쪽으로 차선을 옮기게 될 것이다.
어떤 특정 state와는 관계 없이 (휴게소가 아주 가까이 있지 않더라도) 휴게소 쪽으로 차선을 옮기는 것이다.
하지만 Supervised learning 기법으로 학습한다면, 어떤 상황에 왜 차선을 변경하는지는 알지 못하고, "아, 저 state에서는 차선을 바꿔야겠구나!" 생각하고 action을 선택하게 된다.
이런 것들이 하나 둘씩 쌓이다 보면, error가 굉장히 커지게 된다.

또 다른 예를 들어보자.
위 사진에서 보면, Expert가 운전한 대로 Agent가 운전을 하고 있다가, 특정 구간에서의 Error로 인해 코너링 초반에 실수를 조금 했다. (조금 더 바깥쪽으로 코너링을 시도했다.)
하지만, expert는 그런 실수를 하지 않았기에, (그리고 하지도 않을 것이기에,) 저런 상황에서 어떻게 복구해야 하는지 알 길이 없다.
그러면 time step t에서의 실수 하나로 인해 그 이후의 time step t+1, t+2에서도 계속 error가 생길 수 밖에 없고,
그러다 보면 결국 학습에 실패하게 되는 것이다.

이 문제를 해결하기 위해 DAGGER : Dataset Aggregation이라는 방식을 사용한다.
아이디어는 놀라우리만큼 간단하다.
그냥 잘못된 길을 가는 경우 expert에게 어떤 action을 취해야 할지 알려달라고 하는 것이다.
그러니까 코너링을 잘못 돌았을 때, expert에게 "이런 경우엔 어떻게 해야되요?" 라고 물어보고,
expert는 "이렇게 코너링을 돌아야 한단다 ㅎㅎ" 라고 알려주는 것이다.
아이디어만 들어도 알겠지만, 이 방식은 모든 상황에서 효율적으로 쓰일 수 있는 방식은 아니다.
우선, 정말 짧은 time step 간의 state에 대한 action이 필요한 경우에는 사실상 이러한 방식이 불가능하다.
자율 주행 자동차 같은 경우, 정말 짧은 시간동안 어떻게 운전할지가 중요한데, 이런 경우에는 모든 잘못된 경우마다 어떻게 해야 하는지 알려주는 것은 힘들 것이다.
그러나, 만약 그렇게 디테일한 정보까지는 필요 없고 간단한 정보만 필요한 경우에는 사용할 만한 가치가 있을 것이다.
가령, 예시가 간단한 Frozen lake같은 게임을 플레이 하는 것이라면, 굉장히 사용할 만 할 것이다.
오목같은 경우에도, 조금 힘들긴 하겠지만 어떻게든 사용해 먹을 수는 있을 것이다.
그런데 사실 일반적인 경우에는 쓰기 힘들다는 것을 알 수 있다. GPU로 훈련하는 중에 action을 어떻게 효율적으로 집어 넣어줄 것인가?
수시간, 길게는 수십시간 동안의 훈련 시간동안 expert가 컴퓨터 앞에 쭉 앉아 있을 수도 없고 말이다.
그런 단점들 때문에, 후술할 다른 방식들 보다는 이 쪽 업계에 미친 영향이 조금 적다고 한다.

다음으로 알아볼 방식은 Inverse RL이라는 방식이다.

이 방식은 (위에서 짤막하게 설명했듯이) expert의 (위 슬라이드에서는 teacher라고 명명한다.) policy를 보고, reward function을 찾아나가는 방식이다.
아까 전에 설명한 것이지만 다시 세팅을 알려주자면,
state space, action space, transition model P가 주어지지만, reward function R은 주어지지 않는다.
그 대신, teacher의 demonstration (s0, a0, s1, a1 ...)을 받게 된다.
이제 이 Inverse RL은 reward function R을 teacher의 demonstration을 통해 알아가게 된다.
여기서 간단하게 질문 하나를 해보자.
만약 teacher의 policy가 optimal하다는 전제가 없다면, 위 demonstration은 R에 대한 어떤 정보를 줄 수 있을까?
정답은, 간단하게 "줄 수 없다" 이다.
그냥 간단하게, teacher의 policy가 말짱 꽝이라고 해보자. 자율주행 자동차의 경우, 그냥 직진만 한다고 해보자.
그러면, 이 teacher가 운전하는 모습을 보고 운전을 처음 하는 사람이 뭔가를 배울 수 있을까?
뭐가 좋은 것이고 뭐가 나쁜 것인지 알 수 있을까?
당연하게도 알 수 없다.
즉, 우리가 이 Inverse RL 방식을 사용하려면 teacher의 policy는 optimal하다는 전제가 있어야 한다.
(아니, 그래도 teacher의 policy가 어느 정도 이성적으로 판단한 거 아닌가? 라고 생각할 수도 있겠지만, 그런거 베재하고 생각하는 것이다.)
그렇다면, teacher의 policy가 optimal하다고 가정했을 때 reward function은 unique할까, 아니면 여러 개가 있을 수 있을까?
(단, 데이터는 충분히 존재한다고 가정한다.)
정답은, 여러 개가 존재할 수 있다 이다.
이유는 간단하다. 그냥 모든 reward에다가 0을 던져버리면, 어떤 optimal policy가 있더라도 모두 다 동일한 reward를 가지게 될 것이다.
비단 0이 아니더라도 모든 action에 따른 reward를 1, 2, 3과 같은 동일한 상수값을 던져주게 되면, 어떤 policy라도 optimal하게 된다.
조금 더 쉽게 설명해 보겠다.
만약, 선생님이 당신에게 C언어에서 출력을 어떻게 하는지 알려주고 있다고 해보자.
printf("%d",a+b); 라는 코드를 짜 줄수도 있고,
printf("%c",a); 라는 코드를 짜 줄수도 있을 것이다.
그러면 일반적인 상식적으로, 우리는 저 앞의 printf("% 부분의 reward는 높을 것이고, 또 맨 뒤에 );의 reward도 높을 것이라고 예측할 수 있다.
그런데 만약 위 두 case의 각각의 철자마다 그냥 reward가 0이라고 해버린다면 어떨까?
그러니까, 선생님이 어떤 코드를 짜던지간에, "아몰라 저거 다 reward 0이라고 하면 되는거잖아? 그러면 내가 뭔 코드를 짜던지 간에 내 코드도 optimal policy로 짜지는 코드인데??" 라고 할 수 있다는 것이다.
즉, printf에 가중치가 부여되는 것이 아니라, 그냥 drqctz나 printf나 똑같은 reward를 갖게 되는 것이다.
그런데 당연히 이것을 의도하고 코딩하는 법을 가르쳐 준 것이 아니지 않겠는가!
이런 점에서, 이 Inverse RL은 큰 문제에 봉착하게 되었다.

그렇다면 이 Inverse RL의 문제를 어떻게 해결할까?
우선 저번에 배웠던 Linear value function approximation을 다시 가져와 보자.
R값은 여러 개가 존재할 수도 있다고 했지만, 그냥 일단 R값을 wT x(s)라고 둬보자.
(이 때, w는 weight vector이고 x(s)는 state의 feature이다.)
그래서, 이 weight vector w를 주어진 demonstration을 통해 찾아내는 것이 목표이다.
우선, policy π에 대한 Vπ값을 E[Σt=0-->∞ 𝛾^t*R(sₜ)|π] 라고 할 수 있다.
(즉, Reward의 discounted sum이다. 수식을 예쁘게 쓰고 싶은데 수식 편집기가 없어서 ㅠㅠ 위 슬라이드를 보며 이해하면 좋겠다.)
이것에 위에서 정의한 R(s) = wTx(s)를 대입하면,
E[Σt=0-->∞ 𝛾^t*wT*x(sₜ)|π]라고 할 수 있다.
또, 모든 π에 대하여 wT의 값은 동일하므로, wT값을 앞으로 넘겨서
wT*E[Σt=0-->∞ 𝛾^t*x(sₜ)|π] 라고 할 수도 있다.
그러면 이제 거의 다 끝났다.
E[Σt=0-->∞ 𝛾^t*x(sₜ)|π]의 값을 그냥 μ(π)라는 값으로 두면,
최종적인 Vπ의 값을 wT*μ(π) 라고 할 수 있다.
그런데, 여기서 μ(π)(s)가 의미하는 바가 무엇인가?
(참고로, 뒤에다가 (s)붙인거 오타 아니다. μ(π)는 벡터이므로...)
각각의 time step t에서 나타나는 state feature x(s)에다가 discount factor 𝛾^t를 곱한 것이다.
그리고 거기에다가 w의 transpose를 곱하므로, 이는 각 state feature의 weighted discounted frequency를 나타내는 값과 동일해 진다.
즉, 우리가 학습시킨 weight vector w값에다가 자주 등장하는 state feature의 값을 곱해주는 것이다.
자, 그럼 이 값이 잘 만들어진 값인지 보자!
Inverse RL에서 우리의 목표는 무엇이었는가?
바로 (optimality가 전제된) teacher의 policy를 보고, 그 policy를 토대로 reward function이 어떻게 되어 있을지 찾아가는 것이었다!
그러면, teacher의 policy를 봤을 때 자주 보이는 state feature의 실제 reward 값은 어떨까?
당연하게도, optimality가 전제되어 있으므로, 자주 보이는 state feature를 갖는 state의 reward는 높을 것이다.
비슷하게, 거의 보이지 않았던 state feature를 갖는 state의 reward값은 일반적으로 낮게 될 것이다.
이것도 자율주행 자동차를 생각하면 편할 듯 하다.
왼쪽으로 코너를 돌 때, 차선을 잘 맞춰서 도는 일이 빈번할 것이므로 (optimal한 policy였으므로...) 그러한 state에서는 당연히 높은 reward값을 가질 것이다.
또, 왼쪽으로 코너를 돌 때 웬만하면 왼쪽으로 막 틀어지거나 하는 일은 없을 것이므로, 그 state의 경우는 reward가 낮게 측정되는 것이 일반적이다.
이렇게, 비교적 간단한 수식으로 Inverse RL을 수행할 수 있다.
그리고 이런 방식을 사용하면, 모든 경우에 reward를 0을 던질 일은 없어지므로, 제기되었던 문제를 어느 정도 해결할 수 있게 되었다!

다음 방식은 Apprenticeship Learning이다.

사실 Apprenticeship Learning도 Inverse RL과 굉장히 비슷하다.
방금 전까지 한거 그대로 이어서, 조금 더 잘 만든 버전이라고 생각하면 될 듯 하다.
Vπ = wTμ(π)부분까지는 그냥 동일하다고 보면 된다.
위 ppt 참고해서 보면, V*는 언제나 Vπ보다 크거나 같다. (기억안날까봐 - *는 optimal함을 의미함.)
그러므로, expert의 demonstration이 optimal policy에서 온 것이라면, w를 찾기 위해서는
w*Tμ(π*) >= w*Tμ(π) 를 만족하는 w*를 찾을 필요가 있다.
수식을 해체해서 설명하자면,
μ(π*)는 expert가 주는 optimal한 policy이므로 우리가 이미 알고 있는 값이고,
μ(π)는 expert가 주는 policy를 제외한 다른 어떤 policy를 의미한다.
즉, optimal policy의 값을 정말 optimal하게 만들어주는 w*의 값을 찾아야 한다는 것이다.
(만약 위의 수식을 만족하지 않는다면 reward function R에서 V값이 optimal policy보다 높은 policy가 존재한다는 것인데, 이건 말이 안되지 않는가!)
**설명이 약간 부실한 것 같아서 부연설명하자면... (이미 이해했으면 걸러도 됨)
지금 문제 상황은 우리가 모르는 reward function R값이 있다는 것이다.
분명 expert는 (무의식적으로라도) reward function 값들을 알겠지만, 우리 (Agent)는 그 값을 모르니, 그 값을 찾아가겠다는 것이다.
그런데 expert가 optimal하게 움직인다는 것은, 당연히 그 reward function을 통해 얻을 수 있는 최적의 움직임을 하고 있다는 뜻이다.
그러니 저 위의 수식을 만족하는 w값을 찾을 수 있어야 한다는 것이다.
(이래도 이해 안되면 댓글로 ㅎㅎ..)

그래서 저 수식을 만족하는, 즉 expert policy가 다른 어떤 policy보다 잘 작동하는 reward function을 찾고 싶다는 것이다.
그리고 만약 우리의 policy π와 π*에서의 Value 값이 충분히 비슷하다면, 우리는 π*, 즉 optimal policy 수준의 policy를 찾아냈다고 할 수 있을 것이다.
조금 더 정확히 말하자면, 어떤 ε에 대하여 ||μ(π)-μ(π*)||₁<=ε를 만족하는 π를,
그리고 ||w||∞ <=1을 만족하는 모든 w에서 |wTμ(π) - wTμ(π*)|<=ε을 만족하는 w를 구해야 한다는 것이다.
*참고 : ||X||₁은 L1 norm을, ||X||∞는 L infinity norm을 의미한다. 자세한건 구글링으로 알아보시길...
수식을 또 간단히 하자면 (약간 의역하자면), 모든 state에 대해서 μ(π)의 값과 μ(π*)의 값의 차이가 ε이하이고,
모든 값의 절대값이 1보다 작은 w값에 대해서 wTμ(π)와 wTμ(π)의 차이가 ε이하인 π와 w를 구해야 한다.
(당연히, 여기서 ε은 충분히 작은 값이다.)
(+ w값의 절대값이 1보다 작아야 하는 이유는 훈련 도중에 값이 explode하지 않게 하기 위함인듯 하다.)
이렇게 하면, 원래 reward function이 뭐였느냐에 관계 없이, 학습으로 도출된 reward function을 사용하더라도 충분히 optimal policy에 가까운 policy를 얻어낼 수 있다!

이 부분은 지금까지 위에서 말한 것을 알고리즘으로 나타낸 것이다.
그런데 교수님 말씀으로는 이거 이제 거의 안쓰인다고 설명을 안해주셨다.
사실 이쯤되면 위 ppt 보는것 만으로도 이해가 될 경지에 이르렀다고 생각하겠다 ㅎㅎ
지금까지에서 가장 중요한 것은, optimal policy와 충분히 비슷한 policy를 얻어내는 것만으로도 학습이 충분하다는 것이다.
(실제 optimal policy가 가지던 reward function과 관계없이 어떠한 reward function으로라도 저런 policy만 찾을 수 있으면 된다는 뜻이다.)

하지만 아직 문제점들이 남아 있다.
아까 전에 같은 optimal policy에도 수없이 많은 reward function들이 있을 수 있다고 했는데, 사실 위의 알고리즘이 이 문제를 완벽히 해결하지는 못한다.
또한, reward function을 구했더라도 그 reward function에 최적으로 부합하는 policy도 사실 여러 개가 있을 것이다.
그 중 어떤 것을 골라야 하는가? 가 바로 그 문제점이다.

이런 문제들 같은 경우, 아직도 활발히 연구되고 있다.
주요 논문으로는, Maximum Entropy Inverse RL과 Generative adversarial imitation learning이 있다.
Maximum Entropy Inverse RL의 경우, 말 그대로 Entropy의 값을 최대화시키자는 것인데...
필자도 설명을 들어도 잘 모르겠어서, 구글링을 이리저리 하다가 설명을 매우 잘 해놓은 다른 블로그를 보게 되었다.
https://reinforcement-learning-kr.github.io/2019/02/10/4_maxent/
필자가 아무리 잘 설명해 봤자 이것보단 더 잘 설명할 수 없을 것 같으므로, 그냥 여기 들어가서 보는 것을 추천한다.
간단하게 설명하자면, Imitation learning의 uncertanty를 최소화 하기 위해, (즉, 최악의 선택을 피하기 위해) entropy를 최대화 시켜줘야 한다는 것이다. 최대한 일반적인 움직임만을 선택하자는 느낌이다.
Generative adversarial imitation learning, 줄여서 GAIL의 경우의 아이디어는 GAN과 매우 흡사하다. (이름부터가...)
주요 아이디어는, discriminator (판별자?)를 만들어서, expert policy와 우리가 찾아낸 policy를 구별하게 만드는 것이다.
그렇게 해서 최적의 이 discriminator가 expert policy와 그냥 policy를 구별할 수 없을 정도의 policy를 찾아낸다면, 그것이 바로 충분히 좋은 policy라고 하는 것이다.
이 방식을 사용함으로써, 우리는 통계적 계산의 산물인 μ(π)에서 조금 더 멀어져서, 실제 좋은 움직임을 찾을 수 있을 것이다.

자, 이제 거의 다 왔다! 이제 지금까지 배운 내용을 마무리해보자.
Imitation learning을 사용하면, 다른 방법들을 사용하는 것 보다 좋은 policy를 얻기 위해 필요한 데이터의 양이 매우 적어진다.
그렇기 때문에, 실제 산업 현장에서도 굉장히 practical하게 사용되고 있는 기법 중 하나이다.
특히 로봇쪽에서 굉장히 많이 보이지만, 그것 외에도 굉장히 다양한 분야에서 시도되고 있는 기법이다.
가장 큰 도전 중 하나는, 사실 대부분의 문제에서 우리는 optimal policy가 뭔지 모른다는 것이다.
사실 오늘 강의는 expert의 policy가 언제나 optimal하다는 것을 전제로 해 왔지만, 솔직히 누가 운전하는 optimal한 방법을 알고 있겠는가?
학생을 가장 효율적으로 교육하는 교육 시스템을 만든다고 하면, 대체 누가 가장 효율적인 학습 방법을 알고 있다는 것인가?
그리고, 아직 optimal policy를 모르는 문제들의 경우 어떻게 exploration을 진행하며 좋은 policy를 얻어가야 할까?
이러한 문제들은 Imitation learning, 그리고 강화 학습이 발전하면서 차차 해결해 나가야 할 문제이다.

오랫만에 글을 써서 그런지 힘을 빡 주고 쓴 느낌이다.
원래는 그냥 막 넘길 부분도 조금 자세히 설명하기도 하고, 최대한 이해가 쉽게 노력했다.
(그래서 그런지 글 쓰는데 강의 시청시간 제외 총합 5시간정도 쓴것 같다;;)
(지금 보니까 지금까지 글 쓴것 중에서 가장 길게 쓴 글이다. 호달달;;)
모쪼록 이 정리 포스팅을 보고 강화 학습을 쉽게 배울 수 있었으면 좋겠다.
혹시라도 이해가 잘 되지 않거나, 오타나 잘못된 점들이 있으면 댓글로 남겨주면 좋겠다.
아무튼, 다음 시간에는 Policy Search라는 방식을 알아보도록 하겠다.
'인공지능 > 강화 학습 정리 (CS234)' 카테고리의 다른 글
| 강화학습 강의 (CS234) 8강 - Policy Gradient (1) | 2019.10.22 |
|---|---|
| 강화학습 강의 (CS234) 6강 - CNN + DQN (Deep Q Network) (0) | 2019.06.06 |
| 강화학습 강의 (CS234) 5강 - Value Function Approximation (4) | 2019.05.27 |
| 강화학습 강의 (CS234) 4강 - MC / SARSA / Q-learning (1) | 2019.05.08 |
| 강화 학습 강의 (CS234) 3강 - Model-Free Policy Evaluation (Monte Carlo / Temporal Difference) (3) | 2019.04.21 |